梳理一下关于删除重复记录的逻辑
目录
前期准备:建表插入数据
1、通过group by 和count(1)>1找出有重复的数据
2、通过每个分组中的最小id来去重
2.1、添加主键id列
2.2 去重
2.2.1、首先找出每个分组中count(1) >1的数据中的最小id【min(id)】,sql语句如下:
2.2.2、再将上表和emp表做表连接,sql语句如下:
文章来源地址https://uudwc.com/A/10Yr
前期准备:建表插入数据
-- 创建表格emp
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`EMPNO` int(0) NULL DEFAULT NULL,
`ENAME` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`JOB` varchar(9) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`MGR` int(0) NULL DEFAULT NULL,
`HIREDATE` date NULL DEFAULT NULL,
`SAL` int(0) NULL DEFAULT NULL,
`COMM` int(0) NULL DEFAULT NULL,
`DEPTNO` int(0) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- 插入数据
INSERT INTO `emp` VALUES (7566, '琼斯1', '经理', 7839, '1981-04-02', 2975, NULL, 20);
INSERT INTO `emp` VALUES (7654, '马丁', '售货员', 7698, '1981-09-28', 1250, 1400, 30);
INSERT INTO `emp` VALUES (7782, '克拉克', '经理', 7839, '1981-06-09', 2450, NULL, 10);
INSERT INTO `emp` VALUES (7788, '斯科特', '分析师', 7566, '1987-04-19', 3000, NULL, 20);
INSERT INTO `emp` VALUES (7839, '国王', '总统', NULL, '1981-11-17', 5000, NULL, 10);
INSERT INTO `emp` VALUES (7844, '特纳', '售货员', 7698, '1981-09-08', 1500, 0, 30);
INSERT INTO `emp` VALUES (7876, '亚当斯', '店员', 7788, '1987-05-23', 1100, NULL, 20);
INSERT INTO `emp` VALUES (7900, '詹姆斯', '店员', 7698, '1981-12-03', 950, NULL, 30);
INSERT INTO `emp` VALUES (7902, '福特', '分析师', 7566, '1981-12-03', 3000, NULL, 20);
INSERT INTO `emp` VALUES (7521, '沃德', '售货员', 7698, '1981-02-22', 1250, 500, 30);
INSERT INTO `emp` VALUES (7934, '米勒', '店员', 7782, '1982-01-23', 1300, NULL, 10);
INSERT INTO `emp` VALUES (7499, '艾伦', '售货员', 7698, '1981-02-20', 1600, 300, 30);
INSERT INTO `emp` VALUES (7698, '布莱克', '经理', 7839, '1981-05-01', 2850, NULL, 30);
INSERT INTO `emp` VALUES (7566, '琼斯', '经理', 7839, '1981-04-02', 2975, NULL, 20);
SET FOREIGN_KEY_CHECKS = 1;表格来自oracle自带emp表。
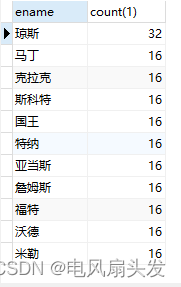
1、通过group by 和count(1)>1找出有重复的数据
SELECT ename,count(1) FROM emp GROUP BY ename HAVING count(1) >1;
在group by 之后 count(1)> 1代表其分组数据是重复的。
具体group by 字段根据实际情况需求添加。
结果如下:
2、通过每个分组中的最小id来去重
2.1、添加主键id列
由于表格没有主键列,所以需要新增id自增。
ALTER TABLE emp add id int first; -- 改变表结构,增加名为id的列
ALTER table emp MODIFY id int PRIMARY key auto_increment; -- 将id字段设置为主键自增;2.2 去重
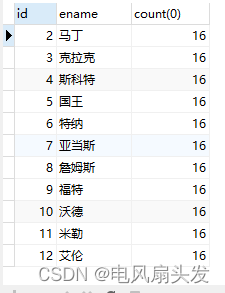
2.2.1、首先找出每个分组中count(1) >1的数据中的最小id【min(id)】,sql语句如下:
SELECT min(id) id,ename,count(0) FROM emp GROUP BY ename HAVING count(1) >1;结果如下:
2.2.2、再将上表和emp表做表连接,sql语句如下:
SELECT t1.*,t2.* from
emp t1
inner join (SELECT min(id) id,ename,count(0) FROM emp GROUP BY ename HAVING count(1) >1) t2
on t1.ENAME = t2.ENAME;结果如下:
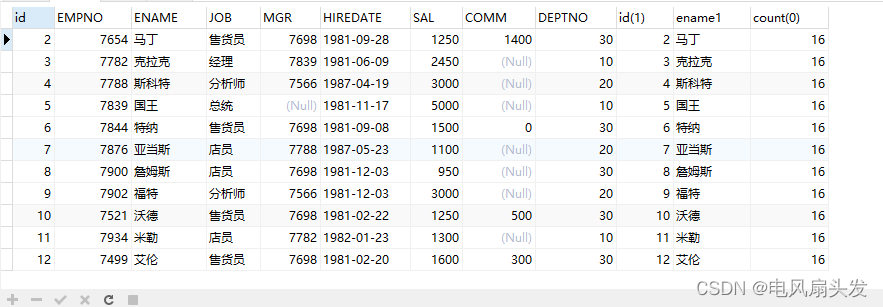
可以看出t1.id和t2.id之间的联系,我们只需要删除t1.id > t2.id的数据,只留下每组中id最小的值和count(1)= 1 的数据。
需要用到MySQL DELETE语句使用INNER JOIN子句,语法如下:
DELETE a FROM table1 AS a LEFT JOIN table2 AS b ON 连接条件 WHERE 过滤条件;完整去重sql语句如下:
DELETE t1 from
emp t1
inner join (SELECT min(id) id,ename,count(0) FROM emp GROUP BY ename HAVING count(1) >1) t2
on t1.ENAME = t2.ENAME
where t1.id > t2.id;文章来源:https://uudwc.com/A/10Yr