一、问题描述
在实际的数据处理过程中,常常会遇到需要将DataFrame中的列转换为行或将行转换为列的情况。但是,如果使用传统的Python方法,这种操作会非常繁琐且容易出错。因此,我们可以使用pandas库提供的优雅方式来完成列转行或行转列的任务。
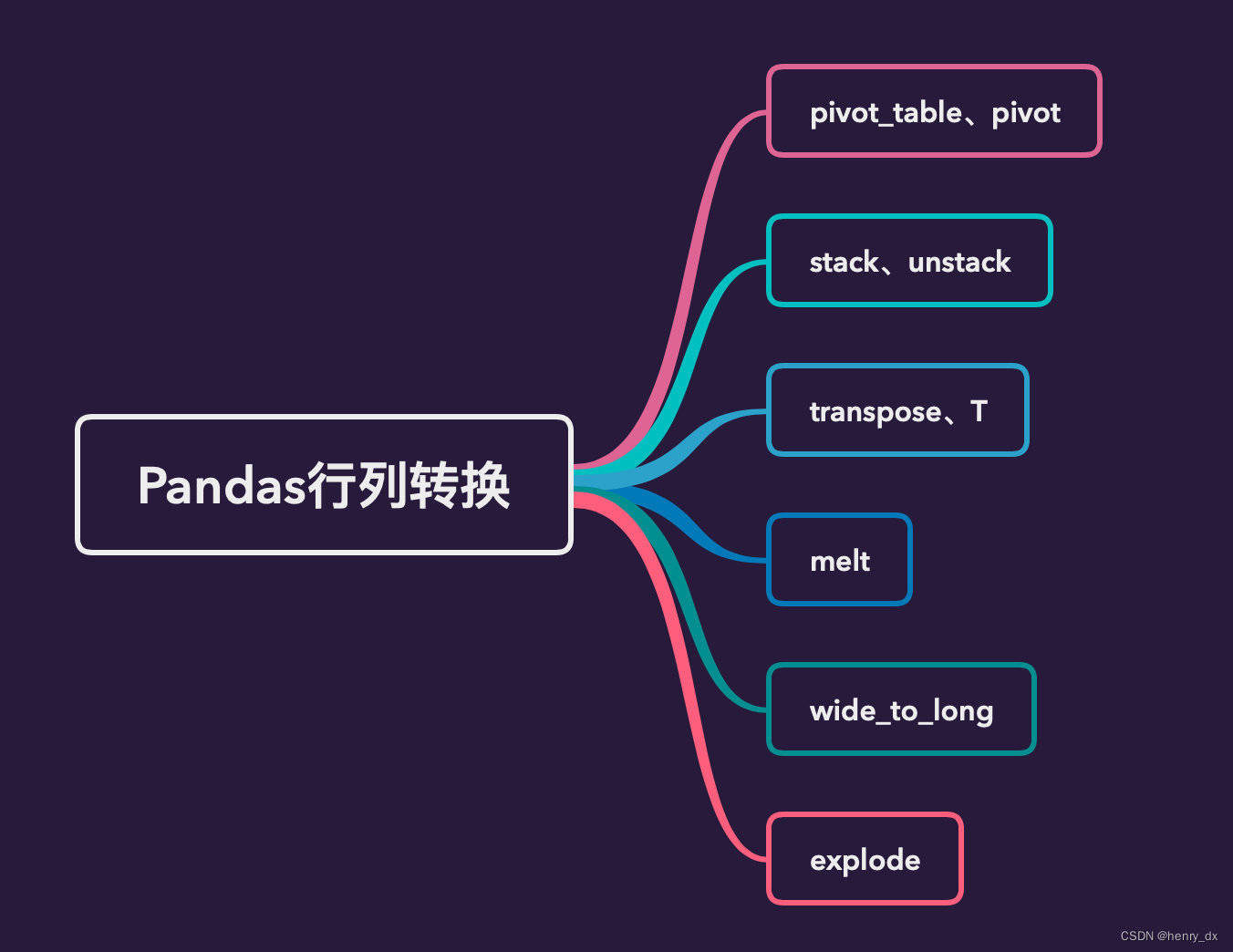
二、列转行
1、函数melt
melt的主要参数:
pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value',ignore_index=True, col_level=None)
下面解释参数的含义:
-
frame:要处理的数据框DataFrame。
-
id_vars:表示不需要被转换的列名
-
value_vars:表示需要转换的列名,如果剩下的列全部都需要进行转换,则不必写
-
var_name和value_name:自定义设置对应的列名,相当于是取新的列名
-
igonore_index:是否忽略原列名,默认是True,就是忽略了原索引名,重新生成0,1,2,3,4…的自然索引
-
col_level:如果列是多层索引列MultiIndex,则使用此参数;这个参数少用
import pandas as pd
# 创建数据集
df = pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'},
'B': {0: 1, 1: 3, 2: 5},
'C': {0: 2, 1: 4, 2: 6}})
# 将ABC三列转换为行
df_melted = pd.melt(df, id_vars=['A'],
value_vars=['B', 'C'],
var_name='variable',
value_name='value')
print(df_melted)
A variable value
0 a B 1
1 b B 3
2 c B 5
3 a C 2
4 b C 4
5 c C 62、使用stack函数
使用stack函数可以将列转换为行。首先,我们需要明确将哪些列转换为行。下面的代码演示了如何将A,B,C三个列转换为行。
该方法利用了set_index和stack函数,其中set_index函数将'A'列作为索引,stack函数将所有的列转换为行,最后用reset_index函数重置索引,并修改列名。
import pandas as pd
# 创建数据集
df = pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'},
'B': {0: 1, 1: 3, 2: 5},
'C': {0: 2, 1: 4, 2: 6}})
# 将ABC三列转换为行
df_stacked = df.set_index('A').stack().reset_index()
df_stacked.columns = ['A', 'variable', 'value']
print(df_stacked)
A variable value
0 a B 1
1 a C 2
2 b B 3
3 b C 4
4 c B 5
5 c C 63、转置函数
pandas中的T属性或者transpose函数就是实现行转列的功能,准确地说就是转置。
4、wide_to_long函数
pandas 中的 wide_to_long() 函数用于将宽格式的数据转换为长格式。宽格式数据通常是指具有多列的数据集,每一列代表不同的变量或特征。而长格式数据则是将这些变量整理到一列中,同时添加一个标识符列来表示原始变量的名称。
wide_to_long(df,stubnames,i,j,sep: str = "",suffix: str = "\\d+"
参数说明:
df:要转换的数据框(DataFrame)。
stubnames:一个字符串或字符串列表,表示要转换的列名的前缀。通常用于指定要堆叠的相关变量。
i:标识符列的名称或位置。可以是字符串或整数,用于表示唯一标识每个观察值的行标签。
j:新生成的列的名称。可以是字符串,用于表示转换后的变量名。
sep:用于分隔 stubnames 和 j 的连接符,默认为空字符串。
suffix:用于标识每个变量的正则表达式。默认为 '\d+',表示一个或多个数字。
5、爆炸函数-explode
explode 函数是 pandas.DataFrame 类的一个方法,它可以将一个包含 list 或者其他可迭代对象的列(column)拆分成多行,然后在所有其他列(non-explode)上进行复制。
explode 函数的原型如下:
DataFrame.explode(
column,
ignore_index=False
) -> Union['DataFrame', 'Series']
参数说明:
column:指定要拆分的列名;
ignore_index:如果为 True,则重置索引。
三、行转列
1、使用pivot函数
使用pivot函数可以将行转换为列。下面的代码演示了如何将A列作为索引,B列和C列中的值分别作为列,将另一个新列的值填充到每个单元格中。
该方法中的参数说明如下:
-
index:指定作为行索引的列名。
-
columns:指定需要转换为列的列名。
-
values:指定用于填充新列的列名。
import pandas as pd
# 创建数据集
df = pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'},
'B': {0: 1, 1: 3, 2: 5},
'C': {0: 2, 1: 4, 2: 6}})
# 将行转换为列
df_pivoted = df.pivot(index='A', columns='B', values='C')
print(df_pivoted)
B 1 3 5
A
a 2.0 NaN NaN
b NaN 4.0 NaN
c NaN NaN 6.02、使用set_index和unstack函数
使用set_index和unstack函数可以将行转换为列。下面的代码演示了如何将A列作为索引,B列和C列中的值分别作为列,将另一个新列的值填充到每个单元格中。
该方法中的set_index函数和unstack函数分别用于设置索引和行列转换。文章来源:https://uudwc.com/A/12gRq
import pandas as pd
# 创建数据集
df = pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'},
'B': {0: 1, 1: 3, 2: 5},
'C': {0: 2, 1: 4, 2: 6}})
# 将行转换为列
df.set_index(['A', 'B'])['C'].unstack()
print(df)
B 1 3 5
A
a 2.0 NaN NaN
b NaN 4.0 NaN
c NaN NaN 6.0文章来源地址https://uudwc.com/A/12gRq