随着集群规模的不断扩大,硬盘数量指数级上升,信创 CPU 和操作系统、硬盘多年老化、物理搬迁等多种复杂因素叠加,为企业的存储亚健康管理增加了新的挑战。
在亚健康 2.0 的基础上,星辰天合在 XSKY SDS V6.2 实现了亚健康 3.0,并推出了亚健康 3.0 工具来实现新集群和老集群同时应对亚健康问题。
问题和挑战
亚健康,又称 Fail slow,描述的是硬件虽然仍能正常运行,但性能大幅下降的一种状态。无论是硬盘、网卡、CPU、内存,这些硬件部件都可能陷入亚健康状态。当这些硬件处于这种状态时,这些硬件仍然能继续运行(不会停止工作),但其性能远不如正常情况。如果存储系统没有有效监控和容错机制,则会导致存储系统响应主机的时延增加、IOPS 和带宽降低,极端情况下甚至可能导致无法响应主机,从而打断主机业务。
在星辰天合的产品理念中,我们需要确保存储系统的可靠性和高可用,同时也强调软硬解藕设计的灵活性。因此,我们持续努力提升产品在硬件亚健康方面的处理能力。在 XSKY SDS V5 版本里就推出了 亚健康 2.0,它能自动检测并隔离亚健康状态的存储盘。但随着集群规模的不断扩大,硬盘数量指数级上升,我们又一步发现了更多亚健康的优化空间,以确保客户业务连续性:
亚健康的场景本身非常复杂,需要针对不同的场景有不同的处理方案,因此我们需要一个足够灵活的亚健康处理框架。例如在某些 RAID 卡固件和版本里,如果一个硬盘发生高延迟且 IO 长期得不到处理,可能会导致 RAID 卡固件重置,进而影响该 RAID 卡下所有硬盘的 IO 处理,最终导致业务性能下降。在这种场景下,我们需要在第一时间内识别并处理首个出现亚健康的硬盘,避免波及系统中的其他硬盘。
亚健康 2.0 是 XSKY SDS 内置能力,这意味着要应对新增的亚健康情况,必须升级整个存储集群版本,这种方式对于给客户带来了诸多不便,尤其是对于生产环境的存储集群,一方面亚健康问题需要不断更新和识别,另一方面存储集群的升级变更流程复杂。因此,我们迫切需要一种更敏捷的方式来推动亚健康新增能力的落地。
为了应对这些挑战,在亚健康 2.0 的基础上,XSKY SDS V6.2 实现了亚健康 3.0,并推出了亚健康 3.0 工具来实现新集群和老集群同时应对亚健康问题。
亚健康能力的版本迭代
我们先回顾星辰天合亚健康检测和隔离功能的历史,从亚健康 1.0 发布以来,逐渐升级功能,在此次发布亚健康 3.0 之后,将会在 2024 年发布亚健康 4.0 版本。
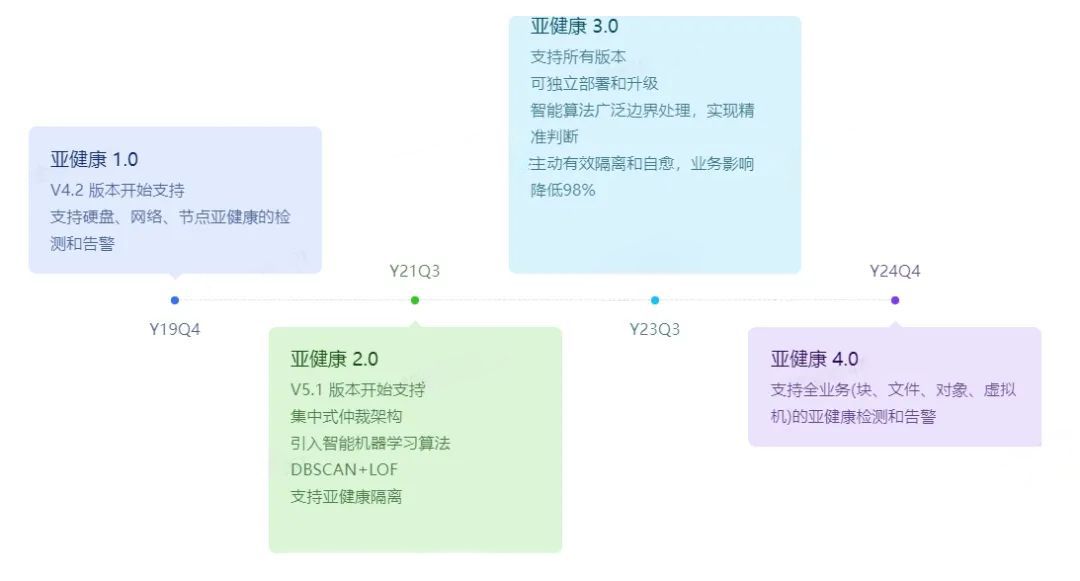
亚健康能力的版本迭代路线图
亚健康 3.0 算法原理
亚健康 3.0 在继承了 2.0 版本的成功经验的基础上,进一步完善了其不足之处。特别是在面对新硬件引入过程产生新的亚健康问题,其核心设计理念是将亚健康处理跟数据 IO 路径进行分离,从而实现外部检测与全局决策的能力。亚健康 3.0 模块负责亚健康场景的识别,但其本身运行和升级可以独立于存储系统本身。
针对于亚健康检测的复杂性和灵活多变的需求,我们的架构设计具备以下特点:
收集硬件关键指标,并对指标进行数学统计和处理,同时设有全局仲裁中心;
检测算法具备自适应性,能够自适应各种不同场景,同时准确性和灵敏度可调整;
隔离策略首先保证数据安全,其次再保证集群的整体性能;
我们的设计支持独立部署,兼容老版本集群。算法库采用可插拔方式,隔离策略要求可配置,保障业务连续性。
下面是亚健康 3.0 的软件架构:
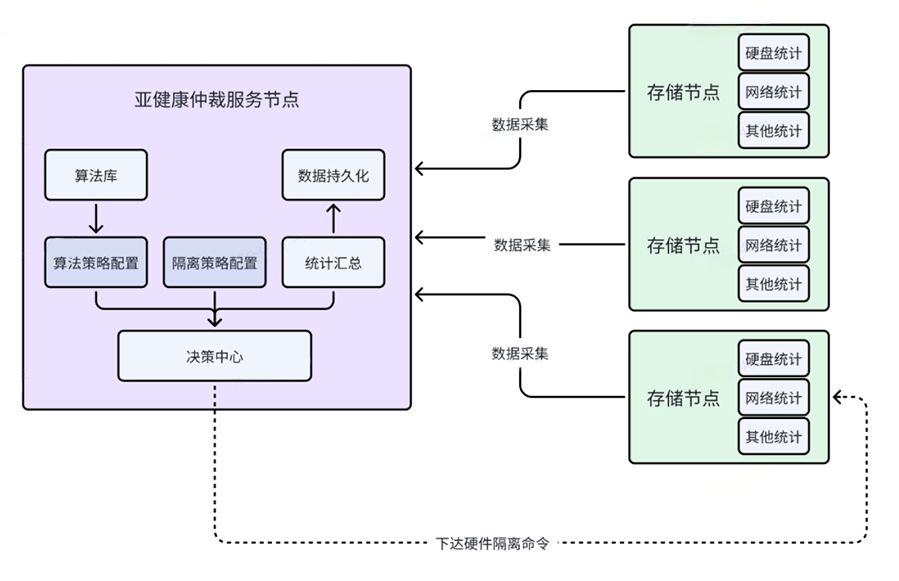
亚健康 3.0 的软件架构
金融万盘规模案例
某金融客户在不同时间里在不同业务场景里部署了大规模 XSKY SDS 集群,期间不断扩容新的硬件。至今,其总硬盘数已超过 10000 块,其中很多硬盘已经持续运行了超过 4 年时间。由于硬盘本身的老化和正常的磨损,亚健康导致的系统性能波动偶尔发生。虽然可以通过升级存储集群版本来解决这些问题,但是由于严格的生产运维要求,对存储集群进行批量的升级动作太大,实施成本较高。因此,该客户采用了亚健康 3.0 工具的独立部署来解决这个问题。在该客户部署亚健康 3.0 工具的首个月中,成功识别出 21 块高风险的亚健康硬盘,且没有出现任何因亚健康检测和隔离导致的集群性能问题。
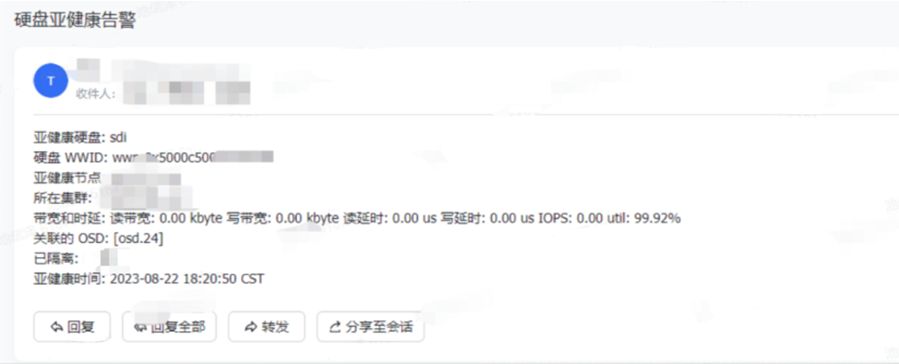
磁盘不能处理任何 IO,读写延时为 0,磁盘利用率达到 99%
在部署一个月内发现的故障硬盘是 21 块,月故障率是 0.21%,推算年化故障率为 2.5%。根据国内外的统计数据,HDD 的年化故障率根据使用的年限、品牌及型号的不同通常分布在 1%-5% 之间,因此 2.5% 的故障率属于在正常范围内。亚健康 3.0 工具从最初支持 SATA SSD、HDD,到后续支持信创 CPU 节点、国产化操作系统、NVME SSD,以及针对不同规格的 RAID 卡等等,几乎完整覆盖了当前各种存储介质和不同运行环境下的情况。
总结
亚健康 3.0 提供了先进的可靠性监测功能,引入创新的数学模型和统计框架,深入分析导致系统性能降级的部件级故障和周边系统故障,不仅能够实时监测网络和硬盘的亚健康状态,还能对故障部分进行主动隔离,从而提高系统的健壮性。
同时为了有效解决一些在网存储集群的亚健康问题,我们通过灵活的设计,将亚健康能力的升级完全独立于存储集群,这使得亚健康工具拥有独立持续迭代的能力。
大规模存储盘的潜在风险
• RAID 卡和 SAS 卡固件问题
• HDD 慢盘和 SSD 性能抖动
痛点
• 业务连续性降级
○ 当硬盘进入亚健康状态后,业务响应时延急剧增加,极端情况下业务被 hung 住
• 运维管理困难
○ 维护操作繁琐
○ 缺乏故障定位工具
○ 换盘操作不够便捷
○ 导致业务受影响时间过长,运维成本高
产品优势
• 支持独立部署和升级,对存储集群无影响
• 精准判断+主动有效隔离,系统能够自愈,使得业务影响降低 98%
• 发生亚健康告警后,支持图形化的硬盘点灯和换盘操作
收益
• 无需升级旧存储集群就可以拥有亚健康盘治理能力,降低操作复杂度
• 亚健康故障对于业务影响降低 98%,保障业务连续性
• 大幅提升运维管理效率,提供硬盘亚健康的精准判断和主动有效隔离,大幅降低故障定位及解决难度,运维效率大幅提升。
未来展望
除了对于硬件亚健康实现精准判断和有效隔离外,我们已经开始规划亚健康 4.0 ,这一新版本不仅将覆盖硬件单体部件,还将扩展到全业务场景的服务和性能亚健康的检测和告警。文章来源:https://uudwc.com/A/201B8
同时,我们还会对各大主流 SSD 厂商和型号的自定义 SMART 信息进行深入分析,皆在进一步提高预警能力,保证业务连续性和提高运维管理效率。文章来源地址https://uudwc.com/A/201B8