一、pandas初级

安装matplotlib:pip install matplotlib
安装pandas:pip install pandas
本地C:\Users\Administrator\pip,在此目录配置清华园的远程下载
配置内容:
[global]
index-url=https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host=mirrors.aliyun.com
1.1 花色调整
import numpy as np
import matplotlib.pyplot as plt
img=plt.imread('./向日葵.jpg')
img.shape #高、宽、颜色,(1200, 1920, 3)
# 1200高度像素
# 1920宽度像素
# 3 颜色通道:红绿蓝
plt.imshow(img) #展示图像,红绿蓝,红色
plt.imshow(img[:,:,::-1]) #蓝绿红,蓝色
plt.imshow(img[:,:,[1,0,2]]) #绿红蓝,绿色
1.2 pandas
1.2.1 数据结构
一维结构
import pandas as pd
s=pd.Series(data=[0,3,5,7],index=['a','b','c','d'])#指定索引,一一对应
s=pd.Series(data=[0,3,5,7])#不指定索引,默认从0自增
s
0 0
1 3
2 5
3 7
dtype: int64
二维结构
第一种方式:
import pandas as pd
import numpy as np
#Excel类似
#创建DataFrame第一种方式
pd.DataFrame(data=np.random.randint(0,150,size=(5,3)),columns=['Python','En','Math'],
index=list('ABCDE'),dtype=np.float32)
第二种方式:
import pandas as pd
import numpy as np
#Excel类似
#创建DataFrame第二种方式,字典中的key作为列索引,冒号后面表示数据
pd.DataFrame(data={'Python':np.random.randint(100,150,size=5),
'En':np.random.randint(0,150,size=5),
'Math':np.random.randint(0,150,size=5)},index=list('ABCDE'))
1.2.2 数据查看
import numpy as np
import pandas as pd
df=pd.DataFrame(data=np.random.randint(0,151,size=(150,3)),
index=None,#行索引默认
columns=['Python','Math','En'])#列索引
# df.head(10)#查看前10行
# df.tail#默认查看后5个
# df.shape#查看形状
df['Python']=df['Python'].astype(np.int64)#修改数据类型
df.dtypes#查看数据类型
df.index#行索引
df.columns#列索引
df.values#对象值,二维数组
df.describe()#查看数值型列的汇总统计,平均值,最大值最小值等
df.info()#查看列索引、数据类型、非空计数和内存信息

1.2.3 数据的输入和输出
第一节:csv
import numpy as np
import pandas as pd
df=pd.DataFrame(data=np.random.randint(0,50,size=(50,5)),#薪资情况
columns=['IT','化工','生物','教师','士兵'])
display(df)
#保存到当前路径
df.to_csv('./salary.csv',
sep=',',#文本分隔符,尽量用逗号
header=True,#是否保存列索引
index=True#是否保存行索引,若保存,文件被加载时,默认行索引会作为一列
)
#加载文件
pd.read_csv('./salary.csv',
sep=',',
header=[0],#指定列索引
index_col=0)#指定行索引
第二节:Excel
pip install xlrd
pip install xlwt
写
import numpy as np
import pandas as pd
df1=pd.DataFrame(data=np.random.randint(0,50,size=(50,5)),#薪资情况
columns=['IT','化工','生物','教师','士兵'])
df2=pd.DataFrame(data=np.random.randint(0,50,size=(150,3)),#计算机科目的考试成绩
columns=['Python','Tensorflow','Keras'])#列索引
df1.to_excel('./salary.xlsx',sheet_name='salary', #Excel中工作表的名字
header=True,#是否保存列索引
index=False)#是否保存行索引
读
pd.read_excel('./salary.xlsx',
sheet_name=0,#读取哪一个Excel工作表,默认第一个,或者sheet_name='salary'
header=0,#使用第一行数据作为列索引
names=list('ABCDE'),#替换列索引
index_col=1)#指定行索引,B作为行索引
一个Excel中保存多个工作表
with pd.ExcelWriter('./data.xlsx') as writer:
df1.to_excel(writer,sheet_name='salary',index=False)
df2.to_excel(writer,sheet_name='score',index=False)
Excel中保存的多个工作表中,读取一个
pd.read_excel('./data.xlsx',
sheet_name='salary')#读取Excel中指定名字的工作表
1.2.4 数据选择
和Numpy的花式索引类似
df=pd.DataFrame(np.random.randint(0,150,size=(1000,3)),
columns=['Py','En','Math'])
df

列获取:
# df['Py'] #不显示列索引
# df.Py #不显示列索引
df[['Py','Math']]#使用两个中括号时才会显示列索引
df[['En']] #显示列索引
行获取:
df2=pd.DataFrame(np.random.randint(0,150,size=(5,3)),
index=list('ABCDE'),
columns=['Py','En','Math'])
df2
df2.loc['A']#行索引
df2.loc[['A','D']]

# df2.iloc[0]#自然数索引,第一行
df2.iloc[[0,3]]#第1行,第4行

具体数值:
df2['Math']['B']#这个必须分开写 110
df2.loc['B']['Math'] #加了loc首先要跟行索引,注意先后顺序110
df2.loc['B','Math']#也是先行后列110
# iloc表示,先获取行,再获取列
df2.iloc[1,2]#110
df2.loc['A':'C','En':]
df2.iloc[2:4,[0,-1]]#第三行、第四行的第一列和最后一列
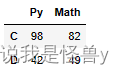
boolean索引:
cond=df['Py']==140
df[cond]
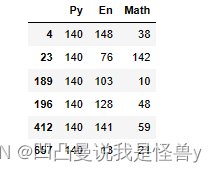
cond1=df['Py']>130
cond2=df['Math']>130
cond=cond1&cond2
df[cond]

二、pandas高级
2.1、数据筛选
2.1.1 赋值操作
import numpy as np
import pandas as pd
df=pd.DataFrame(np.random.randint(0,50,size=(20,3)),columns=['Python','Math','En'])
df
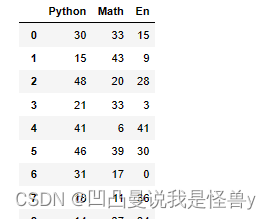
df['物理']=np.random.randint(0,50,size=20)
df
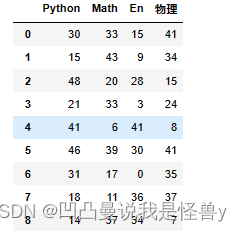
将Python增加20分
df['Python']+=20
df
将Math,索引是2,3的,变成100分
#df['Math'][2,3]=100 # 修改成功
df['Math'][[2,3]]=100 #修改成功
df[['Math','En']][[2,3]]=100 #批量修改失败
df.loc[[2,3],['Python','En']]=1024 #批量修改成功
df
条件
cond=df['物理']<10
#特别说明,表示从原来数据中,复制!!!可对其修改,原数据不变
#df[cond]-100 #变
df[cond] #原数据不变
df.loc[cond]-=100 #原数据df[cond]变了
df[cond]
2.2 数据集成
2.2.1 方式-concat
import pandas as pd
import numpy as np
#df1,1班的考试成绩
df1=pd.DataFrame(data=np.random.randint(0,150,size=[10,3]),#计算机科目的考试成绩
index=list('ABCDEFGHIJ'),
columns=['Python','Tensorflow','Keras'])#考试科目
#2班的考试科目
df2=pd.DataFrame(data=np.random.randint(0,150,size=[10,3]),#计算机科目的考试成绩
index=list('KLMNOPQRST'),
columns=['Python','Tensorflow','Keras'])#考试科目
#df3 增加了两个考试科目
df3=pd.DataFrame(data=np.random.randint(0,150,size=[10,2]),
index=list('ABCDEFGHIJ'),
columns=['PyTroch','Paddle'])#考试科目
display(df1,df2,df3)
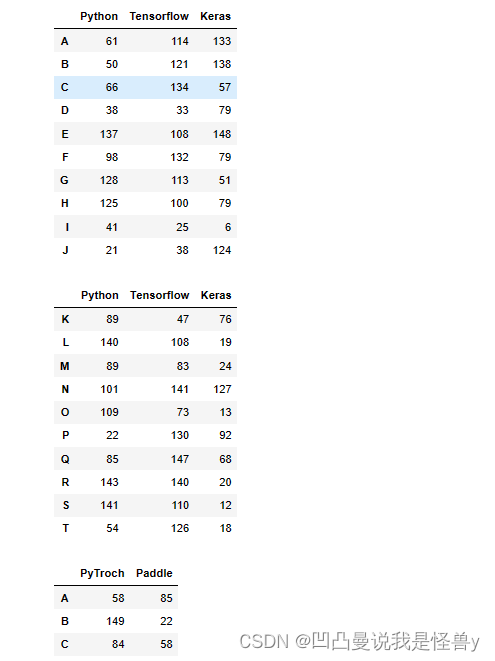
一班二班成绩合并,行合并
pd.concat([df1,df2],axis=0)#行合并
科目合并,列合并
pd.concat([df1,df3],axis=1)#列合并

2.2.2 插入
df1.insert(loc=2,column='Math',value=150)
df1
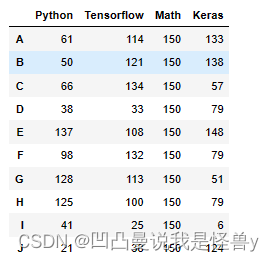
df1.columns #Index(['Python', 'Tensorflow', 'Math', 'Keras'], dtype='object')
list(df1.columns).index('Python')# 0
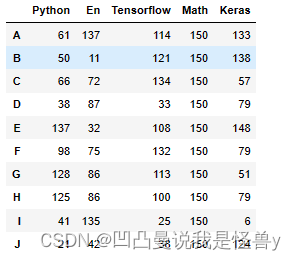
在Python后面插入一列,En
#获取列索引
#转换成list列表
#调用index函数,获取列表中特定字段的位置
#+1表示在后面
index=list(df1.columns).index('Python')+1
df1.insert(loc=index,column='En',value=np.random.randint(0,151,size=10))
df1
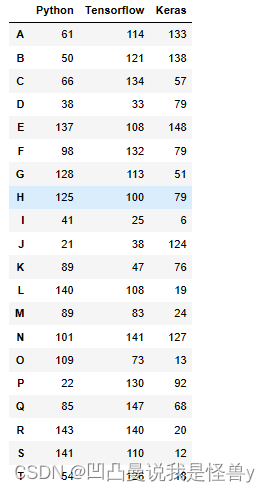
 向TensorFlow后面插入一行
向TensorFlow后面插入一行
#获取列索引
#转换成list列表
#调用index函数,获取列表中特定字段的位置
#+1表示在后面
index=list(df1.columns).index('Python')+1#想往哪插往哪插
df1.insert(loc=index,column='中文',value=np.random.randint(0,151,size=10))
df1
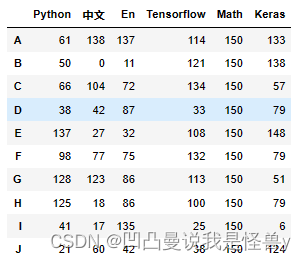
2.2.3 join SQL 数据库风格插入合并
import pandas as pd
import numpy as np
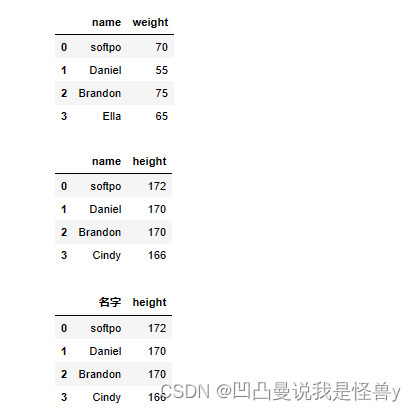
#表一种记录的是name和体重信息
df1=pd.DataFrame(data={'name':['softpo','Daniel','Brandon','Ella'],'weight':[70,55,75,65]})
#表二中记录的是name和身高信息
df2=pd.DataFrame(data={'name':['softpo','Daniel','Brandon','Cindy'],'height':[172,170,170,166]})
df3=pd.DataFrame(data={'名字':['softpo','Daniel','Brandon','Cindy'],'height':[172,170,170,166]})
display(df1,df2,df3)
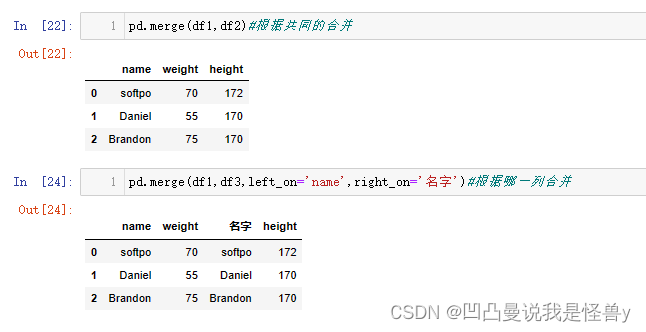
df1、df2进行合并
pd.merge(df1,df2)#根据共同的合并
pd.merge(df1,df3,left_on='name',right_on='名字')#根据哪一列合并
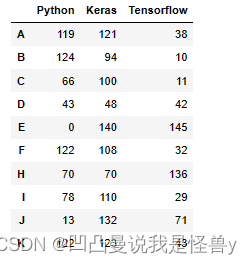
10名同学,计算每个人平均分,合并
#创建10名学生的考试成绩
df4=pd.DataFrame(data=np.random.randint(0,150,size=[10,3]),#计算机科目的考试成绩
index=list('ABCDEFHIJK'),
columns=['Python','Keras','Tensorflow'])#考试科目
df4
#每个人的各科平均分
s=df4.mean(axis=1).round(1)
df5=pd.DataFrame(s,columns=['平均值'])
df5

#根据某一列合并,df4和df5没有共同属性,但有共同索引,根据索引合并
#方法三
pd.merge(df4,df5,left_index=True,right_index=True)
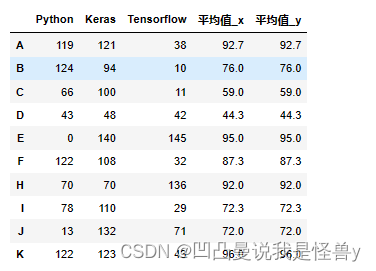
pd.concat([df4,df5],axis=1)#方法一concat方法
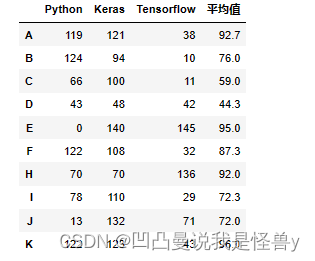
df4.insert(loc=3,column='平均值',value=df5)#方法二insert方法

2.3 数据清洗
重复数据
import pandas as pd
import numpy as np
df=pd.DataFrame(data={'color':['red','blue','red','green','blue',None,'red'],#字符串,NaN是NaN,None是None
'price':[10,20,10,15,20,0,np.NAN]})#数字显示的时候都是NaN
df
# # 1、重复数据过滤
# df.duplicated()#判断是否有重复数据
# df.drop_duplicates()#删除重复数据
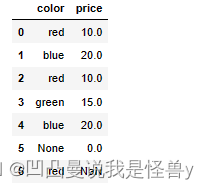
空数据过滤
df.isnull()
df.dropna()#删除有空数据的行
df.fillna(1024)#计算时,None和NaN没有区别,None是Python数据类型,NaN是NumPy的数据类型,都是表示空数据,空数据用1024替换
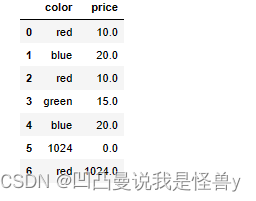
指定行或者列进行删除
#指定行或者列过滤
# del df['color']#直接删除某列,原数据修改了
# df
#!!!drop删除,返回值,原来的数据没有修改
# df.drop(labels=['price'],axis=1)#删除指定列
# df.drop(labels=[0,1,5],axis=0)#删除指定行
#inplace 修改源数据
df.drop(labels=[0,1,3,5],axis=0,inplace=True)
df

异常值
df2=pd.DataFrame(data=np.random.randn(10000,3))#正太分布数据
df2
# cond=(df2>3*df2.std()).any(axis=1)
# index=df2[cond].index#不满足条件的行索引
# df2.drop(labels=index,axis=0)#根据行索引,进行数据删除
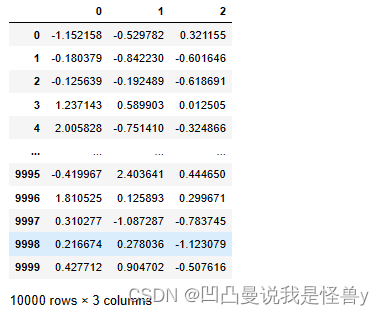
>3?异常值 ?表示标准差
cond=df2.abs()>3*df2.std()#异常值占少数
# cond.sum()
cond_0=cond[0]
df2[cond_0]
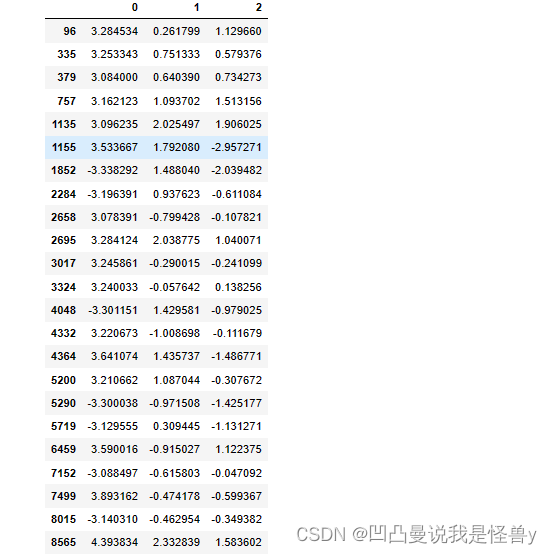
获取每一列的异常值
cond=df2.abs()>3*df2.std()
cond_0=cond[0]#默认取列索引
cond_1=cond[1]
cond_2=cond[2]
cond_=cond_0|cond_1|cond_2
df2[cond_]

cond=df2.abs()>3*df2.std()
# cond.any()#某一列只要有一个为真,返回True,默认axis=0
cond_=cond.any(axis=1)#只要一行中有一个为True,返回True
df2[cond_]
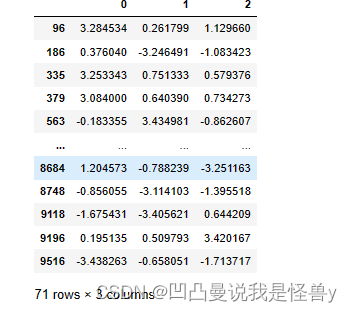
2.4 数据转换
2.4.1 轴和元素替换
import numpy as np
import pandas as pd
df=pd.DataFrame(data=np.random.randint(0,10,size=(10,3)),
index=list('ABCDEFHIJK'),
columns=['Python','Tensorflow','Keras'])
df.iloc[4,2]=None#空数据
df
#1、重命名索引
# df.rename(index={'A':'AA','B':'BB'},columns={'Python':'人工智能'})
# #2、替换值
# df.replace(3,1024)#3替换为1024,源数据不变
# df.replace([0,7],2048)
# df.replace({0:512,np.nan:998})#根据字典键值对进行替换,0替换为512,NaN替换为998
# df.replace({'Python':2},-1024)#将Python这一列中等于2的,替换为-1024
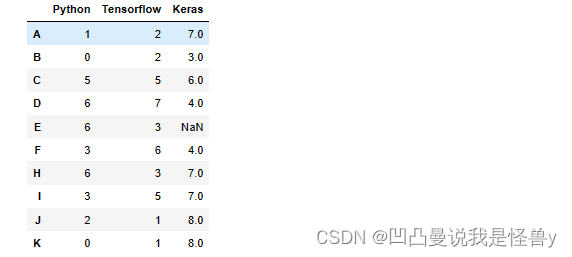
2.4.2 map Series
import numpy as np
import pandas as pd
df=pd.DataFrame(data=np.random.randint(0,10,size=(10,3)),
index=list('ABCDEFHIJK'),
columns=['Python','Tensorflow','Keras'])
df.iloc[4,2]=None#空数据
df
#1、map批量元素改变,Series专有
# df['Keras'].map({1:'Hello',5:'World',7:'AI'})#字典映射,其他数据变空
# df['Python'].map(lambda x:True if x>=5 else False)#隐试函数映射
# def convert(x):#显示函数映射,不满足条件的置为空
# if x%3==0:
# return True
# elif x%3==1:
# return False
# df['Tensorflow'].map(convert)


def convert(x):#其他数据不变
if x==9:
return 'Hello'
elif x==5:
return 'World'
elif x is np.NAN:
return 'AI'
else:
return x
df['Keras'].map(convert)

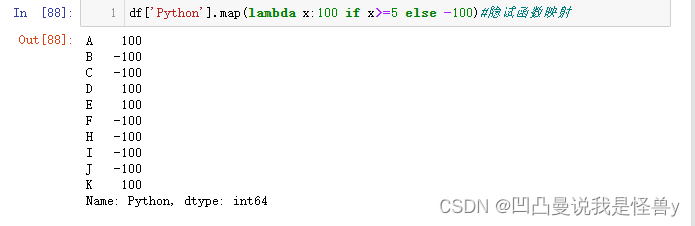
2.4.3 apply元素改变。既支持Series,也支持DataFrame
import numpy as np
import pandas as pd
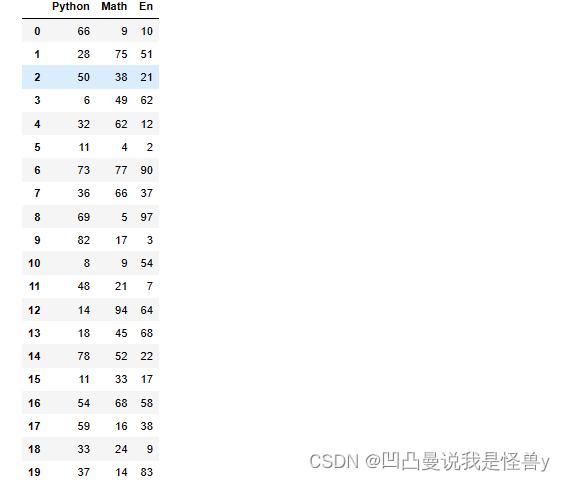
df=pd.DataFrame(np.random.randint(0,100,size=(30,3)),columns=['Python','Math','En'])
df
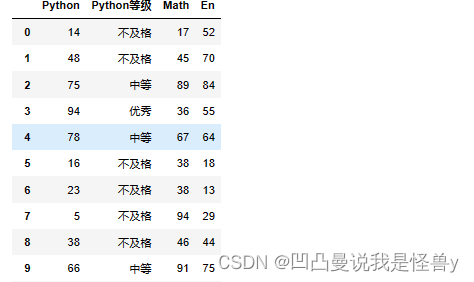
对一列进行了转换,并且进行了插入
def convert(x):
if x<60:
return '不及格'
elif x<80:
return '中等'
elsea:
return '优秀'
#根据规则,进行数据转换
result=df['Python'].apply(convert)
index=list(df.columns).index('Python')+1
df.insert(loc=index,column='Python'+'等级',value=result)
df
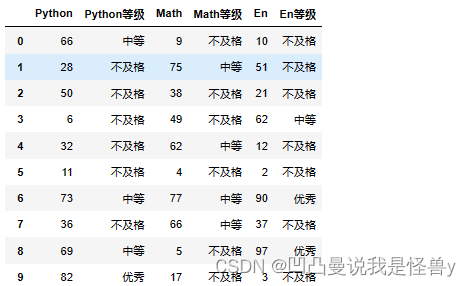
多列转换
def convert(x):
if x<60:
return '不及格'
elif x<80:
return '中等'
else:
return '优秀'
for col in ['Python','Math','En']: #已经是字符串
#根据规则,进行数据转换
result=df[col].apply(convert)
# 插入位置的索引
index=list(df.columns).index(col)+1
df.insert(loc=index,column=col+'等级',value=result)
df
2.4.4 apply应用
apply和map可以对Series进行数据修改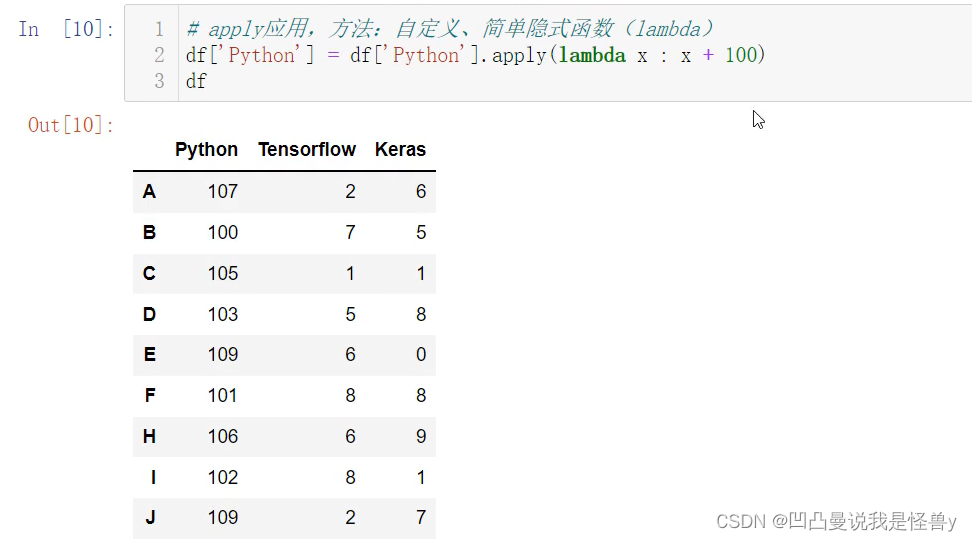
applymap 它可以对整个DataFrame进行全部处理
a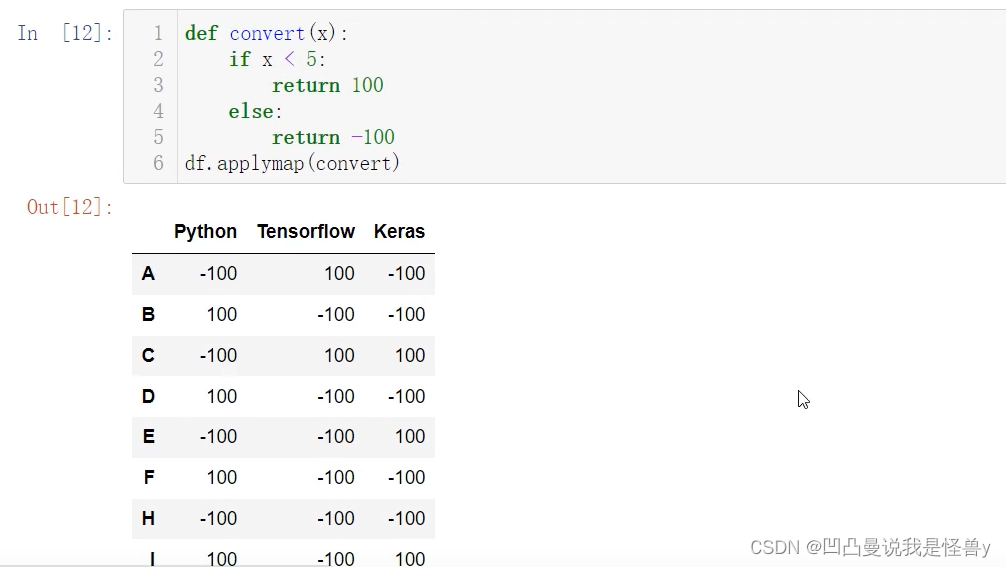
2.4.5 transform
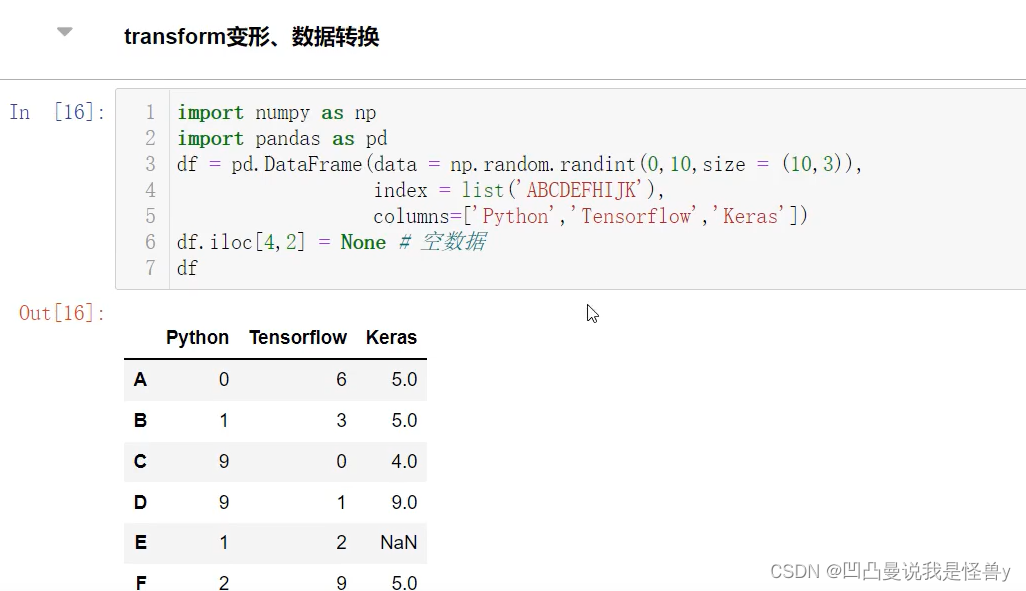
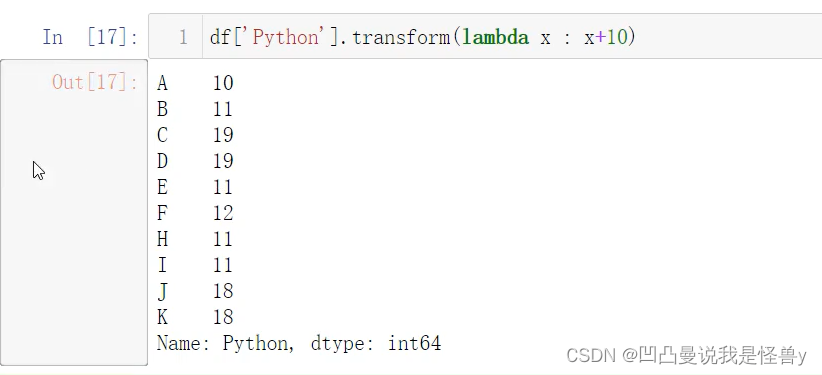
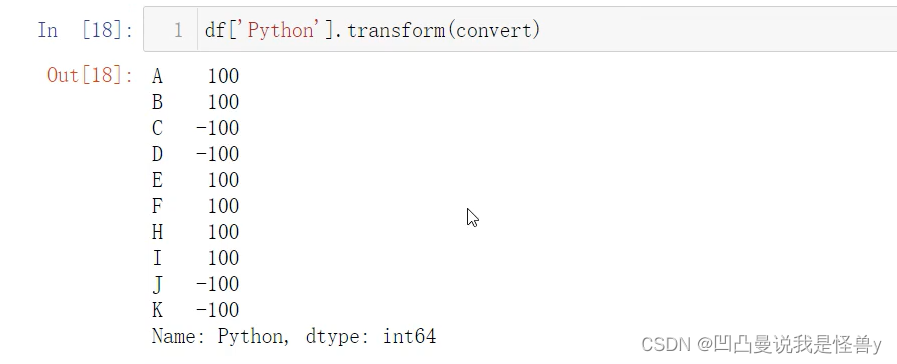
对一列,进行不同的操作,apply也可以,map不行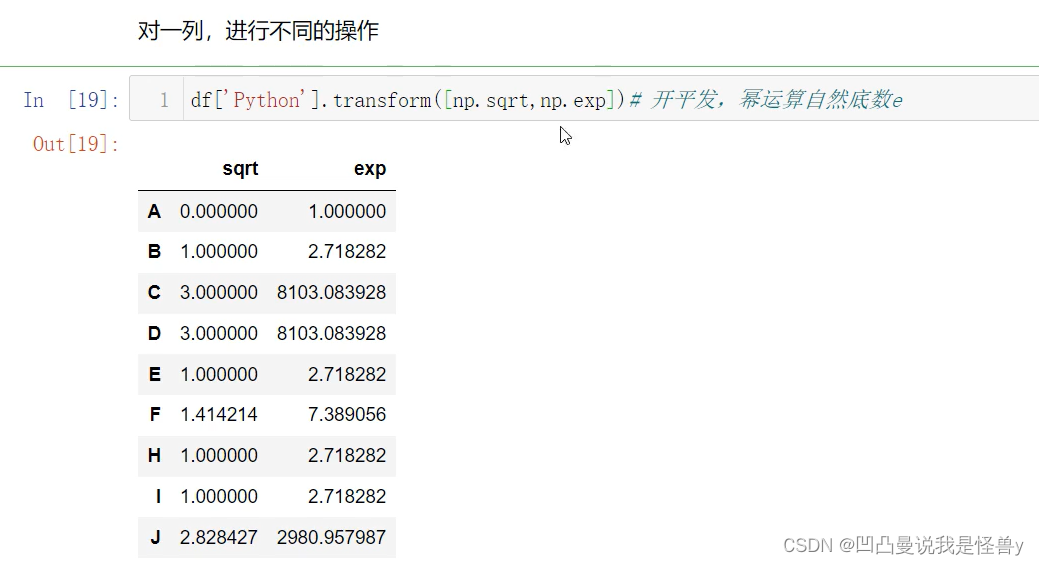
对多列进行不同的操作,apply也可以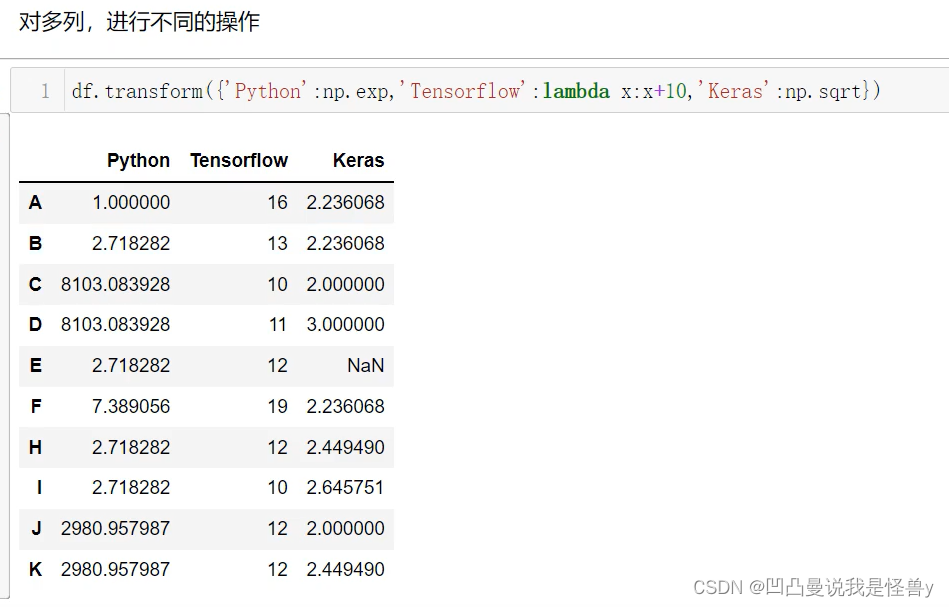 文章来源:https://uudwc.com/A/3wj3b/
文章来源:https://uudwc.com/A/3wj3b/
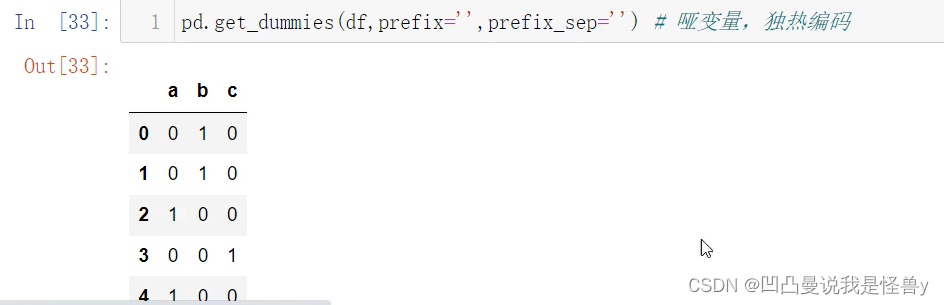
2.4.6 重排 随机抽样 哑变量
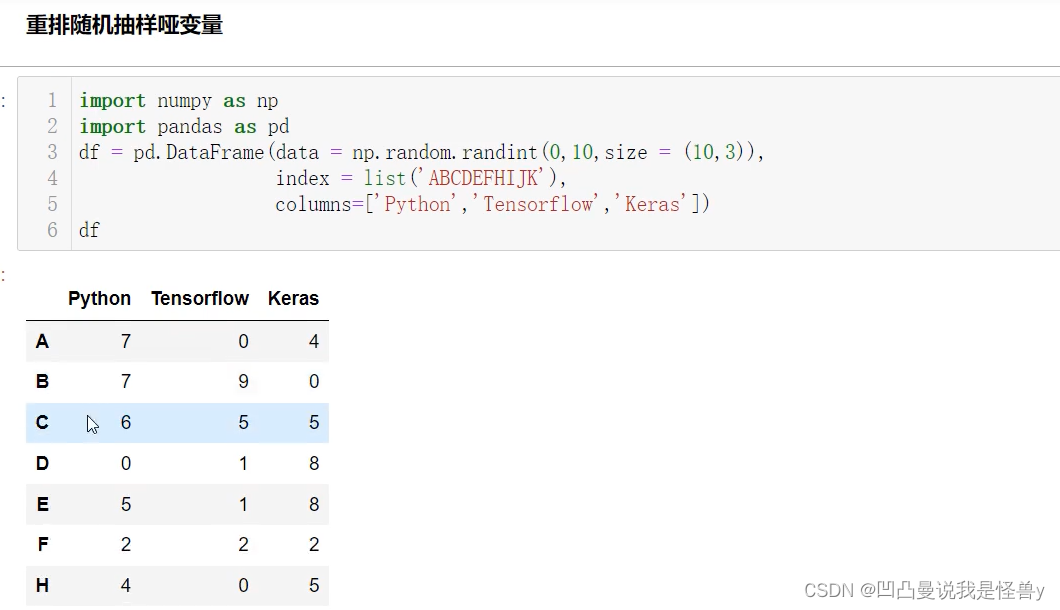
take 随机抽样可以重复
 文章来源地址https://uudwc.com/A/3wj3b/
文章来源地址https://uudwc.com/A/3wj3b/
