一般来说,监督学习的目标函数由损失函数和正则化项组成。(Objective = Loss + Regularization)
Pytorch中的损失函数一般在训练模型时候指定。
注意Pytorch中内置的损失函数的参数和tensorflow不同,是y_pred在前,y_true在后,而Tensorflow是y_true在前,y_pred在后。
对于回归模型,通常使用的内置损失函数是均方损失函数nn.MSELoss 。
对于二分类模型,通常使用的是二元交叉熵损失函数nn.BCELoss (输入已经是sigmoid激活函数之后的结果) 或者 nn.BCEWithLogitsLoss (输入尚未经过nn.Sigmoid激活函数) 。
对于多分类模型,一般推荐使用交叉熵损失函数** nn.CrossEntropyLoss**。 (y_true需要是一维的,是类别编码。y_pred未经过nn.Softmax激活。)
此外,如果多分类的y_pred经过了nn.LogSoftmax激活,可以使用nn.NLLLoss损失函数(The negative log likelihood loss)。 这种方法和直接使用nn.CrossEntropyLoss等价。
如果有需要,也可以自定义损失函数,自定义损失函数需要接收两个张量y_pred,y_true作为输入参数,并输出一个标量作为损失函数值。
Pytorch中的正则化项一般通过自定义的方式和损失函数一起添加作为目标函数。
如果仅仅使用L2正则化,也可以利用优化器的weight_decay参数来实现相同的效果。
一、内置损失函数
内置的损失函数一般有类的实现和函数的实现两种形式。
如:nn.BCE 和 F.binary_cross_entropy 都是二元交叉熵损失函数,前者是类的实现形式,后者是函数的实现形式。
实际上类的实现形式通常是调用函数的实现形式并用nn.Module封装后得到的
一般我们常用的是类的实现形式。它们封装在torch.nn模块下,并且类名以Loss结尾。
常用的一些内置损失函数说明如下。
nn.MSELoss(均方误差损失,也叫做L2损失,用于回归)
nn.L1Loss (L1损失,也叫做绝对值误差损失,用于回归)
nn.SmoothL1Loss (平滑L1损失,当输入在-1到1之间时,平滑为L2损失,用于回归)
**nn.BCELoss **(二元交叉熵,用于二分类,输入已经过nn.Sigmoid激活,对不平衡数据集可以用weigths参数调整类别权重)
nn.BCEWithLogitsLoss (二元交叉熵,用于二分类,输入未经过nn.Sigmoid激活)
nn.CrossEntropyLoss (交叉熵,用于多分类,要求label为稀疏编码,输入未经过nn.Softmax激活,对不平衡数据集可以用weigths参数调整类别权重)
nn.NLLLoss (负对数似然损失,用于多分类,要求label为稀疏编码,输入经过nn.LogSoftmax激活)
nn.KLDivLoss (KL散度损失,也叫相对熵,等于交叉熵减去信息熵,用于标签为概率值的多分类,要求输入经过nn.LogSoftmax激活)
nn.CosineSimilarity(余弦相似度,可用于多分类)
nn.AdaptiveLogSoftmaxWithLoss (一种适合非常多类别且类别分布很不均衡的损失函数,会自适应地将多个小类别合成一个cluster)
重点介绍一下 二元交叉熵、多元交叉熵、对数损失LogLoss、负对数似然损失NLLLoss、KL散度之间的区别和联系。
二元交叉熵


多元交叉熵

y
i
^
\hat{y_i}
yi^是一个长度的K的概率向量,当
y
i
y_i
yi==k,即取到对应的类别时才有意义,所以
y
i
,
k
^
\hat{y_{i,k}}
yi,k^就表示
y
i
^
\hat{y_i}
yi^中的索引为k的值,这样就可以log了,对每一个样本都是如此处理,那么最后归一化。
logloss对数损失函数

这同样是
y
i
^
\hat{y_i}
yi^取索引为其类别的值,所以与交叉熵等价。(每个样本对其标签对应类别的预测概率值求对数,求平均再取负数即可)
pytorch中的 nn.NLLLoss 和 nn.CrossEntropyLoss有什么区别和联系?
如果多分类的y_pred经过了nn.LogSoftmax激活,可以使用nn.NLLLoss损失函数(The negative log likelihood loss)。 这种方法和直接使用nn.CrossEntropyLoss等价。

KL散度的计算公式是什么?有什么现实含义?和交叉熵有什么关系?

KL散度等于交叉熵减去信息熵。
nn.BCELoss() 和 nn.BCEWithLogitsLoss() 关系:
import numpy as np
import pandas as pd
import torch
from torch import nn
import torch.nn.functional as F
# nn.BCELoss() 和 nn.BCEWithLogitsLoss() 关系
y_pred = torch.tensor([5.0,3,10,-5,-3,-10.0])
y_true = torch.tensor([1.0,1,1,0,0,0])
bce = nn.BCELoss()(torch.sigmoid(y_pred),y_true) # 输入已经是sigmoid激活函数之后的结果
print(bce)
bce_logits = nn.BCEWithLogitsLoss()(y_pred,y_true) # 输入尚未经过nn.Sigmoid激活函数
print(bce_logits)
# 结果一致

nn.CrossEntropyLoss() 和 nn.NLLLoss() 关系
y_pred = torch.tensor([[10.0,0.0,-10.0],[8.0,8.0,8.0]])
y_true = torch.tensor([0,2])
# 直接调用交叉熵损失
ce = nn.CrossEntropyLoss()(y_pred,y_true)
print(ce)
# 等价于先计算nn.LogSoftmax激活,再调用nn.NLLLoss
y_pred_logsoftmax = nn.LogSoftmax(dim = 1)(y_pred)
nll = nn.NLLLoss()(y_pred_logsoftmax,y_true)
print(nll)

nn.CrossEntropyLoss() 和 KLDivLoss 关系:
import torch.nn.functional as F
y_pred = torch.tensor([[10.0,0.0,-10.0],[8.0,8.0,8.0]],requires_grad=True)
y_true = torch.tensor([0,2])
ce = nn.CrossEntropyLoss(reduction="mean")(y_pred,y_true)
print(ce)
#KLDivLoss要求target为向量形式编码且preds经过LogSoftmax激活
pred = F.log_softmax(y_pred,dim=1)
target = F.one_hot(y_true).float()
kl = nn.KLDivLoss(reduction="batchmean")(pred,target)
print(kl)

二、自定义损失函数
自定义损失函数接收两个张量y_pred,y_true作为输入参数,并输出一个标量作为损失函数值。
也可以对nn.Module进行子类化,重写forward方法实现损失的计算逻辑,从而得到损失函数的类的实现。
下面演示两个比较著名的范例。
自定义损失函数之FocalLoss范例
下面是一个Focal Loss的自定义实现示范。Focal Loss是一种对binary_crossentropy的改进损失函数形式。
它在样本不均衡和存在较多易分类的样本时相比binary_crossentropy具有明显的优势。
它有两个可调参数,alpha参数和gamma参数。其中alpha参数主要用于衰减负样本的权重,gamma参数主要用于衰减容易训练样本的权重。
从而让模型更加聚焦在正样本和困难样本上。这就是为什么这个损失函数叫做Focal Loss。
详见《5分钟理解Focal Loss与GHM——解决样本不平衡利器》
https://zhuanlan.zhihu.com/p/80594704
Focal Loss的引入主要是为了解决难易样本数量不平衡(注意,有区别于正负样本数量不平衡)
但这并不能解决全部问题。根据正、负、难、易,样本一共可以分为以下四类: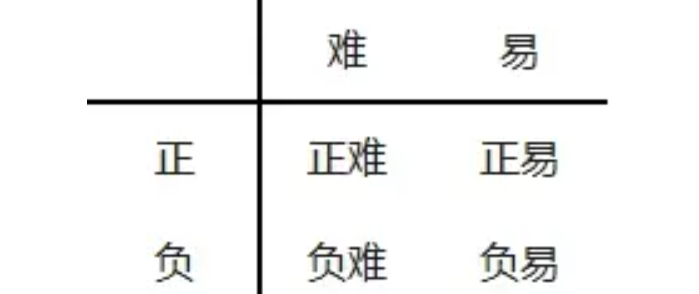
尽管 平衡了正负样本,但对难易样本的不平衡没有任何帮助。而实际上,目标检测中大量的候选目标都是像下图一样的易分样本。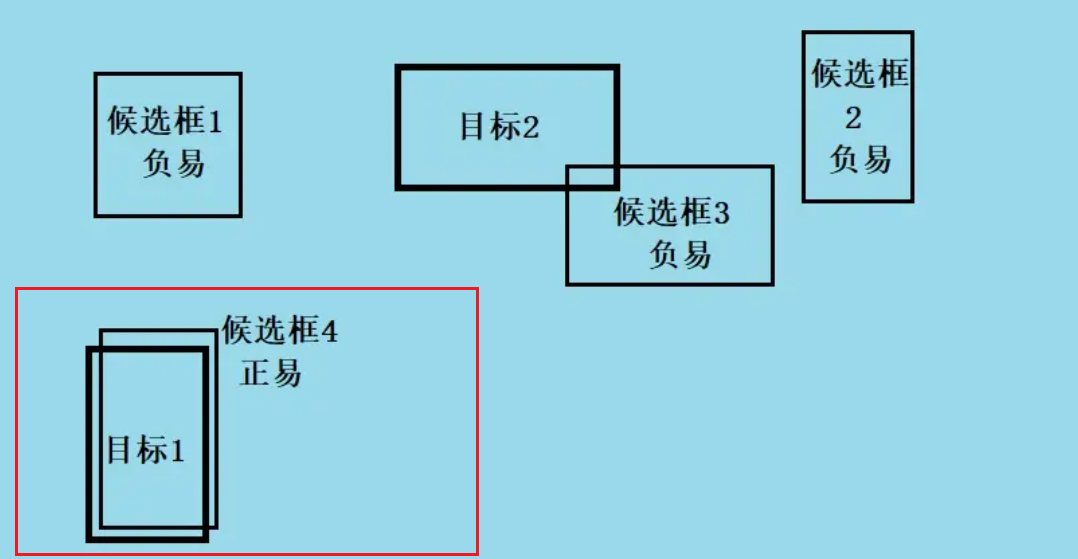
这些样本的损失很低,但是由于数量极不平衡,易分样本的数量相对来讲太多,最终主导了总的损失。而易分样本(即,置信度高的样本)对模型的提升效果非常小,模型应该主要关注与那些难分样本。

import torch
from torch import nn
class FocalLoss(nn.Module):
def __init__(self,gamma=2.0,alpha=0.75):
super().__init__()
self.gamma = gamma
self.alpha = alpha
def forward(self,y_pred,y_true):
bce = torch.nn.BCELoss(reduction = "none")(y_pred,y_true) # 当reduction='none'时,输出是对每一个样本预测的损失
p_t = (y_true * y_pred) + ((1 - y_true) * (1 - y_pred))
alpha_factor = y_true * self.alpha + (1 - y_true) * (1 - self.alpha)
modulating_factor = torch.pow(1.0 - p_t, self.gamma)
loss = torch.mean(alpha_factor * modulating_factor * bce)
return loss
#困难样本
y_pred_hard = torch.tensor([[0.5],[0.5]])
y_true_hard = torch.tensor([[1.0],[0.0]])
#容易样本
y_pred_easy = torch.tensor([[0.9],[0.1]])
y_true_easy = torch.tensor([[1.0],[0.0]])
focal_loss = FocalLoss()
bce_loss = nn.BCELoss()
print("focal_loss(easy samples):", focal_loss(y_pred_easy,y_true_easy))
print("bce_loss(easy samples):", bce_loss(y_pred_easy,y_true_easy))
print("focal_loss(hard samples):", focal_loss(y_pred_hard,y_true_hard))
print("bce_loss(hard samples):", bce_loss(y_pred_hard,y_true_hard))
#可见 focal_loss让容易样本的权重衰减到原来的 0.0005/0.1054 = 0.00474
#而让困难样本的权重只衰减到原来的 0.0866/0.6931=0.12496
# 因此相对而言,focal_loss可以衰减容易样本的权重。

SCELoss

def ce(y,p):
p = torch.clamp(p,min=1e-4,max=1-1e-4)
y = torch.clamp(y,min=1e-4,max=1-1e-4)
return -y*torch.log(p) - (1-y)*torch.log(1-p)
def rce(y,p):
return ce(p,y)
#正常标签
y = torch.tensor(1.0)
p = torch.tensor(0.8)
print(rce(y,p)/ce(y,p))
#噪声标签
y = torch.tensor(0.0)
p = torch.tensor(0.8)
print(rce(y,p)/ce(y,p))
import torch
from torch import nn
import torch.nn.functional as F
class SCELoss(nn.Module):
def __init__(self, num_classes=10, a=1, b=1):
super(SCELoss, self).__init__()
self.num_classes = num_classes
self.a = a #两个超参数
self.b = b
self.cross_entropy = nn.CrossEntropyLoss()
def forward(self, pred, labels):
# CE 部分,正常的交叉熵损失
ce = self.cross_entropy(pred, labels)
# RCE
pred = F.softmax(pred, dim=1)
pred = torch.clamp(pred, min=1e-4, max=1.0)
label_one_hot = F.one_hot(labels, self.num_classes).float().to(pred.device)
label_one_hot = torch.clamp(label_one_hot, min=1e-4, max=1.0) #最小设为 1e-4,即 A 取 -4
rce = (-1 * torch.sum(pred * torch.log(label_one_hot), dim=1))
loss = self.a * ce + self.b * rce.mean()
return loss
三、L1和L2正则化
做正则化的时候,是不需要考虑偏置bias的,因为我们正则化是减轻过拟合,让模型方法更加稳定,也就是更加平滑,泛化能力更强,而bias的作用只是把方法上下移动,对平滑却没啥作用。
正则化为什么能缓解过拟合?
给loss function加上正则化项,能使得新得到的优化目标函数h = f+normal,需要在f和normal中做一个权衡(trade-off),如果还像原来只优化f的情况下,那可能得到一组解比较复杂,使得正则项normal比较大,那么h就不是最优的,因此可以看出加正则项能让解更加简单,符合奥卡姆剃刀理论,同时也比较符合在偏差和方差(方差表示模型的复杂度)分析中,通过降低模型复杂度,得到更小的泛化误差,降低过拟合程度。
L1正则化和L2正则化:
L1正则化就是在loss function后边所加正则项为L1范数,加上L1范数容易得到稀疏解(0比较多)。L2正则化就是loss function后边所加正则项为L2范数的平方,加上L2正则相比于L1正则来说,得到的解比较平滑(不是稀疏),但是同样能够保证解中接近于0(但不是等于0,所以相对平滑)的维度比较多,降低模型的复杂度。
原理参考:参考文章《L1正则化与L2正则化》:https://zhuanlan.zhihu.com/p/35356992
import torch
# L2正则化
def L2Loss(model,alpha):
l2_loss = torch.tensor(0.0, requires_grad=True)
for name, param in model.named_parameters():
if 'bias' not in name: #一般不对偏置项使用正则
l2_loss = l2_loss + (0.5 * alpha * torch.sum(torch.pow(param, 2))) # L2范数的平方
return l2_loss
# L1正则化
def L1Loss(model,beta):
l1_loss = torch.tensor(0.0, requires_grad=True)
for name, param in model.named_parameters():
if 'bias' not in name:
l1_loss = l1_loss + beta * torch.sum(torch.abs(param)) # L1范数
return l1_loss
四、L1L2正则项使用完整范例¶
准备数据
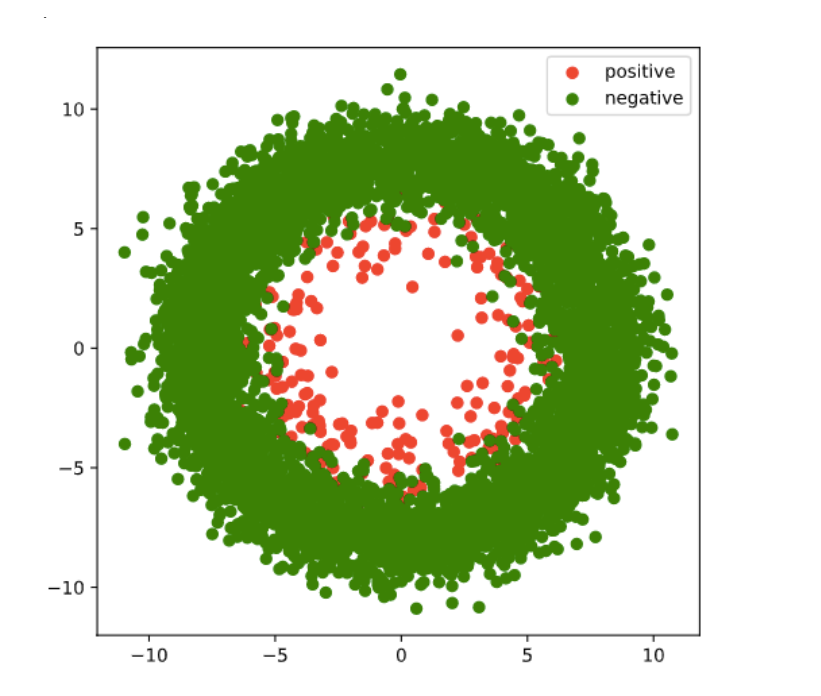
ds = TensorDataset(X,Y)
ds_train, ds_val = torch.utils.data.random_split(ds,[int(len(ds)*0.7),len(ds)-int(len(ds)*0.7)])
dl_train = DataLoader(ds_train,batch_size = 100,shuffle=True,num_workers=2)
dl_val = DataLoader(ds_val,batch_size = 100,num_workers=2)
features,labels = next(iter(dl_train))
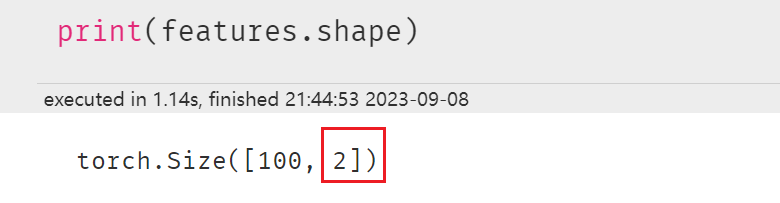
定义模型
class Net(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(2,4)
self.fc2 = nn.Linear(4,8)
self.fc3 = nn.Linear(8,1)
def forward(self,x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
y = self.fc3(x)
return y
net = Net()
from torchkeras import summary
summary(net,features);

训练模型
# L2正则化
def L2Loss(model,alpha):
l2_loss = torch.tensor(0.0, requires_grad=True)
for name, param in model.named_parameters():
if 'bias' not in name: #一般不对偏置项使用正则
l2_loss = l2_loss + (0.5 * alpha * torch.sum(torch.pow(param, 2)))
return l2_loss
# L1正则化
def L1Loss(model,beta):
l1_loss = torch.tensor(0.0, requires_grad=True)
for name, param in model.named_parameters():
if 'bias' not in name:
l1_loss = l1_loss + beta * torch.sum(torch.abs(param))
return l1_loss
from torchkeras import KerasModel
from torchkeras.metrics import AUC
net = Net()
# 将L2正则和L1正则添加到FocalLoss损失,一起作为目标函数
def focal_loss_with_regularization(y_pred,y_true):
y_probs = torch.sigmoid(y_pred)
focal = FocalLoss()(y_probs,y_true)
l2_loss = L2Loss(net,0.001) #注意设置正则化项系数
l1_loss = L1Loss(net,0.001)
total_loss = focal + l2_loss + l1_loss # 原来损失 + L1正则化 + L2正则化
return total_loss
optimizer = torch.optim.Adam(net.parameters(),lr = 0.002) # 优化器
model = KerasModel(net=net,
loss_fn = focal_loss_with_regularization ,
metrics_dict = {"auc":AUC()},
optimizer= optimizer )
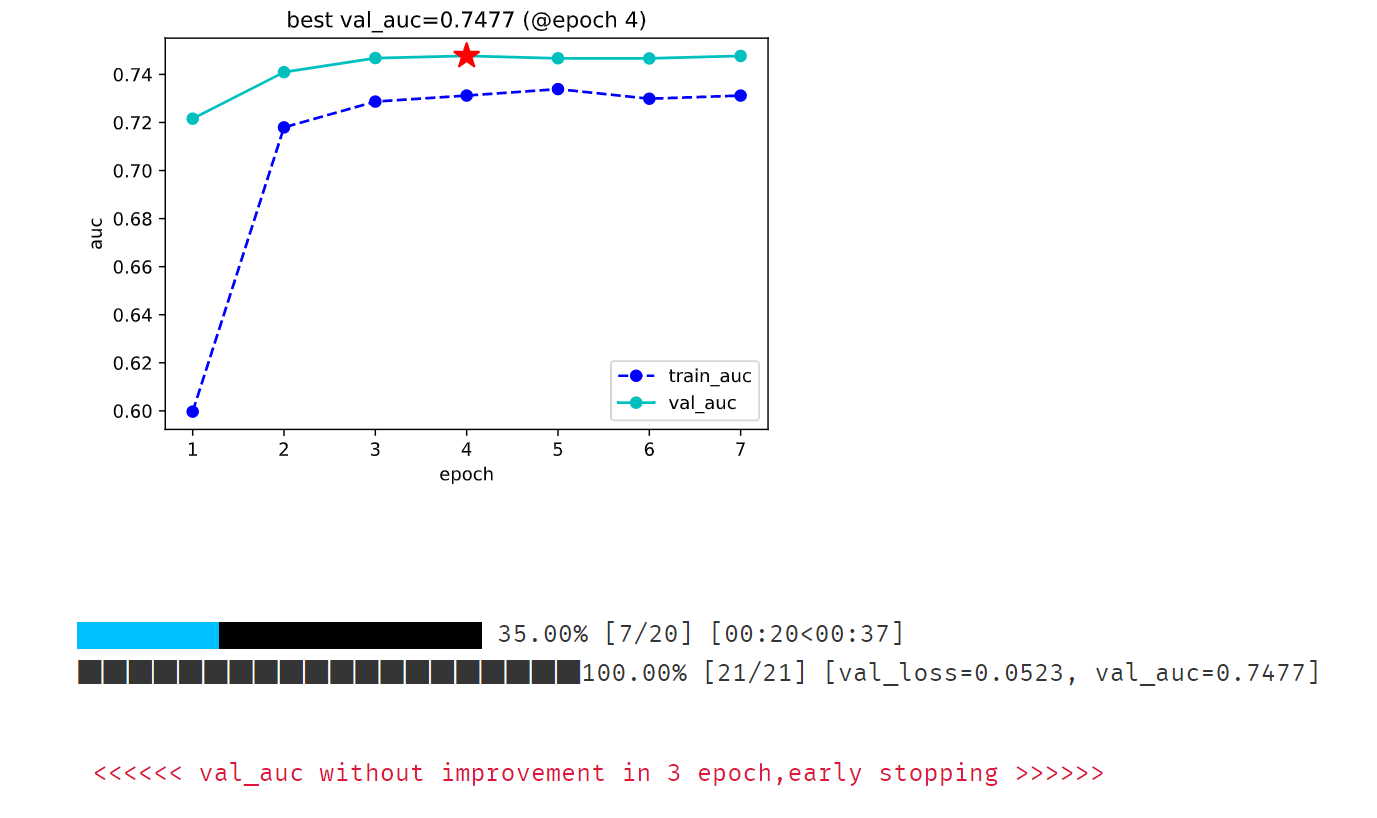
dfhistory = model.fit(train_data=dl_train,
val_data=dl_val,
epochs=20,
ckpt_path='checkpoint',
patience=3,
monitor='val_auc',
mode='max',
plot=True,
cpu=True
)
五、通过优化器实现L2正则化
如果仅仅需要使用L2正则化,那么也可以利用优化器的weight_decay参数来实现。
weight_decay参数可以设置参数在训练过程中的衰减,这和L2正则化的作用效果等价。
before L2 regularization:
gradient descent: w = w - lr * dloss_dw
after L2 regularization:
gradient descent: w = w - lr * (dloss_dw+betaw) = (1-lrbeta)w - lrdloss_dw
so (1-lr*beta)is the weight decay ratio.
Pytorch的优化器支持一种称之为Per-parameter options的操作,就是对每一个参数进行特定的学习率,权重衰减率指定,以满足更为细致的要求。文章来源:https://uudwc.com/A/3wjBm
weight_params = [param for name, param in model.named_parameters() if "bias" not in name]
bias_params = [param for name, param in model.named_parameters() if "bias" in name]
optimizer = torch.optim.SGD([{'params': weight_params, 'weight_decay':1e-5},
{'params': bias_params, 'weight_decay':0}],
lr=1e-2, momentum=0.9)
参考:https://github.com/lyhue1991/eat_pytorch_in_20_days文章来源地址https://uudwc.com/A/3wjBm
