Python之selenium库基础
- 一、安装库和浏览器驱动
- 1.1 安装库
- 1.2 安装浏览器驱动
- 二、selenium基础
- 2.1 浏览器访问并搜索
- 2.2 浏览器页面控制
- 2.2.1 修改浏览器窗口尺寸
- 2.2.2 浏览器前进和后退
- 2.2.3 浏览器刷新
- 2.2.4 关闭页面
- 2.2.4 浏览器窗口切换
- 2.2.5 模拟输入、清除、获得属性值、元素尺寸、元素文本
- 2.3 鼠标控制
- 2.3.1 鼠标左键单击
- 2.3.2 鼠标右键
- 2.3.3 双击
- 2.3.4 鼠标拖动
- 2.3.5 鼠标悬浮
- 2.4 键盘控制
- 2.5 设置等待
- 2.5.1 显示等待
- 2.5.2 隐示等待
- 2.5.3 强制等待
- 2.6 浏览器页面元素定位
- 2.6.1 id定位
- 2.6.2 name定位
- 2.6.3 class定位
- 2.6.4 tag定位
- 2.6.5 xpath定位
- 2.6.5.1 Selenium XPath根据文本内容查找元素的方法
- 2.6.6 css定位
- 2.6.7 link定位
- 2.6.8 partial_link 定位
- 2.7 定位一组元素
一、安装库和浏览器驱动
1.1 安装库
- 打开cmd,采用清华源安装selenium;
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium
1.2 安装浏览器驱动
- Chrome浏览器驱动:https://chromedriver.storage.googleapis.com/index.html
- 查看浏览器版本,安装对应的驱动,解压下载文件后,将文件拷贝到python安装路径中;
二、selenium基础
- 点击F12进入开发者工具,可以定位我们所需的元素;
2.1 浏览器访问并搜索
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
# 1.访问CSDN
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/') # 访问CSDN
# 2.根据标签ID搜索内容并点击回车
driver.find_element(By.ID, 'toolbar-search-input').send_keys('python', Keys.ENTER) # 搜索python关键字并回车
2.2 浏览器页面控制
2.2.1 修改浏览器窗口尺寸
# 设置浏览器浏览器的宽高为:600x800
driver.set_window_size(600, 800)
# 全屏展示浏览器
driver.maximize_window()
2.2.2 浏览器前进和后退
- webdriver 提供 back 和 forward 方法来实现页面的后退与前进。下面我们 ①进入CSDN首页,②打开CSDN个人主页,③back 返回到CSDN首页,④ forward 前进到个人主页。
from selenium import webdriver
import time
driver = webdriver.Chrome()
# 访问CSDN首页
driver.get('https://www.csdn.net/')
time.sleep(2) #等待2秒
#访问CSDN个人主页
driver.get('https://blog.csdn.net/qq_40216188')
time.sleep(2)
#返回(后退)到CSDN首页
driver.back()
time.sleep(2)
#前进到个人主页
driver.forward()
- 第二次调用get()方法时,是新开一个标签页,如果想新开一个浏览器页面的话,执行如下js代码:
# 在原页面打开
driver.get('https://blog.csdn.net/qq_40216188')
# 新中打开
js = "window.open('https://blog.csdn.net/qq_40216188')"
driver.execute_script(js)
2.2.3 浏览器刷新
# 刷新页面
driver.refresh()
2.2.4 关闭页面
- 使用 quit() 方法可以关闭所有窗口并退出驱动程序;
driver.quit()
- 使用 close() 方法可以关闭当前页面窗口,打开多个页面时,只关闭当前停留的页面;
driver.close()
2.2.4 浏览器窗口切换
- 在 selenium 操作页面的时候,可能会因为点击某个链接而跳转到一个新的页面(打开了一个新标签页),这时候 selenium 实际还是处于上一个页面的,需要我们进行切换才能够定位最新页面上的元素。
- 窗口切换需要使用
switch_to.windows()方法。 - 当打开新页面时,我们需要切换到新的窗口,窗口按时间排序,最新打开的页面在最后;
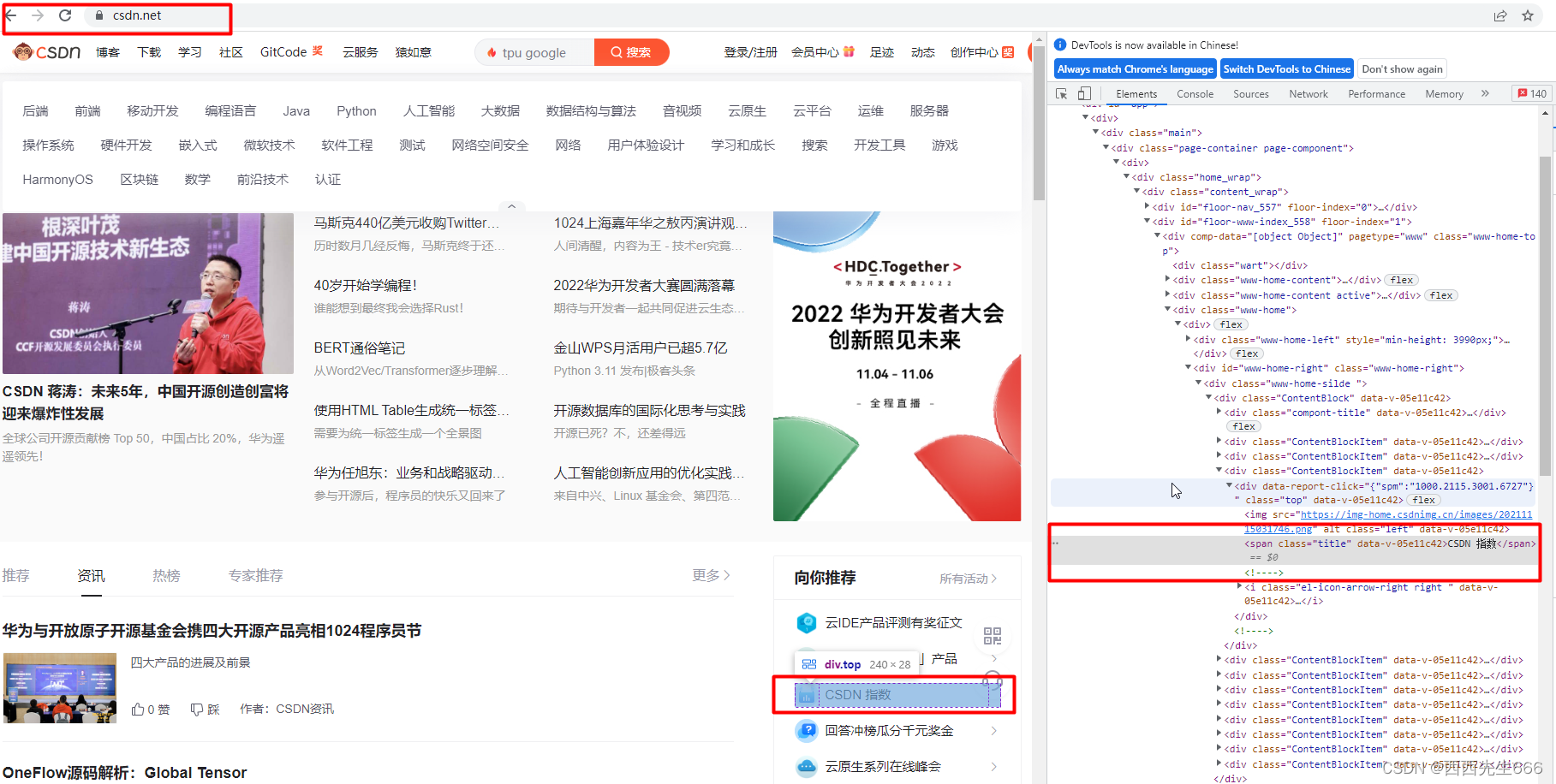
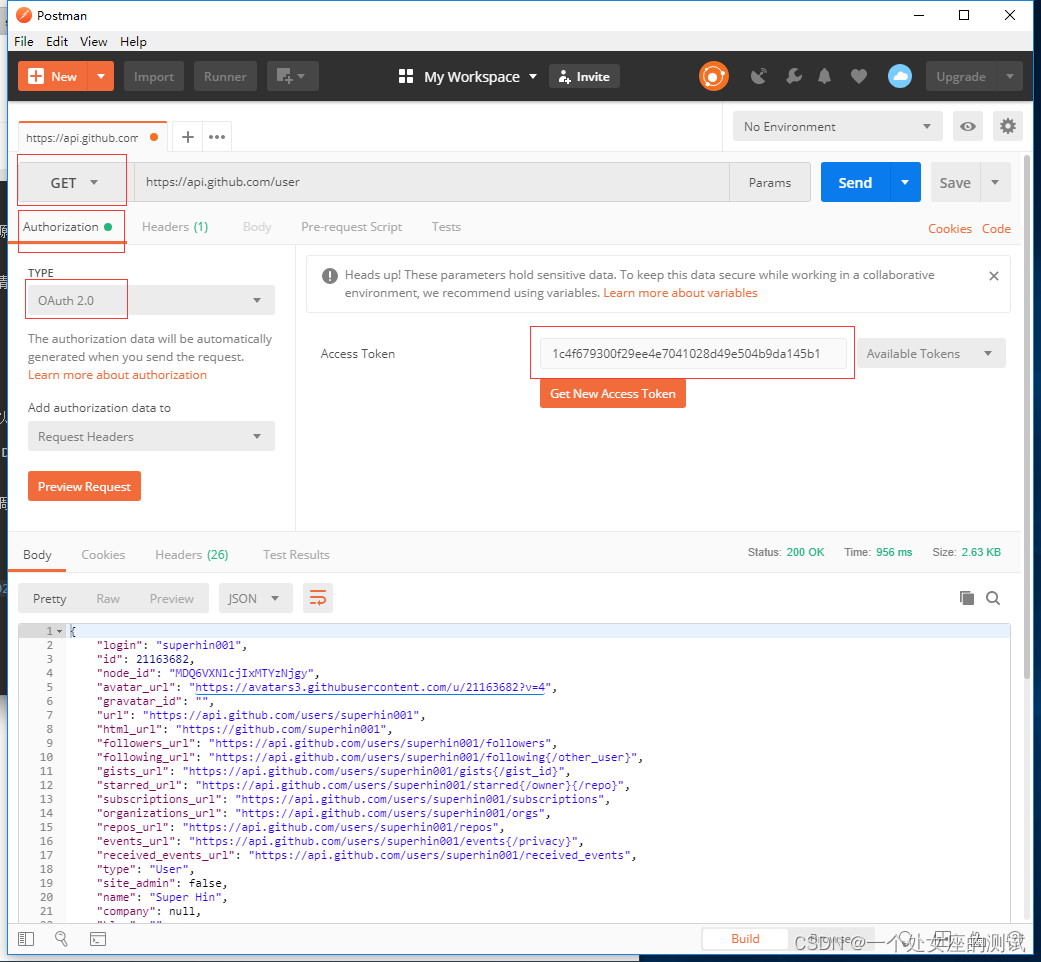
- 如上图所示,进入CSDN主页,点击【CSDN指数】,跳转到新页面;
from selenium import webdriver
handles = []
driver = webdriver.Chrome()
driver.get('https://www.csdn.net')
driver.maximize_window()
# 设置隐式等待
driver.implicitly_wait(3)
# 获取当前窗口的句柄
handles.append(driver.current_window_handle)
# 点击进入新页面
driver.find_element(By.XPATH,
'//*[@id="www-home-right"]/div[1]/div[1]/div[4]/div/span').click()
# 获取当前窗口的句柄
handles.append(driver.current_window_handle)
print(handles)
# 获取当前所有窗口的句柄
print(driver.window_handles)

- 可以看到第一个列表handle是相同的,说明selenium实际操作的还是CSDN首页,并未切换到新页面;
- 使用
switch_to.windows()进行切换
from selenium import webdriver
handles = []
driver = webdriver.Chrome()
driver.get('https://www.csdn.net')
driver.maximize_window()
# 设置隐式等待
driver.implicitly_wait(3)
# 获取当前窗口的句柄
handles.append(driver.current_window_handle)
# 点击页面
driver.find_element(By.XPATH,
'//*[@id="www-home-right"]/div[1]/div[1]/div[4]/div/span').click()
# 切换到当前最新打开的窗口
driver.switch_to.window(driver.window_handles[-1])
# 获取当前窗口的句柄
handles.append(driver.current_window_handle)
print(handles)
# 获取当前所有窗口的句柄
print(driver.window_handles)

- 上面代码在点击跳转后,使用 switch_to 切换窗口,window_handles 返回的 handle 列表是按照页面出现时间进行排序的,最新打开的页面肯定是最后一个,这样用 driver.window_handles[-1] + switch_to 即可跳转到最新打开的页面了。
- 那如果打开的窗口有多个,如何跳转到之前打开的窗口,如果确实有这个需求,那么打开窗口是就需要记录每一个窗口的 key(别名) 与 value(handle),保存到字典中,后续根据 key 来取 handle 。
handles = driver.window_handles #获取当前浏览器的所有窗口句柄
driver.switch_to.window(handles[-1]) #切换到最新打开的窗口
driver.switch_to.window(handles[-2]) #切换到倒数第二个打开的窗口
driver.switch_to.window(handles[0]) #切换到最开始打开的窗口
2.2.5 模拟输入、清除、获得属性值、元素尺寸、元素文本
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/')
time.sleep(2)
# 定位搜索输入框
text_label = driver.find_element(By.XPATH, '//*[@id="toolbar-search-input"]')
# 模拟输入:python
text_label.send_keys('python')
time.sleep(2)
# 清除搜索框中的内容
text_label.clear()
# 输出搜索框元素是否可见
print(text_label.is_displayed())
# 输出placeholder属性值
print(text_label.get_attribute('placeholder'))
# 定位搜索按钮
button = driver.find_element(By.XPATH, '//*[@id="toolbar-search-button"]/span')
# 输出按钮的大小
print(button.size)
# 输出按钮上的文本
print(button.text)
'''输出内容
True
python面试100问
{'height': 32, 'width': 28}
搜索
'''
2.3 鼠标控制
2.3.1 鼠标左键单击
# 定位点击内容
button=driver.find_element(By.XPATH, '//*[@id="toolbar-search-button"]/span')
# 点击
button.click()
2.3.2 鼠标右键
.perform()函数:执行所有ActionChains中存储的动作
from selenium.webdriver.common.action_chains import ActionChains
# 定位搜索按钮
button = driver.find_element(By.XPATH, '//*[@id="toolbar-search-button"]/span')
# 右键搜索按钮
ActionChains(driver).context_click(button).perform()
2.3.3 双击
# 定位搜索按钮
button = driver.find_element(By.XPATH, '//*[@id="toolbar-search-button"]/span')
# 执行双击动作
ActionChains(driver).double_click(button).perform()
2.3.4 鼠标拖动
- 鼠标拖动2个必要参数:
source:待拖动的元素
target:拖至并释放的目标元素
# 定位要拖动的元素
source = driver.find_element(By.XPATH,'xxx')
# 定位目标元素
target = driver.find_element(By.XPATH,'xxx')
# 执行拖动动作
ActionChains(driver).drag_and_drop(source, target).perform()
2.3.5 鼠标悬浮
- 鼠标悬浮为了显示隐藏的下拉框;
# 定位收藏栏
collect = driver.find_element(By.XPATH, '//*[@id="csdn-toolbar"]/div/div/div[3]/div/div[3]/a')
# 悬停至收藏标签处
ActionChains(driver).move_to_element(collect).perform()
2.4 键盘控制
from selenium.webdriver.common.keys import Keys
# 定位输入框并输入文本
driver.find_element(By.ID, 'xxx').send_keys('python')
# 模拟回车键进行跳转(输入内容后)
driver.find_element(By.ID, 'xxx').send_keys(Keys.ENTER)
# 使用 Backspace 来删除一个字符
driver.find_element(By.ID,'xxx').send_keys(Keys.BACK_SPACE)
# Ctrl + A 全选输入框中内容
driver.find_element(By.ID,'xxx').send_keys(Keys.CONTROL, 'a')
# Ctrl + C 复制输入框中内容
driver.find_element(By.ID,'xxx').send_keys(Keys.CONTROL, 'c')
# Ctrl + V 粘贴输入框中内容
driver.find_element(By.ID,'xxx').send_keys(Keys.CONTROL, 'v')
# F1键
driver.find_element(By.ID,'xxx').send_keys(Keys.F1)
# 空格
driver.find_element(By.ID,'xxx').send_keys(Keys.SPACE)
# Tab键
driver.find_element(By.ID,'xxx').send_keys(Keys.TAB)
# ESC键
driver.find_element(By.ID,'xxx').send_keys(Keys.ESCAPE)
# Alt键
driver.find_element(By.ID,'xxx').send_keys(Keys.ALT)
# Shift键
driver.find_element(By.ID,'xxx').send_keys(Keys.SHIFT)
# 向下箭头
driver.find_element(By.ID,'xxx').send_keys(Keys.ARROW_DOWN)
# 向左箭头
driver.find_element(By.ID,'xxx').send_keys(Keys.ARROW_LEFT)
# 向右箭头
driver.find_element(By.ID,'xxx').send_keys(Keys.ARROW_RIGHT)
# 向上箭头
driver.find_element(By.ID,'xxx').send_keys(Keys.ARROW_UP)
2.5 设置等待
- 页面元素有时不是同时加载出来的,为了避免在未加载完全的页面中获取元素失败,可设置等待时间;
2.5.1 显示等待
- 显式等待:设置一个超时时间,每个一段时间就去检测一次该元素是否存在,如果存在则执行后续内容,如果超过最大时间(超时时间)则抛出超时异常(TimeoutException)。显示等待需要使用 WebDriverWait,同时配合 until 或 not until。
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
"""
driver:浏览器驱动
timeout:超时时间,单位秒
poll_frequency:每次检测的间隔时间,默认为0.5秒
ignored_exceptions:指定忽略的异常,如果在调用 until 或 until_not 的过程中抛出指定忽略的异常,则不中断代码,默认忽略的只有 NoSuchElementException
"""
until(method, message='')
until_not(method, message='')
"""
method:指定预期条件的判断方法,在等待期间,每隔一段时间调用该方法,判断元素是否存在,直到元素出现。until_not 正好相反,当元素消失或指定条件不成立,则继续执行后续代码;
message: 如果超时,抛出 TimeoutException ,并显示 message 中的内容
"""
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
element = WebDriverWait(driver, 5, 0.5).until(
EC.presence_of_element_located((By.ID, 'kw')),
message='超时啦!')

2.5.2 隐示等待
- 隐式等待也是指定一个超时时间,如果超出这个时间指定元素还没有被加载出来,就会抛出 NoSuchElementException 异常。即运行过程中,如果元素可以定位到,它不会影响代码运行,但如果定位不到,则它会以轮询的方式不断地访问元素直到元素被找到,若超过指定时间,则抛出异常。
- 使用
implicitly_wait()来实现隐式等待,使用难度相对于显式等待要简单很多。 - 示例:打开个人主页,设置一个隐式等待时间 5s,通过 id 定位一个不存在的元素,最后打印 抛出的异常 与 运行时间
from selenium import webdriver
from time import time
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/qq_40216188')
start = time()
driver.implicitly_wait(5) #轮训5秒之后仍没有找到定位元素,抛出异常
try:
driver.find_element(By.ID,'kw')
except Exception as e:
print(e)
print(f'耗时:{time()-start}')
"""结果
Message: no such element: Unable to locate element: {"method":"css selector","selector":"[id="kw"]"}
(Session info: chrome=106.0.5249.119)
Stacktrace:
Backtrace:
Ordinal0 [0x00ED1ED3+2236115]
Ordinal0 [0x00E692F1+1807089]
Ordinal0 [0x00D766FD+812797]
Ordinal0 [0x00DA55DF+1005023]
Ordinal0 [0x00DA57CB+1005515]
Ordinal0 [0x00DD7632+1209906]
Ordinal0 [0x00DC1AD4+1120980]
Ordinal0 [0x00DD59E2+1202658]
Ordinal0 [0x00DC18A6+1120422]
Ordinal0 [0x00D9A73D+960317]
Ordinal0 [0x00D9B71F+964383]
GetHandleVerifier [0x0117E7E2+2743074]
GetHandleVerifier [0x011708D4+2685972]
GetHandleVerifier [0x00F62BAA+532202]
GetHandleVerifier [0x00F61990+527568]
Ordinal0 [0x00E7080C+1837068]
Ordinal0 [0x00E74CD8+1854680]
Ordinal0 [0x00E74DC5+1854917]
Ordinal0 [0x00E7ED64+1895780]
BaseThreadInitThunk [0x7534FA29+25]
RtlGetAppContainerNamedObjectPath [0x774D7BBE+286]
RtlGetAppContainerNamedObjectPath [0x774D7B8E+238]
耗时:5.058804988861084
"""
2.5.3 强制等待
- 使用 time.sleep() 强制等待,设置固定的休眠时间,对于代码的运行效率会有影响;
from selenium import webdriver
from time import time, sleep
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/qq_40216188')
start = time()
sleep(5)
try:
driver.find_element(By.ID, 'kw')
except Exception as e:
print(e)
print(f'耗时:{time()-start}')
 文章来源:https://uudwc.com/A/4oNM
文章来源:https://uudwc.com/A/4oNM
2.6 浏览器页面元素定位
- 以我们熟知的 CSDN 为例,我们进入首页,按 【F12】 进入开发者工具。红框中显示的就是页面的代码,我们要做的就是从代码中定位获取我们需要的元素。
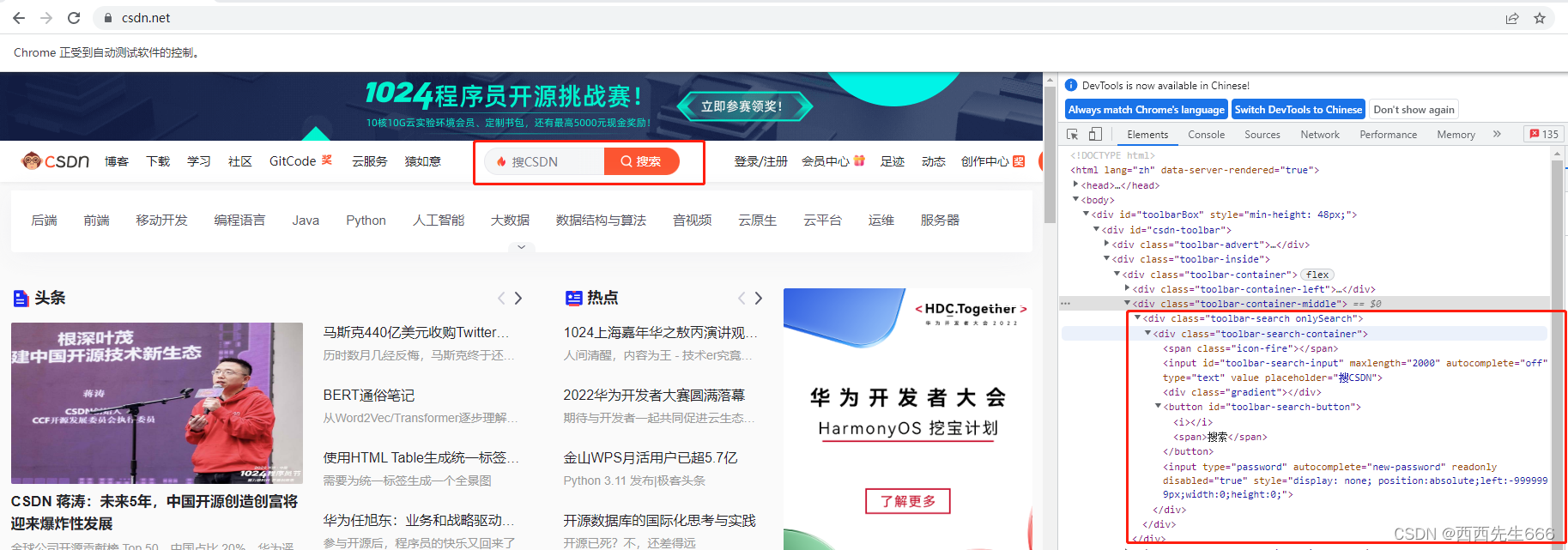
2.6.1 id定位
- 标签的id具有唯一性,假设有个input的标签为:
<input id="toolbar-search-input" autocomplete="off" type="text" value="" placeholder="C++难在哪里?">
driver.find_element(By.ID, "toolbar-search-input")
2.6.2 name定位
- name 指定标签的名称,在页面中可以不唯一。假设有个 meta 标签如下:
<meta name="keywords" content="CSDN博客,CSDN学院,CSDN论坛,CSDN直播">
driver.find_element(By.NAME, "keywords")
2.6.3 class定位
- class 指定标签的类名,在页面中可以不唯一。假设有个 div 标签如下:
<div class="toolbar-search-container">
driver.find_element(By.CLASS_NAME, "toolbar-search-container")
2.6.4 tag定位
- 每个 tag 往往用来定义一类功能,所以通过 tag 来识别某个元素的成功率很低,每个页面一般都用很多相同的 tag ,比如:<div>、<input> 等。这里还是用上面的 div 作为例子。
- 前端tag类型参见:https://www.cnblogs.com/blknemo/p/10553021.html
<div class="toolbar-search-container">
driver.find_element(By.TAG_NAME, "div")
2.6.5 xpath定位
- xpath 是一种在 XML 文档中定位元素的语言,它拥有多种定位方式,下面通过实例我们看一下它的几种使用方式。
<html>
<head>...<head/>
<body>
<div id="csdn-toolbar">
<div class="toolbar-inside">
<div class="toolbar-container">
<div class="toolbar-container-left">...</div>
<div class="toolbar-container-middle">
<div class="toolbar-search onlySearch">
<div class="toolbar-search-container">
<input id="toolbar-search-input" autocomplete="off" type="text" value="" placeholder="C++难在哪里?">
- 根据上面的标签需要定位 最后一行 input 标签,以下列出了四种方式,xpath 定位的方式多样并不唯一,使用时根据情况进行解析即可。
# 绝对路径(层级关系)定位
driver.find_element(By.XPATH, "/html/body/div/div/div/div[2]/div/div/input[1]")
# 利用元素属性定位
driver.find_element(By.XPATH, "//*[@id='toolbar-search-input']"))
# 层级+元素属性定位
driver.find_element(By.XPATH, "//div[@id='csdn-toolbar']/div/div/div[2]/div/div/input[1]")
# 逻辑运算符定位
driver.find_element(By.XPATH, "//*[@id='toolbar-search-input' and @autocomplete='off']")
- 前端页面xpath获取方式,元素定位后,点击下图中三个点->Copy->Copy XPath 或者Copy full XPath;
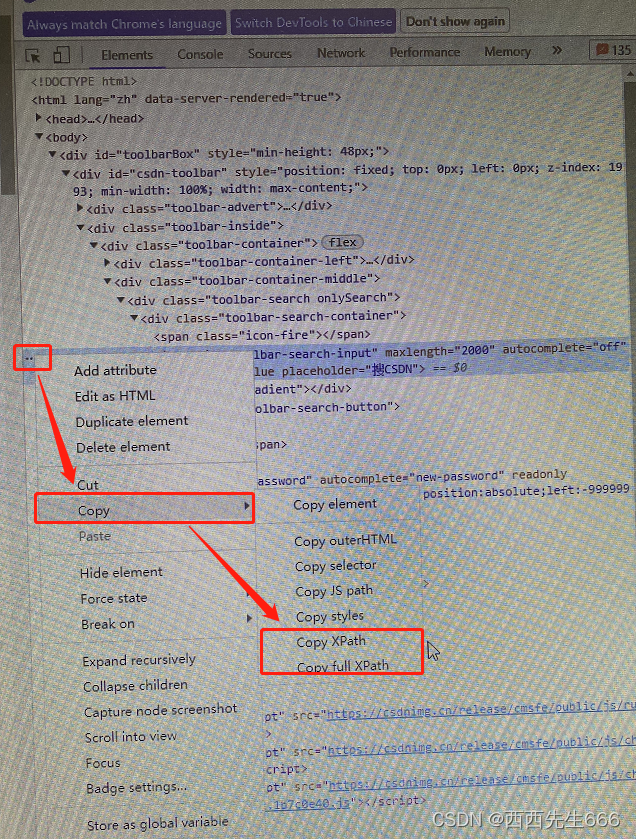
2.6.5.1 Selenium XPath根据文本内容查找元素的方法
from selenium.webdriver.common.by import By
# 方式1:通过文本内容精准定位元素
driver.find_element(By.XPATH, '//div[text()="文本内容"]')
# 方式2:通过文本内容模糊定位元素
driver.find_element(By.XPATH, '//div[contains(text(), "文本内容")]')
2.6.6 css定位
- CSS 使用选择器来为页面元素绑定属性,它可以较为灵活的选择控件的任意属性,一般定位速度比 xpath 要快,但使用起来略有难度。
CSS 选择器常见语法:
| 方法 | 例子 | 描述 |
|---|---|---|
| .class | .toolbar-search-container | 选择 class = ‘toolbar-search-container’ 的所有元素 |
| #id | #toolbar-search-input | 选择 id = ‘toolbar-search-input’ 的元素 |
| * | * | 选择所有元素 |
| element | input | 选择所有 <input> 元素 |
| element>element | div>input | 选择父元素为 <div> 的所有 <input> 元素 |
| element+element | div+input | 选择同一级中在 <div> 之后的所有 <input> 元素 |
| [attribute=value] | type=‘text’ | 选择 type = ‘text’ 的所有元素 |
- 举个简单的例子,同样定位上面实例中的 input 标签。
driver.find_element(By.CSS_SELECTOR, '#toolbar-search-input')
driver.find_element(By.CSS_SELECTOR, 'html>body>div>div>div>div>div>div>input')
2.6.7 link定位
- link 专门用来定位文本链接,假如要定位下面这一标签。
<div class="practice-box" data-v-04f46969="">加入!每日一练</div>
driver.find_element(By.LINK_TEXT, "加入!每日一练")
2.6.8 partial_link 定位
- partial_link 翻译过来就是“部分链接”,对于有些文本很长,这时候就可以只指定部分文本即可定位,同样使用刚才的例子。
driver.find_element(By.PARTIAL_LINK_TEXT, "加入")
2.7 定位一组元素
- 将
find_element替换为find_elements即可,可是实现2.6章节的8种方式的定位;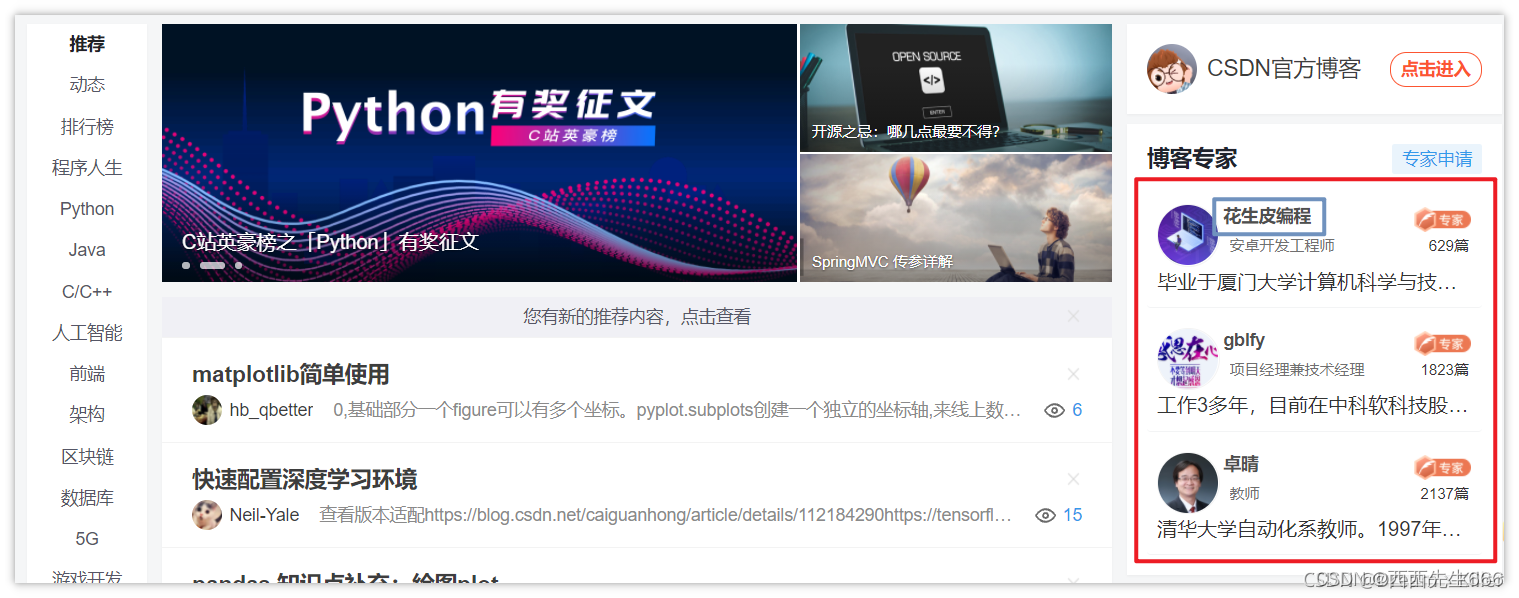

- 找出三位专家的名称:
from selenium import webdriver
# 设置无头浏览器
option = webdriver.ChromeOptions()
option.add_argument('--headless')
driver = webdriver.Chrome(options=option)
driver.get('https://blog.csdn.net/')
p_list = driver.find_elements(By.XPATH, "//p[@class='name']")
name = [p.text for p in p_list]
name
#结果:"花生皮编程", "gblfy", "卓晴"
参考:文章来源地址https://uudwc.com/A/4oNM
-
- https://blog.csdn.net/qq_43965708/article/details/120658713?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166693127316800186596281%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=166693127316800186596281&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogtop_positive~default-1-120658713-null-null.nonecase&utm_term=selenium&spm=1018.2226.3001.4450
-
- https://blog.csdn.net/weixin_56349063/article/details/121860280
-
- https://blog.csdn.net/xkyjwcc/article/details/127492594