文章目录
- ?引言
- ?为什么需要分类问题的性能衡量标准?
- ?常用的分类问题衡量标准
- ?混淆矩阵-精确率-召回率
- ?PR曲线和ROC曲线
- ?PR曲线
- ?ROC曲线
- ?PR vs. ROC
- ?根据情境选择适当的性能度量
?引言
当涉及到机器学习和数据科学中的分类问题时,评估模型的性能至关重要。选择适当的性能衡量标准有助于我们了解模型的效果,并作出有根据的决策。本博客将介绍一些常用的分类问题衡量标准,以及它们在不同情境下的应用。
?为什么需要分类问题的性能衡量标准?
在机器学习中,分类问题是一类非常常见的任务。它包括将数据点分为两个或多个不同的类别或标签。例如,我们可以使用分类算法来预测电子邮件是否为垃圾邮件,患者是否患有某种疾病,图像中的对象是什么等等。对于这些问题,我们需要一种方式来评估模型的性能,以便选择最合适的模型、调整参数,并最终在实际应用中做出可靠的决策。
?常用的分类问题衡量标准
以下是一些常用的分类问题性能衡量标准:
-
准确度(Accuracy):
准确度是最简单的性能衡量标准之一。它表示模型正确分类的样本数与总样本数之比。
适用情况:准确度适用于各个类别数量差距不大的情况,其中每个类别的重要性相似。 -
精确率(Precision):
精确率是指模型正确预测正类别样本的比例,它是真正例(True Positives, TP)与真正例与假正例之和(TP + False Positives, FP)的比值。
适用情况:当假正例的成本很高时,精确率是一个重要的度量标准,例如,医学诊断中。 -
召回率(Recall):
召回率是指模型正确预测正类别样本的比例,它是真正例(TP)与真正例与假负例(False Negatives, FN)之和的比值。
适用情况:当假负例的成本很高时,召回率是一个关键的性能度量,例如,安全检测中。 -
F1分数(F1 Score):
F1分数是精确率和召回率的调和平均值,它可以平衡精确率和召回率之间的权衡关系。
适用情况:在需要同时考虑精确率和召回率的情况下,F1分数是一个有用的度量标准。 -
ROC曲线和AUC(Receiver Operating Characteristic Curve and Area Under Curve):
ROC曲线是一个用于可视化分类器性能的工具,而AUC是ROC曲线下的面积,用于量化分类器的性能。
适用情况:ROC曲线和AUC通常用于二进制分类问题,特别是在不同阈值下比较模型性能时。
?混淆矩阵-精确率-召回率
首先需要导入一个库,其实就是精确率、召回率、混淆矩阵,还有一些必要的库
from sklearn.metrics import precision_score,recall_score,confusion_matrix
from sklearn.datasets import load_digits
import numpy as np
from sklearn.model_selection import train_test_split
接下来我们准备数据
digits =load_digits()
y = digits.target.copy()
X = digits.data
y [digits.target==8]=1
y [digits.target!=8]=0
y采取copy是因为,后面会报错,所以还是不要在原数据进行修改
这段代码的主要目的是将手写数字数据集转化为一个二元分类问题,其中目标是判断一个手写数字是否为数字8(标签为1)或不是数字8(标签为0)
接下来进行数据集切割,并进行拟合
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=666)
log_reg = LogisticRegression(max_iter=1000)
log_reg.fit(X_train,y_train)
max_iter参数用于指定模型训练的最大迭代次数,这里设置为1000,以确保模型在训练期间能够收敛到一个合适的解。
接下来进行准确率的计算,混淆矩阵的生成,以及精确率、召回率的计算
log_reg.score(X_test,y_test)
运行结果如下

confusion_matrix(y_test,log_reg.predict(X_test))
运行结果如下
precision_score(y_test,log_reg.predict(X_test))
运行结果如下
recall_score(y_test,log_reg.predict(X_test))
运行结果如下
最后我们来看看f1的情况,这里我们需要导入一个库
from sklearn.metrics import f1_score
f1_score(y_test,log_reg.predict(X_test))
运行结果如下

?PR曲线和ROC曲线
?PR曲线
PR曲线是评估二分类模型性能的一种重要工具。它关注的是模型在正类别上的性能,特别是在识别正类别时的准确性和召回率。
准确性(Precision是指模型将正类别的样本正确分类为正类别的比例。它的计算公式如下:
Precision=TPTP+FPPrecision=TP+FPTP
其中, T P TP TP代表真正例(True Positives), F P FP FP代表假正例(False Positives)。
召回率(Recall是指模型成功识别正类别的样本的比例。它的计算公式如下:
Recall=TPTP+FNRecall=TP+FNTP
其中, F N FN FN代表假阴性(False Negatives)。
PR曲线以不同的阈值作为横轴,Precision和Recall作为纵轴,通过绘制不同阈值下的Precision-Recall点来可视化模型性能。一条PR曲线越靠近左上角,模型性能越好。
具体实现如下
接下来我们使用如下代码计算逻辑回归模型在测试数据集 X_test 上的决策函数值
log_reg.decision_function(X_test)[:5]
之后我们导一下库
from sklearn.metrics import precision_recall_curve
并且调用这个曲线,并将数据保存在定义的三个变量中
pre,recall,thresholds = precision_recall_curve(y_test,log_reg.decision_function(X_test))
然后我们绘制一下
import matplotlib.pyplot as plt
plt.plot(pre,recall)
运行结果如下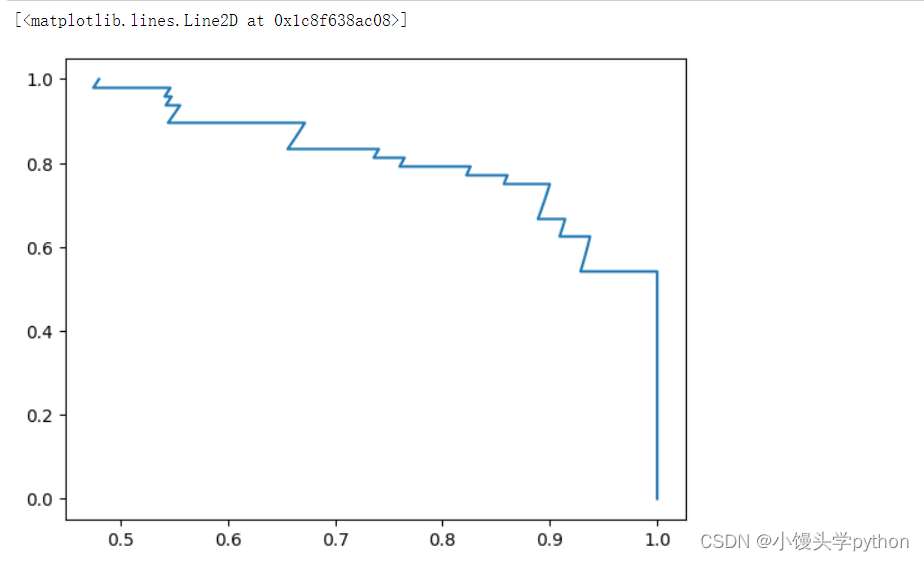
?ROC曲线
ROC曲线是另一种用于评估分类模型性能的工具,它关注的是模型的真正例率(True Positive Rate)和假正例率(False Positive Rate)。
真正例率(True Positive Rate,也称为召回率是指模型成功识别正类别的样本的比例,计算方式与PR曲线中的Recall相同。
假正例率(False Positive Rate是指模型错误地将负类别的样本分类为正类别的比例,计算方式如下:
FPR=FPFP+TNFPR=FP+TNFP
其中, F P FP FP代表假正例(False Positives), T N TN TN代表真负例(True Negatives)。
ROC曲线以不同的阈值作为横轴,True Positive Rate作为纵轴,通过绘制不同阈值下的True Positive Rate和False Positive Rate点来可视化模型性能。一条ROC曲线越靠近左上角,模型性能越好。
绘制ROC曲线与PR曲线类似
from sklearn.metrics import roc_curve,roc_auc_score
fpr,tpr,thresholds = roc_curve(y_test,log_reg.decision_function(X_test))
plt.plot(fpr,tpr)
运行结果如下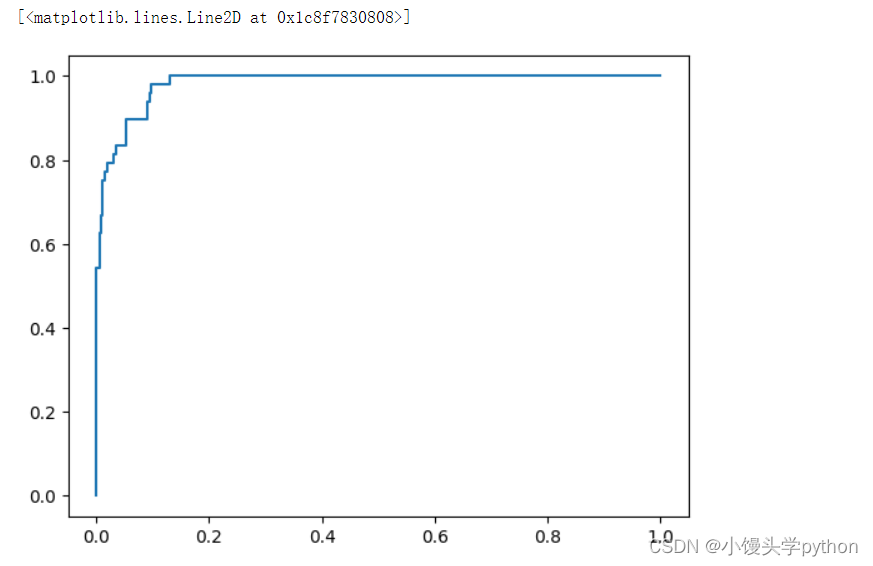
这里也可以看看ROC曲线的面积情况
一般来说,AUC越接近1,模型性能越好
roc_auc_score(y_test,log_reg.decision_function(X_test))
运行结果如下
?PR vs. ROC
PR曲线和ROC曲线都有其独特的用途和适用场景。PR曲线更适合于不平衡类别分布的问题,因为它关注的是正类别的准确性和召回率。ROC曲线在不同类别之间的代价不平衡问题中表现较好,因为它关注的是True Positive Rate和False Positive Rate。
绘制这两种曲线的过程相似,通常需要使用模型的预测概率来确定不同的阈值,并计算相应的性能指标。在Python中,您可以使用Scikit-Learn库来轻松生成这些曲线。
?根据情境选择适当的性能度量
在选择性能度量标准时,需要考虑问题的具体情境和目标。不同的问题可能需要不同的度量标准。例如,如果我们正在处理医学诊断问题,其中假负例可能导致严重后果,那么我们可能更关注召回率。另一方面,如果我们正在过滤垃圾邮件,我们可能更关注精确率,因为将合法邮件错误地标记为垃圾邮件可能会引起麻烦。
此外,有时候需要综合考虑多个性能度量标准。例如,使用F1分数来平衡精确率和召回率,或者使用ROC曲线和AUC来评估模型在不同阈值下的性能表现。
 文章来源:https://uudwc.com/A/4r1pW
文章来源:https://uudwc.com/A/4r1pW
挑战与创造都是很痛苦的,但是很充实。文章来源地址https://uudwc.com/A/4r1pW