目录
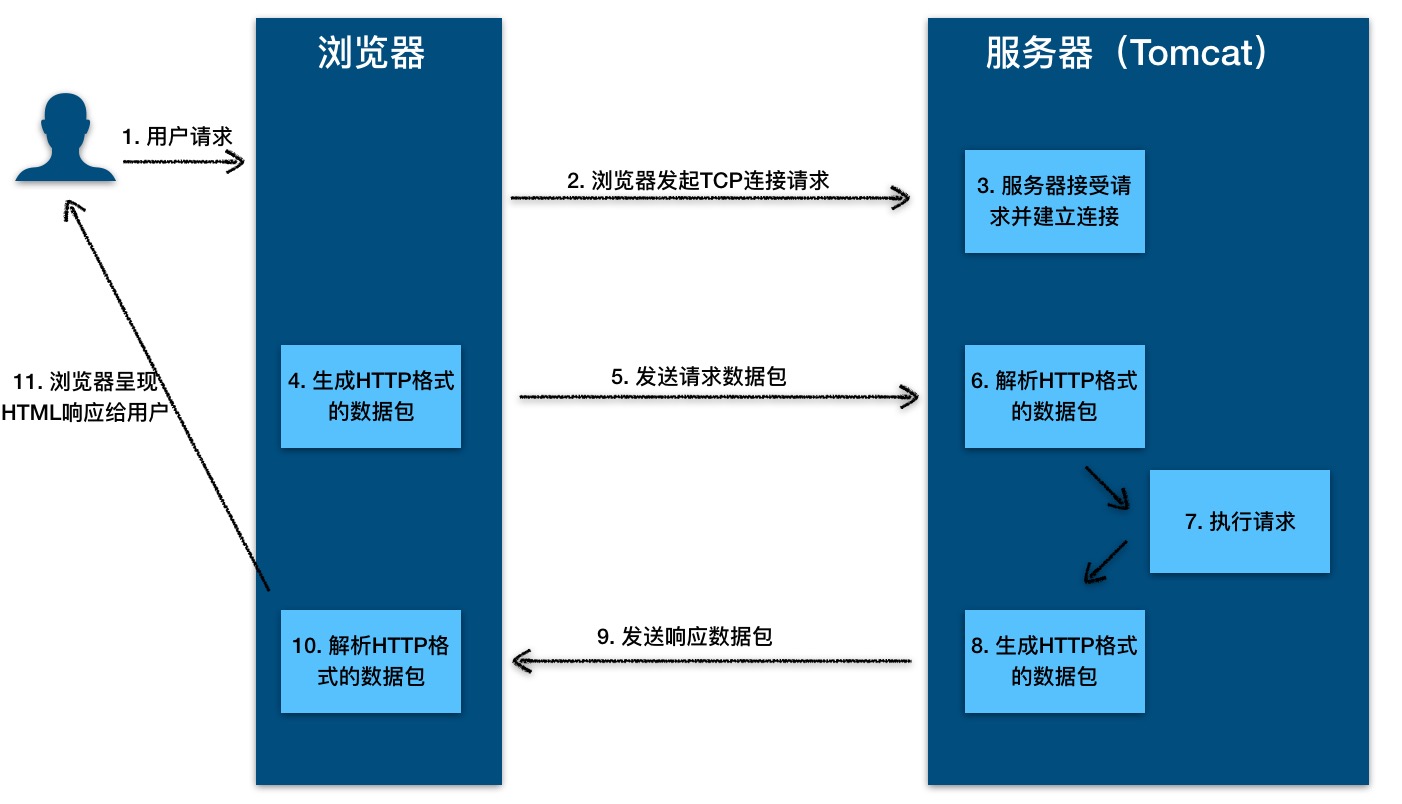
一、Selenium是什么?
二、使用步骤
1.引入库
2.下载浏览器驱动
3.配置浏览器驱动
4.创建WebDriver对象
4.1.options
4.2.service
4.3.desired_capabilities
4.4.executable_path
5.WebDriver的属性
6.元素定位
三.打开百度网页的简单示例
总结
一、Selenium是什么?
Selenium是一个用于自动化浏览器操作的Python库,常用于Web应用的测试和爬虫等场景。
二、使用步骤
1.引入库
安装Selenium库:使用pip命令安装Selenium库。可以运行以下命令进行安装:
pip install selenium==4.5目前有更高版本4.10,但是高版本有些参数被改了或舍弃了,使用起来要自己去找官方文档,不方便。而且过高的Selenium版本和Chrome浏览器版本不兼容,之前用的selenium4.10打开chrome浏览器会秒退,后来将版本换为4.5就解决了 。
2.下载浏览器驱动
Selenium需要使用浏览器驱动来控制浏览器。这里以ChromeDriver为例,下载地址为:https://chromedriver.storage.googleapis.com/index.html
根据自己的Chrome版本进行下载
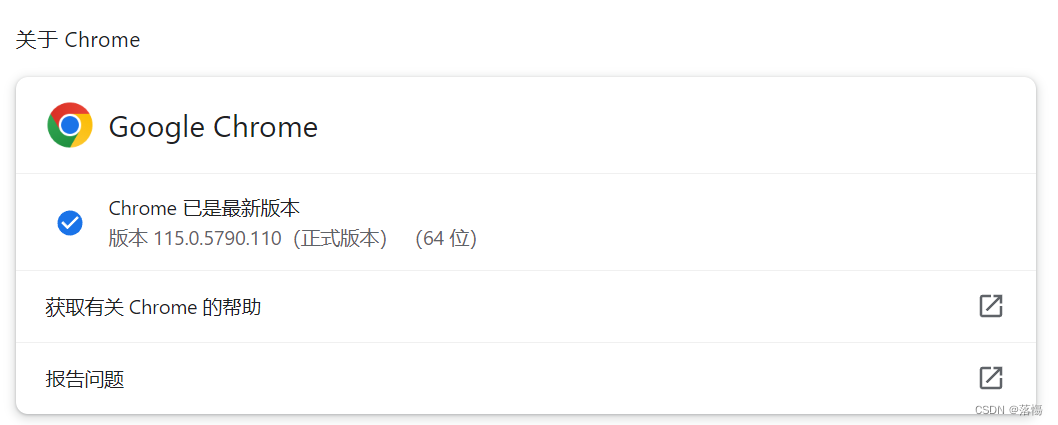

我的是版本到了115,但是ChromeDriver目前只有114的,选最新的版本,目前没遇见问题。
3.配置浏览器驱动
将下载的chromedriver.exe文件放置在与你的Python脚本相同的目录下

并将浏览器驱动添加到系统的环境变量中,或将其路径配置为Selenium的WebDriver对象的参 数,在计算机上搜索高级系统设置->环境变量->path->新建->复制路径->确定。

4.创建WebDriver对象
使用Selenium的WebDriver对象来控制浏览器。根据使用的浏览器类型和驱动的配置,创建对应 的WebDriver对象。
from selenium import webdriver
# 创建Chrome浏览器的WebDriver对象
driver = webdriver.Chrome() webdriver.Chrome的常用参数
4.1.options
一个Options对象,用于配置Chrome浏览器的选项。你可以使用该对象来设置浏览器窗口大小、启用/禁用浏览器的扩展程序、设置用户代理等等。
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--start-maximized') # 最大化窗口
options.add_argument('--disable-extensions') # 禁用扩展程序
driver = webdriver.Chrome(options=options)4.2.service
一个Service对象,用于配置和启动ChromeDriver服务。如果没有显式指定,它将搜索系统的PATH环境变量来找到ChromeDriver服务。
from selenium.webdriver.chrome.service import Service
service = Service('chromedriver.exe')
driver = webdriver.Chrome(service=service)4.3.desired_capabilities
一个字典,用于设置WebDriver的所需能力。你可以使用该字典来设置浏览器的版本、操作系统、浏览器名称等等。
caps = {'browserName': 'chrome', 'version': '', 'platform': 'ANY'}
driver = webdriver.Chrome(desired_capabilities=caps)4.4.executable_path
指定Chrome驱动的路径。如果没有显式指定,它将搜索系统的PATH环境变量来找到Chrome驱动程序。貌似被弃用了,我使用的时候报出警告了,用第二个service替换就行了。
5.WebDriver的属性
# 打开指定的网页
driver.get("https://www.baidu.com")
#获取当前页面的URL
current_url = driver.current_url
#获取当前页面的标题
title = driver.title
#获取当前页面的源代码
page_source = driver.page_source
#获取当前打开的所有窗口的句柄
window_handles = driver.window_handles
#获取当前窗口的句柄
current_window_handle = driver.current_window_handle
#获取当前WebDriver的所需能力
desired_capabilities = driver.desired_capabilities
#获取当前WebDriver的能力
capabilities = driver.capabilities6.元素定位
Selenium提供了多种元素定位的方法,可以根据元素的属性、文本、位置等进行定位。以下是一些常用的元素定位方法:
旧版的selenium使用方法:
#通过id定位元素
element = driver.find_element_by_id("element-id")
#通过class name定位元素
element = driver.find_element_by_class_name("element-class")
#通过name属性定位元素
element = driver.find_element_by_name("element-name")
#通过tag name定位元素
element = driver.find_element_by_tag_name("element-tag")
#通过链接文本定位元素
element = driver.find_element_by_link_text("link-text")
#通过部分链接文本定位元素
element = driver.find_element_by_partial_link_text("partial-link-text")
#通过CSS选择器定位元素
element = driver.find_element_by_css_selector("css-selector")
#通过XPath表达式定位元素
element = driver.find_element_by_xpath("xpath-expression")新版的selenium有两种定位方式,element = driver.find_element("id", "element-id")和element = driver.find_element(By.ID,"su") 这两种方式本质上是等效的,都是通过元素的id属性进行定位。第一种方式中,使用了字符串来表示定位策略,而第二种方式中,使用了By类来表示定位策略。By类是Selenium提供的一组常用的定位策略,用于更清晰地表示定位方式。通过使用By类,可以让代码更易读且具备更好的可维护性。
from selenium.webdriver.common.by import By
# 第一种方式:使用定位策略和定位值定位元素
element1 = driver.find_element("id", "element-id")
element1 = driver.find_element("name", "element-name")
# 第二种方式:使用By类结合定位策略定位元素
element2 = driver.find_element(By.ID, "element-id")
element2 = driver.find_element(By.NAME, "element-name")其余旧版的定位方法都可用转换成这两种方式
三.打开百度网页的简单示例
该示例演示了如何获取百度页面的源码,如何在百度搜索框里输入信息并点击查找 。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
#chromedriver.exe要与该python文件放在同一个目录下
service = Service("chromedriver.exe")
options = Options()
#初始窗口最大化
options.add_argument('--start-maximized')
driver = webdriver.Chrome(service=service, options=options)
url = "https://www.baidu.com"
driver.get(url)
#获取网页的源码
content = driver.page_source
print(content)
#根据id定位到百度搜索的输入框
input = driver.find_element(By.ID,"kw")
#在输入框中输入Python
input.send_keys('Python')
time.sleep(2)
#根据id定位到百度一下的按钮
button = driver.find_element(By.ID,"su")
#按钮点击一下
button.click()
time.sleep(2)
#执行JavaScript脚本,该脚本表示鼠标滚轮滑动到距离顶部100000,即滑动到底部
js_button = 'document.documentElement.scrollTop=100000'
driver.execute_script(js_button)
time.sleep(2)
#根据Xpath表达式定位下一页的按钮,并点击一下
next_page = driver.find_element(By.XPATH,"//a[@class='n']")
next_page.click()
time.sleep(2.1)
#网页后退
driver.back()
time.sleep(1.5)
#网页前进
driver.forward()
time.sleep(1.8)
#网页关闭
driver.quit()
文章来源:https://uudwc.com/A/8dnVY
总结
新手上路,请多指教;如有错误,请多包涵。文章来源地址https://uudwc.com/A/8dnVY