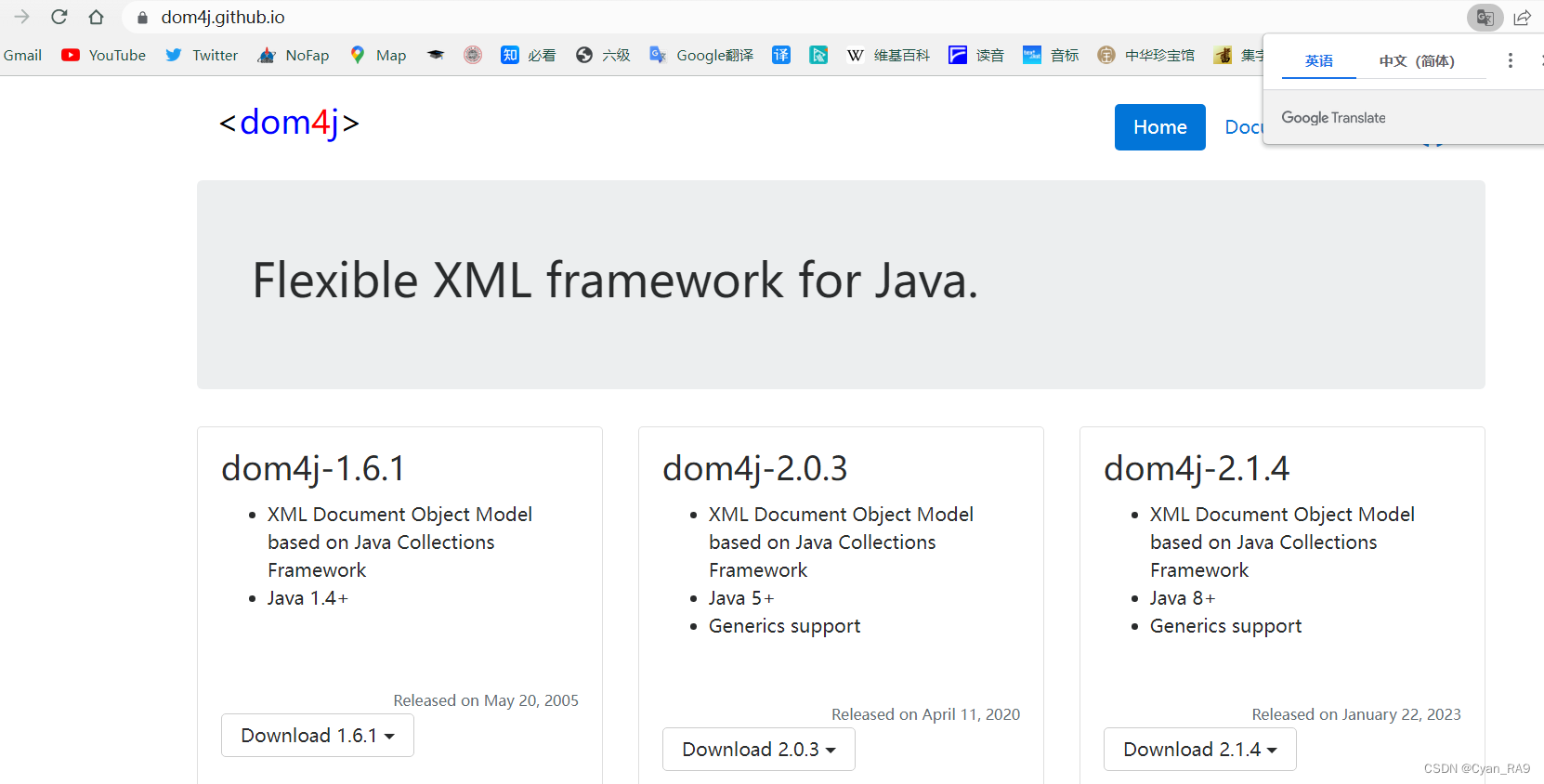
一 数据库读写分离

适应场景:互联网读多写少。
原理:主机负责写,从机可以多个负责读取。数据主从做同步。
业务的写发给主机,读操作发给从机。
条件:1业务量增长 2 其他优化条件已处理(索引优化、缓存)等再重构。
代价:1 复制延迟 2 任务分解
任务分解本身是 为了引入读写分离做的改造。为了避免复制延迟影响业务不一致。
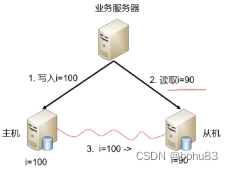
通常方式,关键业务(比如订单、支付)读写全部指向主机,非关键业务采取读写分离。
这是一种折中,定了软件架构规范后,开发、测试会关注到这个点,后续的代码review也可以二次校验。
落地的模式:代码封装模式与中间件proxy模式

二数据库的分库分表
适应场景:主机节点写入性能瓶颈

分库带来的挑战: join 查询,要么冗余数据,要么在代码实现join 功能(内存做关联)
事务问题:使用分布式事务。如库存与订单
分表:垂直拆分
这种通常是字段多的表,抛去大字段,有的大表100来个字段,这种明显比常见的10来个 字段要慢。
水平拆分:提示系统的性能。
大表1000w条可以考虑拆分。这个经验数据。也有是2000w的。
水平拆分难度在于拆分规则的确定,也就是路由。因为其他的框架shardingsphere都帮你实现好了
常见的用户的维度、商家的维度异构方式。常见的采取冗余策略。双写啊,消息等都可以。
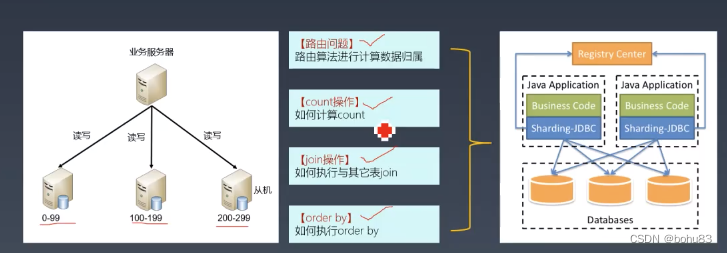
还有个挑战:怎么进行数据迁移。还有弹性扩容的问题
数据库分布式事务文章来源:https://uudwc.com/A/9LYMm
简单的提了下2pc,3pc 文章来源地址https://uudwc.com/A/9LYMm