文章目录
- 3.1 数据库模式
- 3.1.1 三级模式 两级映射
- 3.1.2 数据库设计过程
- 3.2 ER模型
- 3.3 关系代数与元组演算
- 3.3.1 关系代数
- 3.3.2 函数依赖
- 3.4 规范化理论
- 3.4.1 价值和用途
- 3.4.2 求候选关键字
- 3.4.3 范式
- 3.4.4 模式分解
- 3.5 并发控制
- 3.5.1 基本概念
- 3.5.2 并发产生的问题
- 3.5.3 解决对策
- 3.5.4 共享锁(S锁)和排它锁(X锁)
- 3.6 数据库完整性约束
- 3.7 数据库安全
- 3.7 数据库备份
- 3.8 数据仓库与数据挖掘
- 3.8 反规范化
- 3.9 大数据
3.1 数据库模式
3.1.1 三级模式 两级映射
- 内模式直接与物理数据库相关联的 定义了数据存放的格式及方式
- 概念模式即模式,类似于数据库的表
- 外模式对应的是数据库的视图

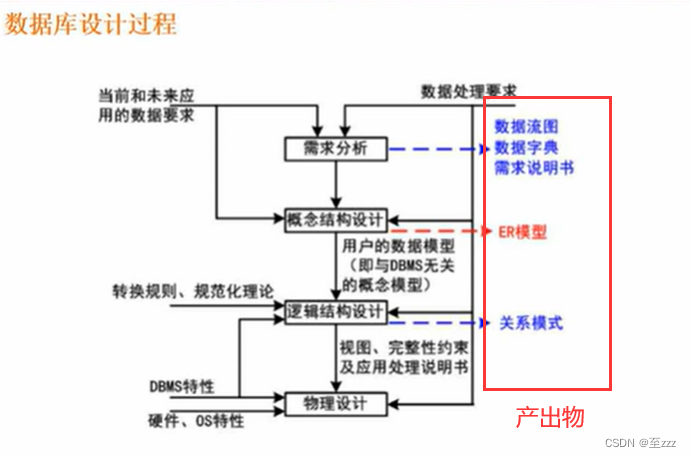
3.1.2 数据库设计过程
3.2 ER模型
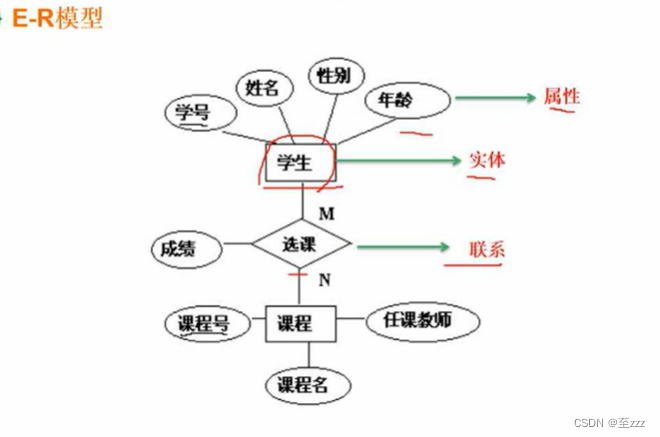
方框:实体;椭圆:属性;菱形:联系

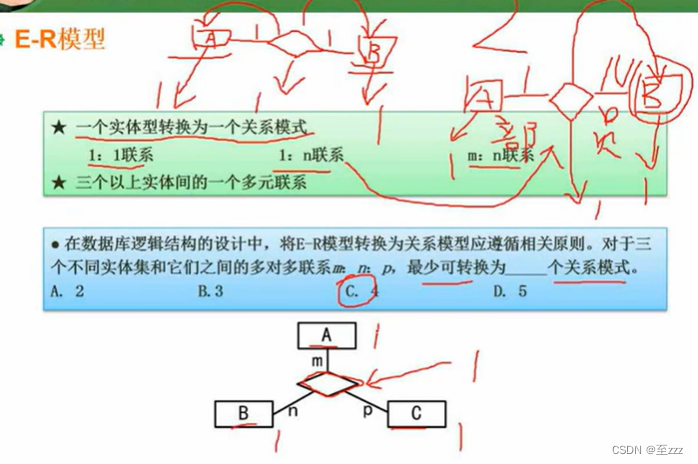
每个实体可转1个关系模式,多对多的时候,每个联系也可转成一个单独关系模式
3.3 关系代数与元组演算
3.3.1 关系代数
并、交、差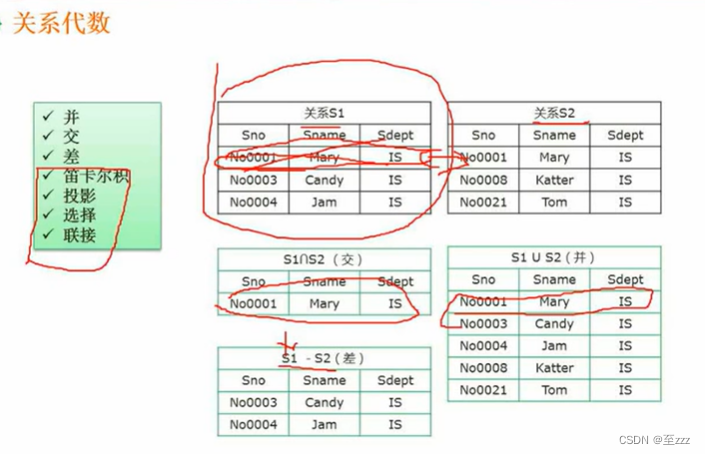
笛卡尔积、投影、选择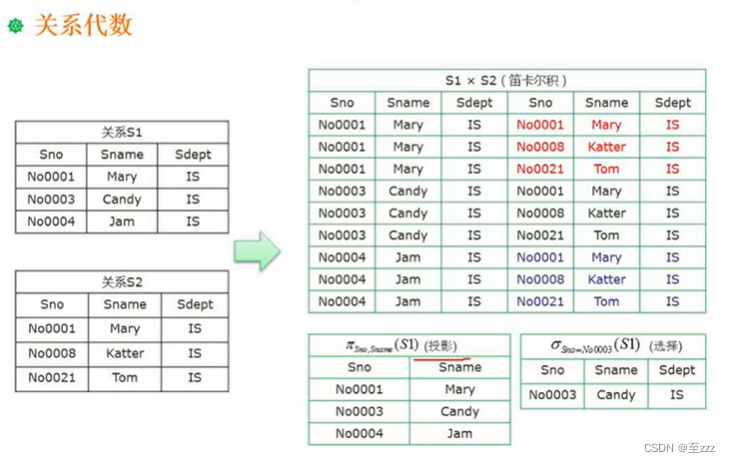
笛卡尔积将两个表的行分别组合,会存在相同的字段。
投影是按列选出,选择是按行选出。
联接
联接不会存在相同字段
3.3.2 函数依赖
学号可以唯一确定姓名,但姓名不能确定学号,可能会存在同名,我们把学号->姓名这个过程称为函数依赖

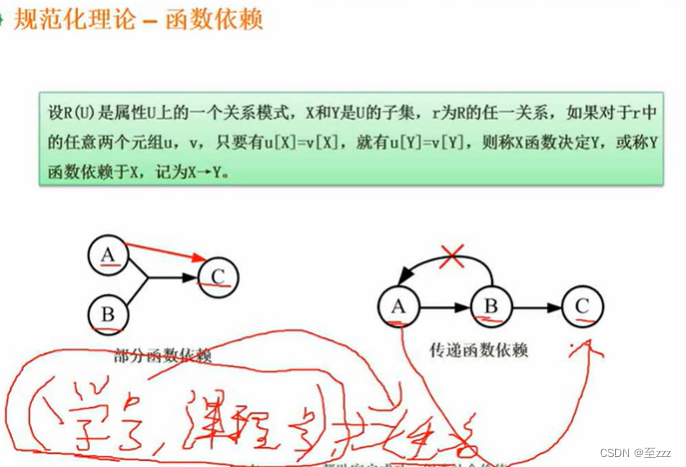
部分函数依赖:学号和课程号共同可以确定姓名,且其中之一学号也可以确定姓名。
传递函数依赖:A可以唯一确定B,B可以唯一确定C,则A可以确定C。但是要注意的是B不能确定A,否则A与B就是等值关系。
3.4 规范化理论
3.4.1 价值和用途
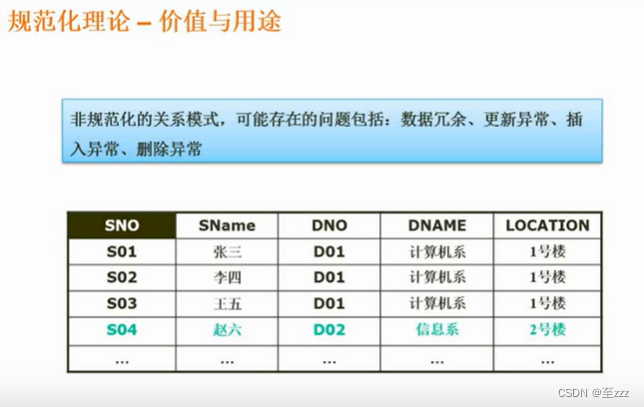
数据冗余:如上图DNO可以唯一确定DNAME,但是仍存储了大量的DNAME。
更新异常:在不更改DNO的情况下更新DNAME时,如果没有全部更新,就会存在更新异常
3.4.2 求候选关键字
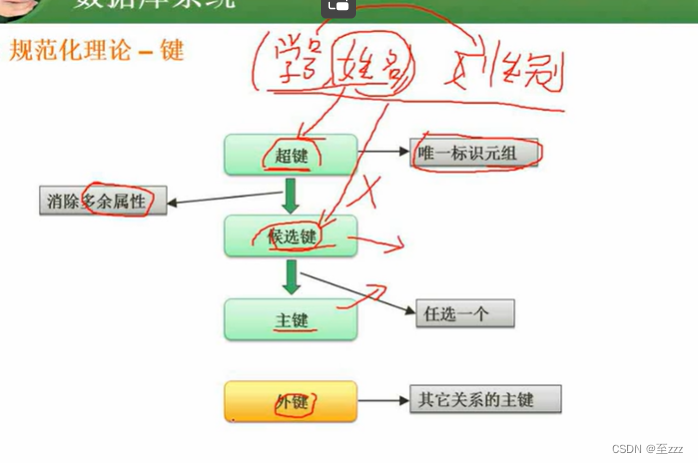
如上图,学号和姓名的组合键可以称之为超键,但其组合键不能称之为候选键,因为姓名是冗余的,学号可以单独成为候选键。

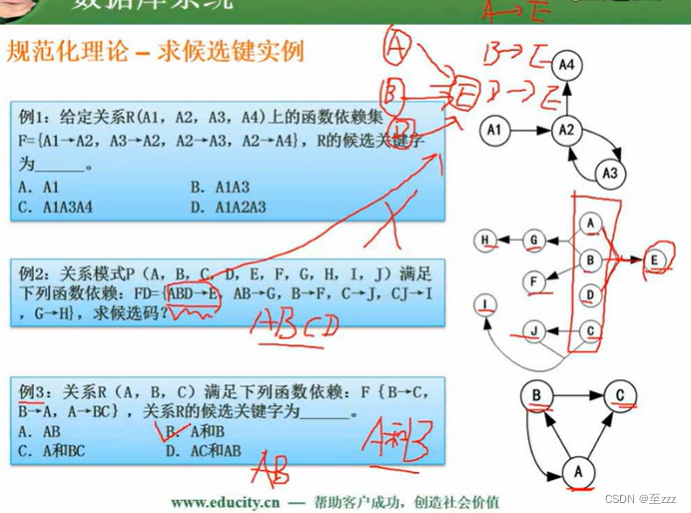
求候选键的步骤:
- 将函数依赖转为有向图。
- 找入度为0的节点,能遍历所有节点的就是候选键。
- 若没有入度为0的节点,寻找既有入度也有出度的节点,能遍历所有节点即为候选键。
3.4.3 范式
主属性:属于候选键的一部分的是主属性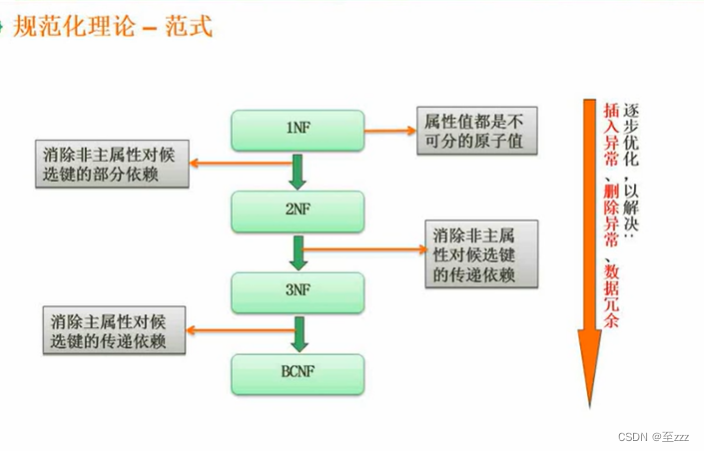
转:范式越来越高,则表拆分越细,实现越难、性能越慢、越没体现数据解耦。一般拆分到第三范式就差不多了。
原子值:一个属性不能拆分成多个属性。
第一范式
每个分量都是不可再分的数据项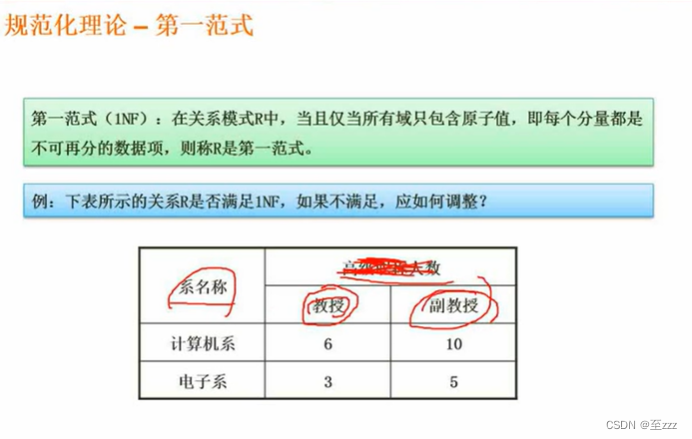
该表不满足第一范式,高级职称人数可以继续拆分成教授与副教授。
第二范式
非主属性不存在部分依赖于主属性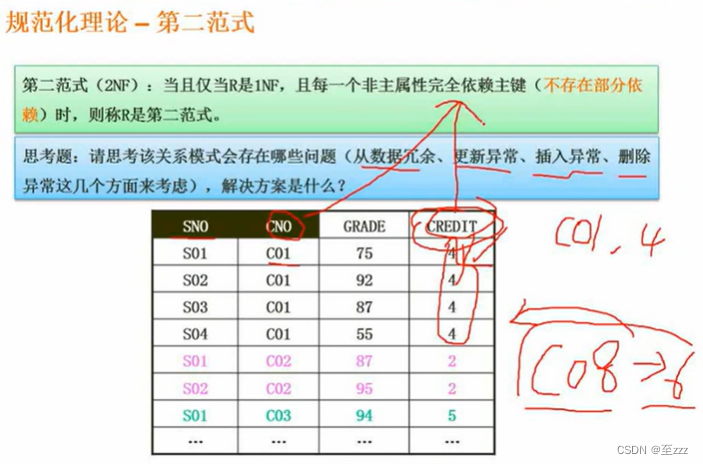
上表不满足第二范式,其CNO可以确定CREDIT,但是CNO只是主键的一部分,存在部分依赖。解决办法就是继续拆分。
第三范式
非主属性不存在传递依赖于主属性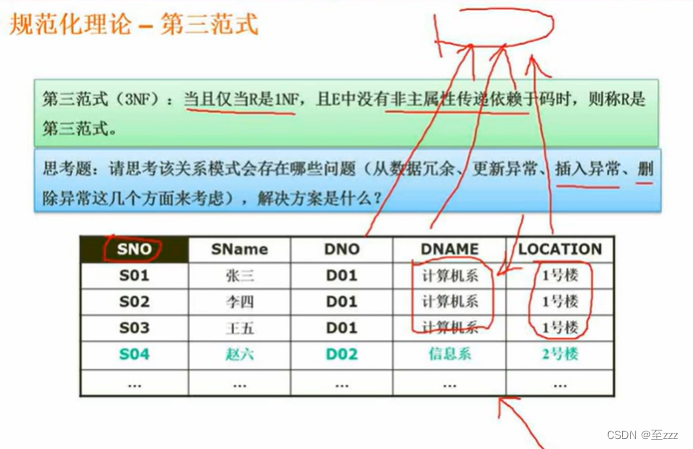
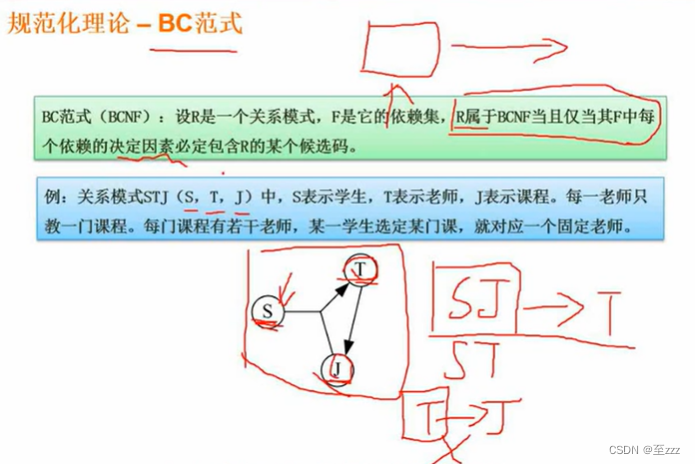
BC范式
通俗的来说就是函数依赖的左边必须是候选键
练习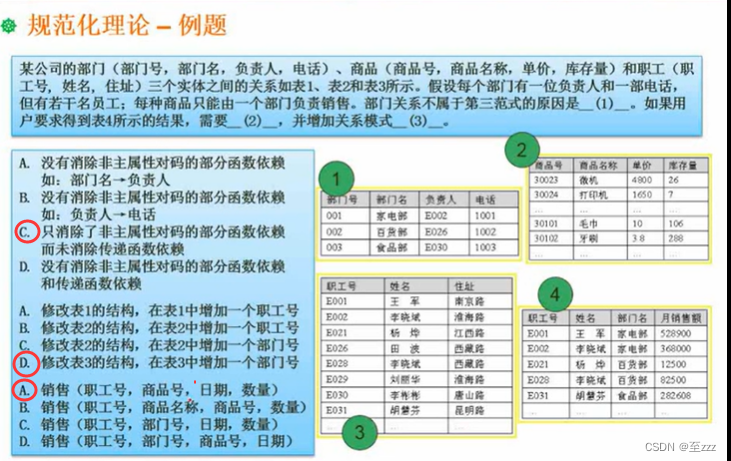
第二题中部门和职工之间并未存在关系,且遵循多对一原则,在职工表添加部门号即可。
3.4.4 模式分解

案例分析
判断以下是否为无损分解
方式一
方式二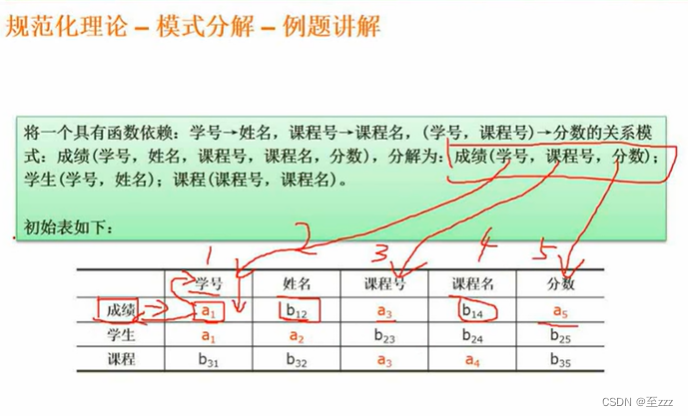
列表,横属性为被拆分的表的属性,纵属性为拆分的表
- 如上,成绩中包含了学号,课程,分数,则将其标位a
- 其余的标为b
- 将有两个相邻的a的整列都标为a
- 如果有一行全为a,则为无损分解
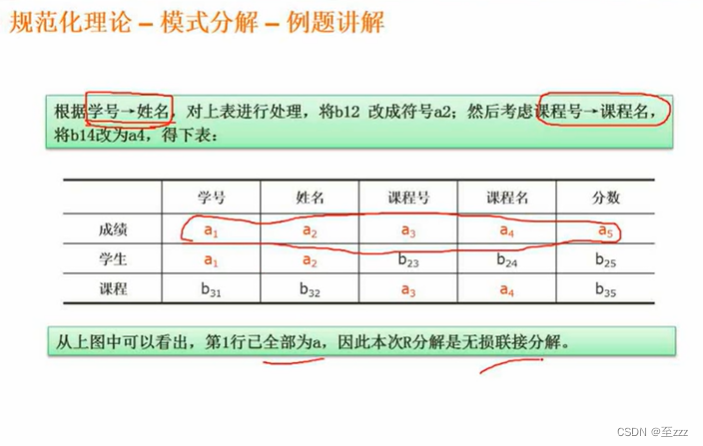
方式三
局限于分解为两个
3.5 并发控制
3.5.1 基本概念
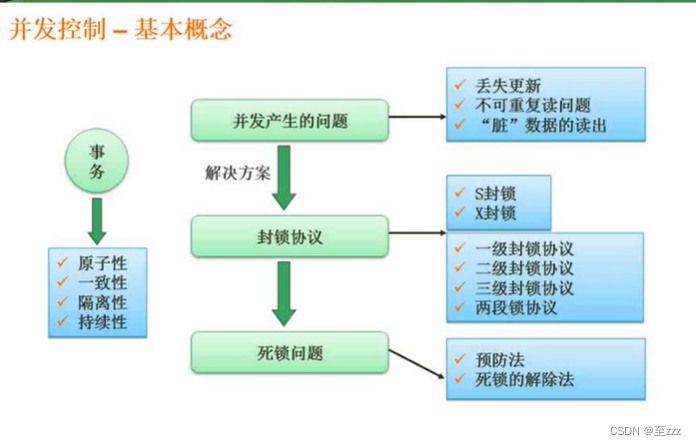
事务的四大特性(ACID):原子性、一致性、隔离性、持久性
3.5.2 并发产生的问题
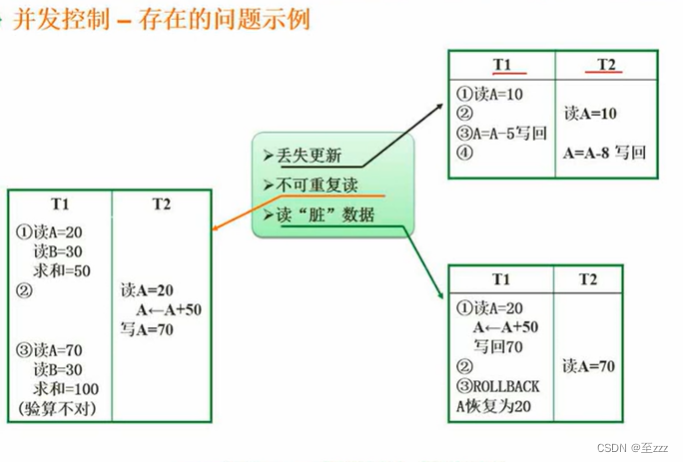
如上图,T1、T2两个事务
- 丢失更新:两个事务先后对A进行减5和减8的操作,但是实际上减8的结果会将减5的结果覆盖。
- 不可重复读:在进行求和之后可能会对其进行验算,但此时T2对A进行更新了,验算结果不对,造成不可重复读。
- 读“脏”数据:T1对A进行更新,但进行了回滚,在此途中,T2读取的是回滚前的数据,这就是脏读。
3.5.3 解决对策

S锁是读锁(共享锁),X锁是写锁(排它锁)。加了s锁后还可以继续加s锁,但是不能加x锁
- 一级封锁协议:对于丢失更新,加一级封锁协议,即在事务修改数据前对其加X锁,直到事务结束才释放。
- 二级封锁协议:在一级之上先对其加s锁,读完后释放s锁。可防止丢失更新、脏读。
- 三级封锁协议:在一级之上先对其加s锁,事务结束后才释放s锁。可防止丢失更新、脏读、重复读。
- 两段锁协议:可串行,可能会发生死锁(解除或预防)。
3.5.4 共享锁(S锁)和排它锁(X锁)
排他锁(Exclusive Locks,简称X锁)
- 排他锁又称为写锁,用于对数据进行写操作时进行锁定。如果事务T对数据A加上X锁后,就只允许事务T读取和修改数据A,其他事务对数据A不能再加任何锁,从而也不能读取和修改数据A,直到事务T释放A上的锁。
共享锁(Share Locks,简称S锁)
- 共享锁又称为读锁,用于对数据进行读操作时进行锁定。如果事务T对数据A加上了S锁后,事务T就只能读数据A但不可以修改,其他事务可以再对数据A加S锁 来读取,只要数据A上有S锁,任何事务都只能再对其加S锁(读取)而不能加X锁 (修改)。
3.6 数据库完整性约束

数据完整性:存储在数据库中的所有数据值均正确的状态。它是应防止数据库中存在不符合语义规定的数据和防止因错误信息的输入输出造成无效操作或错误信息而提出的。
数据完整性分为四类:
- 实体完整性(实体完整性是对关系中的记录唯一性,也就是主键的约束。准确地说,实体完整性是指关系中的主属性值不能为Null且不能有相同值。定义表中的所有行能唯一的标识,一般用主键,唯一索引 unique关键字,及identity属性比如说我们的身份证号码,可以唯一标识一个人.。)
- 域完整性(域完整性是对数据表中字段属性的约束,通常指数据的有效性,它包括字段的值域、字段的类型及字段的有效规则等约束,它是由确定关系结构时所定义的字段的属性决定的。限制数据类型,缺省值,规则,约束,是否可以为空,域完整性可以确保不会输入无效的值.。)
- 参照完整性(参照完整性是对关系数据库中建立关联关系的数据表间数据参照引用的约束,也就是对外键的约束。准确地说,参照完整性是指关系中的外键必须是另一个关系的主键有效值,或者是NULL。参考完整性维护表间数据的有效性,完整性,通常通过建立外部键联系另一表的主键实现,还可以用触发器来维护参考完整性)
- 用户定义的完整性。
约束是表级的强制规定,有以下五中:not null,unique,primary key,foreign key,check
原文链接:https://blog.csdn.net/u013634252/article/details/80696882
更加复杂的会采用触发器完成。
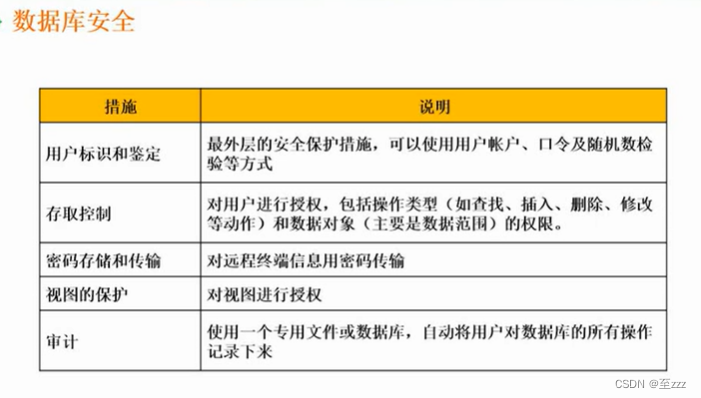
3.7 数据库安全
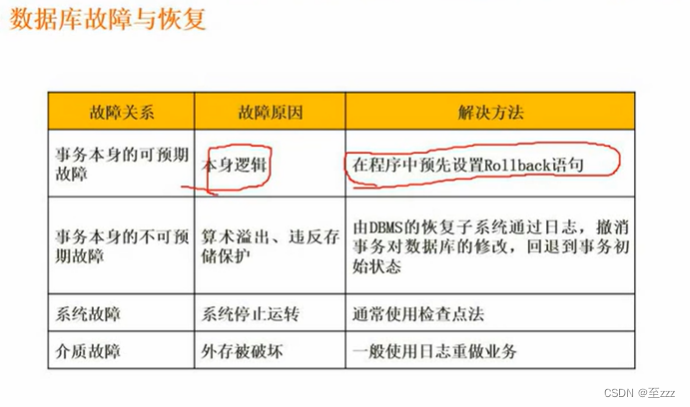
3.7 数据库备份


3.8 数据仓库与数据挖掘


3.8 反规范化

规范化以时间换空间,反规范化以空间换时间文章来源:https://uudwc.com/A/AAXqg
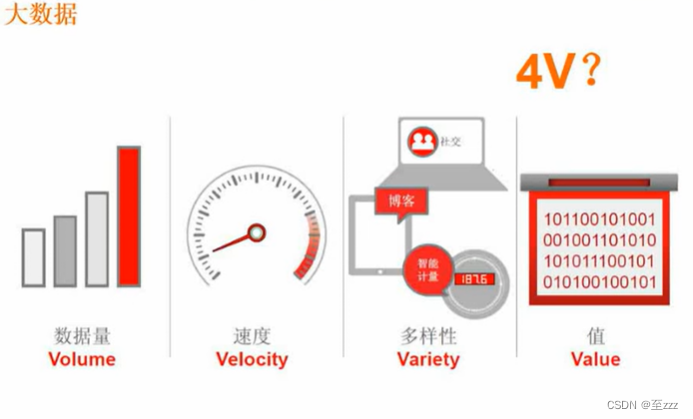
3.9 大数据
 文章来源地址https://uudwc.com/A/AAXqg
文章来源地址https://uudwc.com/A/AAXqg