This is my first blog written in English. I don’t mean to show my English skills. To be honest, there are two main reasons.
First, it is quite inconvenient to switch between Chinese and English frequently.
Second, I plan to study abroad. So it is a good chance to adopt another writing manner.
>I would appreciate it if you could point out my mistakes or correct my mistakes.
Okay, let us start this unnormal journey!
SQL language classification
The Structured Query Language is known as SQL;
- Data Definition Language: DDL ?
- Data Definition Language(e.g. create,drop,alter)
- Transaction Control Language(e.g. commit,rollback)
- Data Control Language(e.g. grant,revoke)
- Data Manipulation Language
- DML (e.g. insert,update,delete)
- Data Query Language(e.g. select)
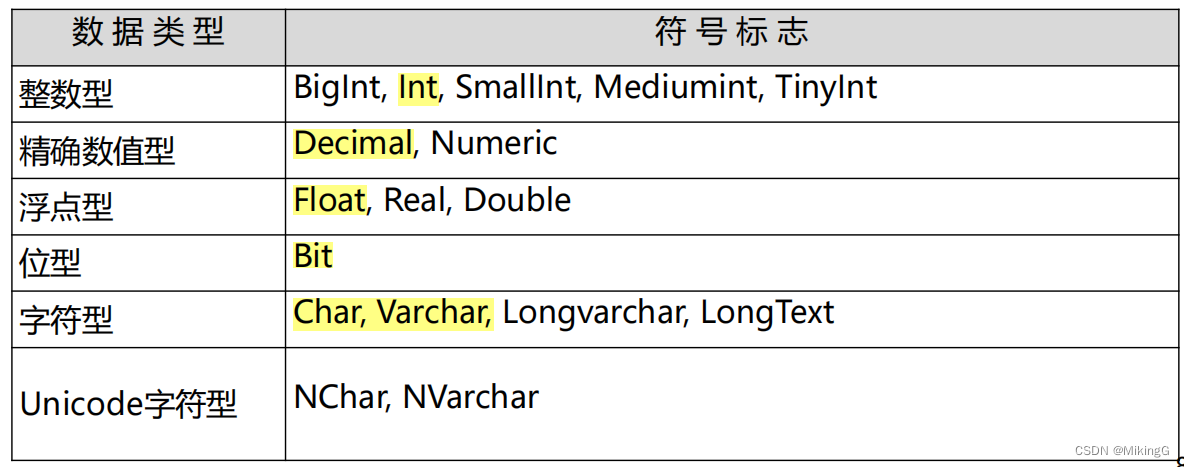
SQL data classification
- precision: The total number of digits.
- Decimal places: The maximum number of digits that can be to the right of the decimal point in numeric data.
- Length: The number of bytes used to store the data.
For example, the numerical data 3560.697 has a precision of 7, and the number of decimal places is 3.
I find that there is no need to “translate” class PPT.
So I decided to summarize key points only.
integer type
- bigint>interger(abbr. int)>mediumint>smallint>tinyint
accurate numerical type
- decimal, numeric
float type
- float, double
bit type
char type
text type
binary and var binary type
blob type
date time type
enum and set type
SQL data definition language
database operation
- create database [if not exists] db_name;
NOTE: MySQL is case-insensitive;
NOTE: [optional]
- use db_name;
- drop database [if exists] db_name;
- show database;
SQL schema definition
schema
creates a schema with the name “my_schema” and specifies the owner or authorized user as “my_user”:
CREATE SCHEMA my_schema AUTHORIZATION my_user;
Without Schemas:
CREATE TABLE books (
book_id INT PRIMARY KEY,
title VARCHAR(255),
author VARCHAR(255)
);
CREATE TABLE members (
member_id INT PRIMARY KEY,
name VARCHAR(255),
email VARCHAR(255)
);
In this scenario, you have two tables, “books” and “members,” which are directly created in the default schema (usually “public” in some database systems). It can become challenging to manage and distinguish between different types of objects as the database grows.
With Schemas:
CREATE SCHEMA library;
-- Create tables within the "library" schema
CREATE TABLE library.books (
book_id INT PRIMARY KEY,
title VARCHAR(255),
author VARCHAR(255)
);
CREATE TABLE library.members (
member_id INT PRIMARY KEY,
name VARCHAR(255),
email VARCHAR(255)
);
In this example:
We first create a schema called “library” using CREATE SCHEMA.
Then, we create two tables, “books” and “members,” within the “library” schema. This organizes the tables neatly within the “library” namespace.
domain
create a user-defined data type (domain).
-- Create a domain for storing positive integers
CREATE DOMAIN PositiveInteger AS INTEGER
CHECK (VALUE > 0);
-- Create a table using the PositiveInteger domain
CREATE TABLE Employee (
employee_id PositiveInteger,
employee_name VARCHAR(50)
);
-- Insert data into the Employee table
INSERT INTO Employee (employee_id, employee_name)
VALUES (1, 'John Smith');
-- This will fail due to the CHECK constraint in the domain
INSERT INTO Employee (employee_id, employee_name)
VALUES (-1, 'Jane Doe');
When inserting data into the “Employee” table, the first insertion is successful because the value (1) is a positive integer, while the second insertion fails due to the CHECK constraint violation.
Create a table/view
CREATE TABLE Clause:
create a table within the schema.
CREATE TABLE my_table (
id INT PRIMARY KEY,
name VARCHAR(255)
);
CREATE VIEW Clause:
create a view within the schema.
CREATE VIEW my_view AS
SELECT id, name FROM my_table WHERE id > 100;
drop schema
Example 1: DROP SCHEMA with CASCADE
Suppose you have a schema named “my_schema” that contains various objects like tables, views, and functions, and you want to drop the schema along with all the objects it contains using the CASCADE option:
DROP SCHEMA my_schema CASCADE;
In this example, the CASCADE option ensures that all objects within the “my_schema” schema will be dropped along with the schema itself.
Example 2: DROP SCHEMA with RESTRICT
Suppose you have a schema named “my_empty_schema” that is empty (contains no objects), and you want to drop the schema without checking for objects or dependencies. You can use the RESTRICT option:
DROP SCHEMA my_empty_schema RESTRICT;
In this example, the RESTRICT option will only allow dropping the schema if it’s empty. If there were any objects within the schema, the DROP SCHEMA statement would fail.
table operation
create [temporary] table [if not exists] table_name
{
-- column_name data_type [column_options]
SNo VARCHAR(10) NOT NULL PRIMARY KEY COMMENT 'Student Number',
SName VARCHAR(30) NOT NULL COMMENT 'Student Name',
Sex INT NULL DEFAULT 1 COMMENT 'Student Gender (1 for Male, 0 for Female)'
-- table_options
}
column options
- null/ not null
- default default_value
- auto_increment
- unique key/primary key
- The primary key contains the feature of uniqueness while the unique key just is unique.
- comment ‘string_description’
table options
Adding an Index:
Suppose you want to add an index to the “order_date” column in the “orders” table. You can do it like this:
CREATE TABLE orders (
order_id INT NOT NULL,
customer_id INT NOT NULL,
order_date DATE,
-- Other columns for order details
PRIMARY KEY (order_id, customer_id),
INDEX idx_order_date (order_date)
);
Adding a Primary/Foreign Key:
Suppose you have another table called “customers,” and you want to create a foreign key relationship between “orders” and “customers” based on the “customer_id” column. You can define it like this:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(50)
);
CREATE TABLE orders (
order_id INT NOT NULL,
customer_id INT NOT NULL,
order_date DATE,
-- Other columns for order details
PRIMARY KEY (order_id, customer_id),
INDEX idx_order_date (order_date),
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
alter the table structure
add attribute column:
alter table table_name
add column_name data_type [column_option]
drop attribute column:
alter table table_name
drop column_name [cascade|restrict]
- cascade drops all related to this attribute.
- restrict drops this attribute only if there is no view or constraint referred to in this column.
Modify column type/width
Alter table table_name
modify column_name new_data_type
Add definition of primary/foreign key
alter table table_name
add primary key (column_name1,column_name2,...);
alter table table_name
add foreign key(column_name) references table_name2(column_name)
drop table
drop table
-- drop [temporary] table [if exists] table_name1 [, table_name2]...
drop table score_info;
insert table data
insert [into] table_name [(col_name, …)]
values (expr|default), …);
- expr: A constant value, null, a variable value or an expression.
- default: The precondition is that this column has been specified as a default value.
INSERT INTO products (product_id, product_name, unit_price, quantity, total_price)
VALUES (5, 'Widget E', 9.99, 200, unit_price * quantity);
update table data
update table_name
set col_name1=expr1 [,col_name=expr2, …]
[where where_definition]文章来源:https://uudwc.com/A/AAkMO
UPDATE employees
SET emp_salary = 55000
WHERE emp_name = 'John';
Delete table data
delete from table_name
[where where_definition]文章来源地址https://uudwc.com/A/AAkMO
delete form course_info
where term != 5;
Summary
| table structure | table data |
|---|---|
| alter table table_name add | insert table_name values(…) |
| alter table table_name modify id bigint | update table_name set col_name=expr [where…] |
| drop table [if exists] table_name | delete form table_name [where …] |
-- operation on table data
insert stu_info (id,GPA,tel) values(123456,(score-50)/10,default);
update stu_info set score=100 where id=666;
delete from stu_info where score<60;
-- operation on table structure
create temporary table if not exists stu_info
{
id int primary key auto_increment,
GPA float default 0.0,
num int auto increament,# just an example for clarifying the grammer
};

