一、配置环境
1.下载selenium
官网链接:Downloads | Selenium
Chrome浏览器驱动下载链接:ChromeDriver Mirror
2.解压

3.添加环境变量PATH
4.安装selenium
conda install selenium
pip install selenium
5.安装webdriver_manager

二、打开百度进行测试
1.进入搜索界面
from selenium import webdriver
driver=webdriver.Chrome('E:\\1111\\chromedriver_win32\\chromedriver.exe')
#进入网页
driver.get("https://www.baidu.com/")
2.按F12进入检查

可以发现搜索框的id是kw
找到该元素,并填取对应的值
p_input = driver.find_element_by_id("kw")
p_input.send_keys('TT17')
同样检查网页找到按钮百度一下的id,为su
点击该按钮
p_btn=driver.find_element_by_id("su")
p_btn.click()
三、爬取网页上的名言名句
1.检查网页,发现名言的id是text
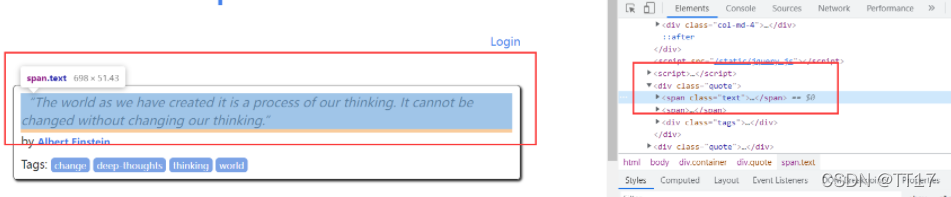
2.作者的id是author

3.代码
#爬取指定网页http://quotes.toscrape.com/js/的名言
from bs4 import BeautifulSoup as bs
from selenium import webdriver
import csv
from selenium.webdriver.chrome.options import Options
from tqdm import tqdm#在电脑终端上显示进度,使代码可视化进度加快
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome('D:\\下载软件\\chromedriver_win32\\chromedriver.exe')
driver.get('http://quotes.toscrape.com/js/')
#定义csv表头
quote_head=['名言','作者']
#csv文件的路径和名字
quote_path='C:\\Users\\ASUS-JH\\quote_csv.csv'
#存放内容的列表
quote_content=[]
'''
function_name:write_csv
parameters: csv_head,csv_content,csv_path
csv_head: the csv file head
csv_content: the csv file content,the number of columns equal to length of csv_head
csv_path: the csv file route
'''
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
print('爬取信息成功')
###
#可以用find_elements_by_class_name获取所有含这个元素的集合(列表也有可能)
#然后把这个提取出来之后再用继续提取
quote=driver.find_elements_by_class_name("quote")
#将要收集的信息放在quote_content里
for i in tqdm(range(len(quote))):
quote_text=quote[i].find_element_by_class_name("text")
quote_author=quote[i].find_element_by_class_name("author")
temp=[]
temp.append(quote_text.text)
temp.append(quote_author.text)
quote_content.append(temp)
write_csv(quote_head,quote_content,quote_path)
4.运行结果:

5.运行结果
 四、爬取图书
四、爬取图书
1. 打开淘宝F12进入检查,查看ID
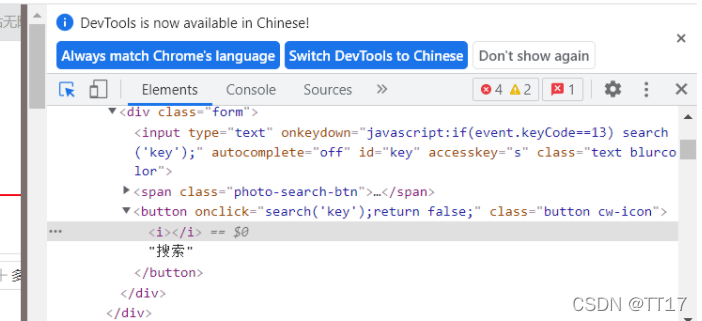
3.这里是价格,名称,出版社或店铺等的标签

4.代码
from selenium import webdriver
import time
import csv
from tqdm import tqdm#在电脑终端上显示进度,使代码可视化进度加快
from webdriver_manager.chrome import ChromeDriverManager
import csv
driver = webdriver.Chrome('D:\\下载软件\\chromedriver_win32\\chromedriver.exe')
#加载页面
driver.get("https://www.jd.com/")
time.sleep(4)
#定义存放图书信息的列表
goods_info_list=[]
#爬取200本
goods_num=200
#定义表头
goods_head=['价格','名字','链接','出版社或店铺']
#csv文件的路径和名字
goods_path='C:\\Users\\ASUS-JH\\信号与系统.csv'
#向输入框里输入Java
p_input = driver.find_element_by_id("key")
p_input.send_keys('信号与系统')
#button好像不能根据类名直接获取,先获取大的div,再获取按钮
from_filed=driver.find_element_by_class_name('form')
s_btn=from_filed.find_element_by_tag_name('button')
s_btn.click()#实现点击
#获取商品价格、名称、链接、获取出版社或店铺
def get_prince_and_name(goods):
#直接用css定位元素
#获取价格
goods_price=goods.find_element_by_css_selector('div.p-price')
#获取元素
goods_name=goods.find_element_by_css_selector('div.p-name')
#获取链接
goods_herf=goods.find_element_by_css_selector('div.p-img>a').get_property('href')
#获取出版社或店铺
goods_shopnum=goods.find_element_by_css_selector('div.p-shopnum')
return goods_price,goods_name,goods_herf,goods_shopnum
def drop_down(web_driver):
#将滚动条调整至页面底部
web_driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(4)
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
print('爬取信息成功')
#获取爬取一页
def crawl_a_page(web_driver,goods_num):
#获取图书列表
drop_down(web_driver)
goods_list=web_driver.find_elements_by_css_selector('div#J_goodsList>ul>li')
#获取一个图书的价格、名字、链接、获取出版社或店铺
for i in tqdm(range(len(goods_list))):
goods_num-=1
goods_price,goods_name,goods_herf,goods_shopnum=get_prince_and_name(goods_list[i])
goods=[]
goods.append(goods_price.text)
goods.append(goods_name.text)
goods.append(goods_herf)
goods.append(goods_shopnum.text)
goods_info_list.append(goods)
if goods_num==0:
break
return goods_num
while goods_num!=0:
goods_num=crawl_a_page(driver,goods_num)
btn=driver.find_element_by_class_name('pn-next').click()
time.sleep(1)
write_csv(goods_head,goods_info_list,goods_path)
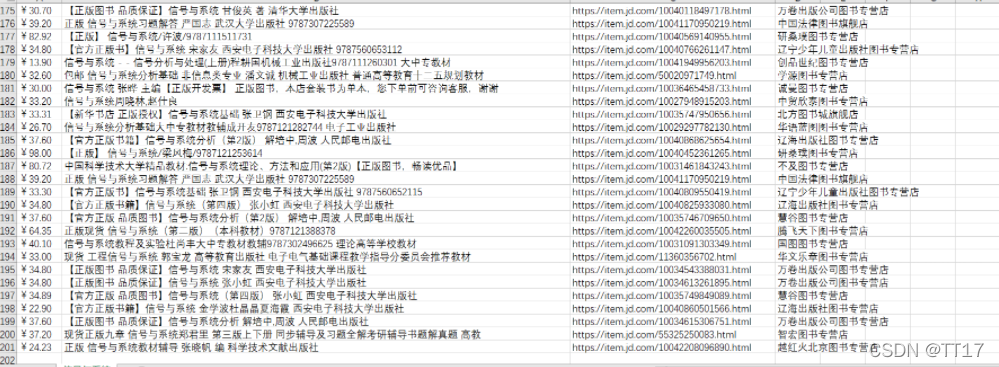
5.运行结果

五、总结
完成了动态网页的信息爬取,就是爬取的速度比较慢,模拟人去点击网页,还是需要先找到相关元素文章来源:https://uudwc.com/A/AZAwr
六、参考链接
使用Selenium实现动态网页的信息爬取
文章来源地址https://uudwc.com/A/AZAwr

