文章目录
- 为什么提出?
- 具体是怎么做的?
- 1.解耦的思想(对应文章第四章4.Disentanglement studies)
- 1.1 感知路径长度(对应4.1Perceptual path length)
- 1.2 线性可分离性(对应4.2Linear separability)
- 2.具体网络的实现(对应2.Style-based generator)
- 3.基于样式生成器的属性(对应3.Properties of the style-based generator)
- 3.1 样式混合(Style mixing)
- 3.2 随机变化(Stochastic variation)
- 3.3从随机性中分离出全局效应(Separation of global effects from stochasticity)
- 总结
听过Stylegan的人都觉得他很强!目前stylegan已经发展到第三代v3了,但是为了搞清思想,我还是从v1开始了解,以下是我个人的一些理解。
为什么提出?
传统GAN采用端对端的输入输出,可以尽可能使用训练集数据的信息,但是会出现两个问题。
- 仅保持一种输入,纵使网络有再强的能力,也可能会出现生成信号的周期性,
- 输入和输出特征严重耦合,头发,胡茬,雀斑,皮肤毛孔等都是随机生成,没有办法控制,因为隐藏变量隐藏的很深
- 端对端会让网络更加难学,因为真实的仿射变换是很复杂的,而且维度很高,找到这种变换关系更难,同时也会耗费网络容量。
相较于传统方式,其实本篇论文是提供一个全新的思路,就是想将输入潜在空间和训练数据解耦。
什么意思呢?就是引入中间变量,让输入更加量化的控制输出,同时也便于控制整体生成情况。
具体是怎么做的?
1.解耦的思想(对应文章第四章4.Disentanglement studies)
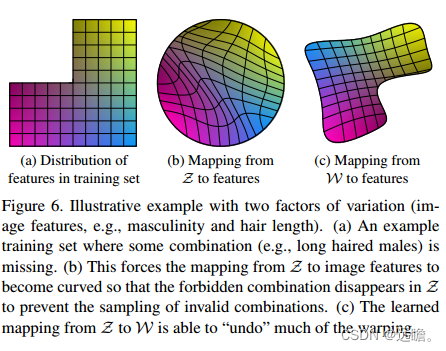
如图所示,传统的GAN寻求的是(a)到(b)的学习,输入简单单一的输入样本,让网络学习到复杂的映射变换,这其实很要求网络的能力,且每个变量都是难以捉摸的,不能使用线性插值来变换生成特征。
而( c)是经过中间潜在空间的映射,可以看到让z学习到中间潜在空间w,再让w映射到特征feature,基本上就是比较线性的关系,这个时候对于一些特征,是解耦的,可编辑的状态。
1.1 感知路径长度(对应4.1Perceptual path length)
为了达到上图解耦的目的,在训练过程中需要对潜在空间向量做一定的约束(Loss),例如对潜在空间向量的插值我们需要让它产生一定的线性变化而不是非线性变化。线性变化对应上图中的图c,是一个解耦状态。所以需要测量在潜在空间中执行插值时图像经历的剧烈变化,让它尽可能平滑的过度。
文中采用的是基于感知的两两图像距离(perceptually-based pairwise image distance),基于VGG16,其中权重是拟合的,因此度量符合人类感知相似性判断。将潜在空间插值路径细分为线性段,则总感知长度就是每段上的总和。
1.2 线性可分离性(对应4.2Linear separability)
如果一个潜在空间被充分地解开,应该有可能找到一致地对应于个别变异因素的方向向量。文中提出了另一个度量,通过测量潜在空间点如何通过线性超平面划分为两个不同的集合来量化这种效应,以便每个集合对应于图像的特定二进制属性。
简而言之就是额外训练一个分类器,区分对立属性,例如男性和女性,然后输入图片有z ~ P(z)的图像,并使用辅助分类网络对它们进行分类。对于每个属性,拟合一个线性支持向量机来预测基于潜在空间点的标签。对比两者条件熵H(Y |X),就知道需要多少额外的信息来确定样本的真实类别。
2.具体网络的实现(对应2.Style-based generator)
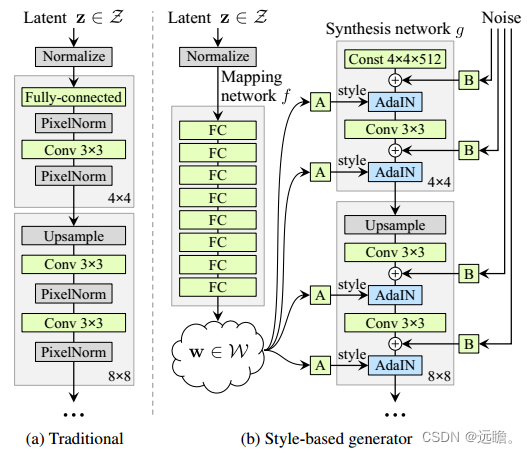
该算法受到风格转移文献的启发,重新设计生成器架构,以一种新的方式来控制图像合成过程。
生成器从一个习得的常量输入开始,根据潜码在每个卷积层调整图像的“风格”,从而直接控制不同尺度下图像特征的强度。结合直接注入到网络中的噪声,可以分离生成图像的高级属性(例如,姿势,身份)
1.Mapping network 负责将潜在代码(latent code) z 生成 中间变量 w 。由w来控制生成图像的style。
2.Synthesis network 负责生成图像,引入噪声是为了生成随机细节。
首先设置每个通道数的维度是512,映射f是使用8层MLP实现的,学习后的仿射变换将w转为样式y = (ys, yb),在合成网络g的每个卷积层之后控制自适应实例归一化(AdaIN)[27,17,21,16]。AdaIN操作定义为
每个特征图xi分别归一化,然后使用样式y的相应标量分量进行缩放和偏置。因此y的维数是该层上特征映射数量的两倍。
最后,通过引入显式噪声输入,提供了直接生成随机细节的方法为合成网络的每一层提供一个专用的噪声图像。使用学习到的特征缩放因子将噪声图像广播到所有特征映射中,然后添加到相应卷积的输出中。
3.基于样式生成器的属性(对应3.Properties of the style-based generator)
映射网络(mapping network)和仿射变换(affine transformations)看作是一种从学习分布中为每种风格绘制样本的方法,
综合网络(synthesis network)则是一种基于风格集合生成新图像的方法。
每种样式的效果在网络中都是局部化的,也就是说,修改样式的特定子集可以预期只影响图像的某些方面。为什么是这样子的?
可以从归一化AdaIN 理解起来,将每个通道归一化为零均值和单位方差,然后才根据风格应用尺度和偏差。因此,W只是修改了通道的相对重要性,他们不依赖于原始的信息。
3.1 样式混合(Style mixing)
在文中提到这个其实就是混合正则化(mixing regularization),在训练期间使用两个随机的潜在代码生成图像,具体来说就是:通过映射网络运行两个潜码z1, z2,并由对应的w1, w2控制样式,使w1在交叉点前应用,w2在交叉点后应用。如图所示。作者还发现不同尺寸混合会产生不一样的效果,在4-8的尺度上混合,修改的是姿态,头发风格,脸部形状,在16-32尺度上混合,修改的是更小尺度的脸部特征,头发风格眼睛等,在64-1024尺度上混合修改的是颜色和微小特征。
3.2 随机变化(Stochastic variation)
人体肖像中有许多方面可以被认为是随机的,比如头发、胡茬、雀斑或皮肤毛孔的确切位置。这些都可以随机化而不影响我们对图像的感知,只要它们遵循正确的分布。
传统的生成器是如何实现随机变化的?网络的唯一输入是通过输入层,网络需要发明一种方法从早期的激活中来生成空间变化的伪随机数.这会消耗网络容量,并且隐藏生成信号的周期性是困难的——而且并不总是成功的,正如生成图像中常见的重复模式所证明的那样。文中架构通过在每次卷积后添加逐像素噪声,避免了这些问题。
图4显示了使用不同噪声实现的生成器生成的相同底层图像的随机实现。我们可以看到,噪声只影响随机方面,使整体组成和高级方面,如身份完好无损。
3.3从随机性中分离出全局效应(Separation of global effects from stochasticity)
虽然风格的变化具有全局影响(改变姿势,身份等),但噪声只影响无关紧要的随机变化(不同梳的头发,胡须等)。这一观察结果与风格迁移文献一致。
在基于样式的生成器中,样式会影响整个图像,因为完整的特征映射被缩放并带有相同的值。因此,全局效果,如姿势,照明,或背景风格可以控制连贯。同时,噪声被独立地添加到每个像素,因此非常适合于控制随机变化。如果网络试图使用噪声来控制姿势,这将导致空间不一致的决定,然后将被鉴别器惩罚。因此,在没有明确指导的情况下,网络学会了适当地全局和局部通道。这部分相当于是证明为啥噪声仅控制局部随机变化的原因文章来源:https://uudwc.com/A/AZjDO
总结
styleGANV1其实主要点就是建立Z-W-Feature的生成器模型,让网络可以充分释放生成器的能力,并解耦的控制特征。文章来源地址https://uudwc.com/A/AZjDO
