前言:ACCV2022wrokshop用transformer做插帧的文章,q,kv,来自不同的图像
代码:【here】
Cross-Attention Transformer for Video Interpolation
引言
传统的插帧方法多用光流,但是光流的局限性在于
第一:它中间会算至少两个 cost volumes,它是四维的,计算量非常大
第二:光流不太好处理遮挡(光流空洞)以及运动的边缘(光流不连续)对大的运动的处理也不友好
对于第一点,比如插帧256*256的图片,光流法的推理速度就明显比不同光流的方法的推理速度慢很多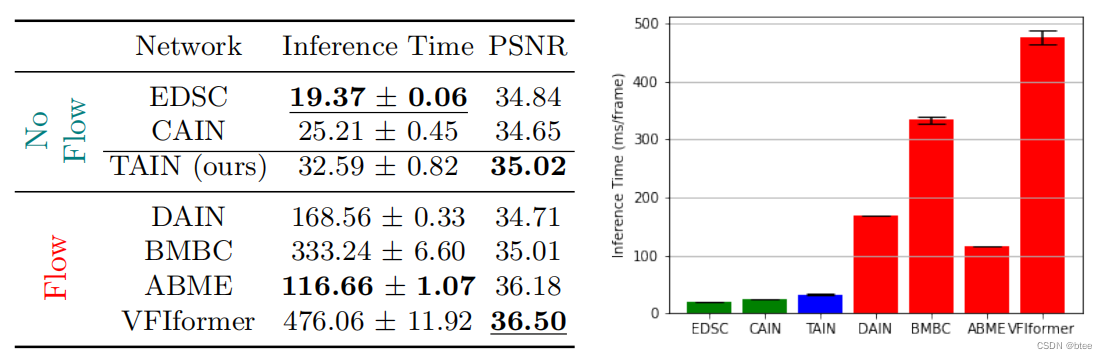
因此,本文针对插帧任务专门设计了一个跨帧transformer,而不是算图像中区域与区域之间的相似性,并且提出了一个空间注意力图,来计算左右两边插帧的分数并进行融合,更好的处理运动边缘和遮挡
因此,本文的贡献点在于:
- 提出了一个cross-attention的Transformer,
- 提出了一个IA模块利用的两边的注意力进行融合
- 在非光流法上跑到了SOTA
这里想补充一些我个人的看法:
刚看到这个introduction的时候我觉得很不解,感觉没有讲出transformer的最主要的贡献(我认为用transformer可以解决大位移的匹配,并且后文用的图也是插单帧的transformer,数据集是Middlebury,帧间物体的位移也很小,这种小位移的情况应该比较适合用convolution的办法解决)
然后作者更多强调是CAIN的拓展,我个人觉得是个大改动,不算另一篇文章的拓展了,然而看了实验结果我才明白,害,原来是效果不太好啊…只能说在各个数据集都跑赢了CAIN,作为拓展的确是比较成功了…
方法
pipeline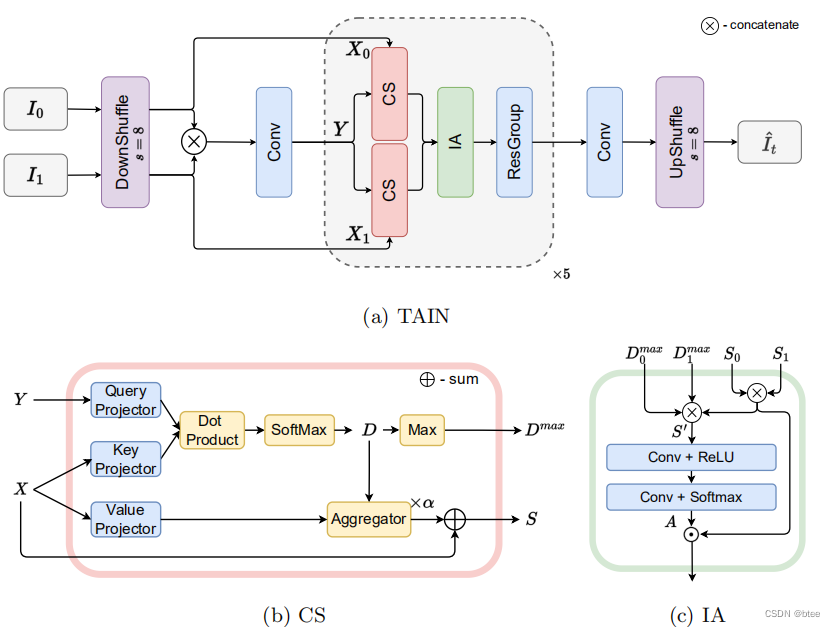
这里先将图片pixelshuffle,类似于transformer里打成8 * 8的patch,然后两张图片通道concat,过一层卷积,得到transformer中的k,两张原始图片作为左右两边的transformer的k,v,而对于Q和K的映射,作者这里采用的同一个映射网络,即是共享权重的,这和普通的transformer不太一样
这样每一个查询子的各个区域其实都是对原始图像进行特征的重新分配,最后的结果S的计算为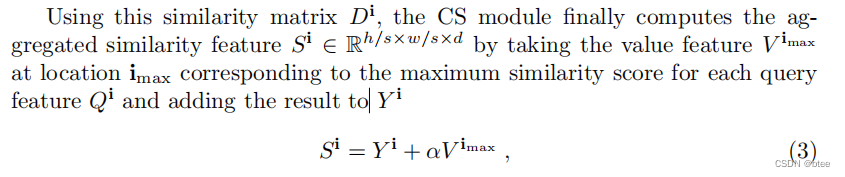
(由于代码暂时未公开,不知道这里是不是将特征图D进行一个Onehot编码)
最后由于左右两侧都有可以参考的图片特征,因此,对于两侧transformer后的结构进行融合,用于处理遮挡情况
如图片(C)的IA所示,4个输入在特征层堆叠连接,并过两个1 * 1的conv层,最后一层的conv的激活为softmax,两个通道,因此可以实现两个特征图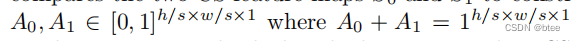
(为啥不和superslomo这类文章一样用sigmoid并用1相减,我也不是很懂…)
两个特征图与对应的transformer的cross-attention后得到的结果相乘,最后合并过一个ResGroup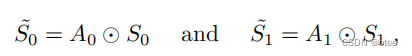
(这里我认为这个设计最大的问题就是初始conv层找不准初始查询图片的位置,导致最后的插帧有可能出现伪影)
损失函数
损失函数采用图像L1损失和梯度L1损失,并强调了没有用感知损失
实验
这里作者还采用了随机添加边长范围为21 -61遮挡块的增强方式
对比实验的结果
很多方法都没超过,近期的插帧方法基本都能在vimeo上达到一个36的水平,这个结果靴微有些逊色了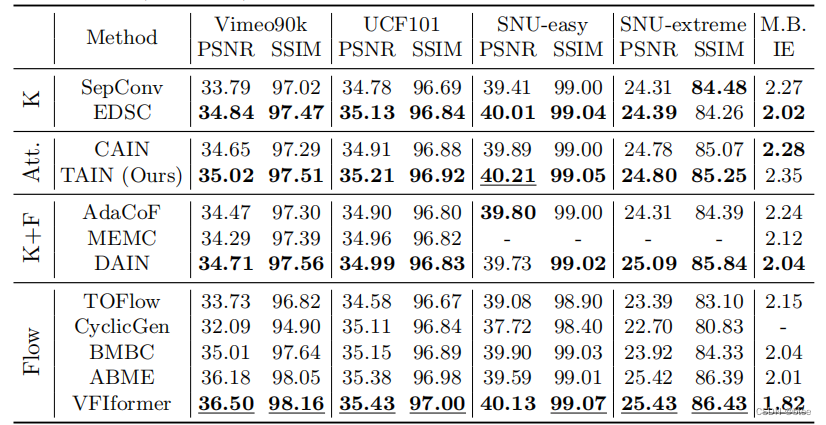
作者这里也说明方法的另一个优势,是在于推理速度,比光流法快了很多倍,但是transformer对于底层图像任务有个致命的缺点就是随着分辨率的提升计算量二次增加,这里只是用256 * 256的图像进行的测试
最后是对cross-attention的可视化,对于这五个不同颜色的位置,有五个attention与之对应,颜色越浅代表相似分数越大
对于5次堆叠的transformerblock,作者也分别对前4次的cross-attention特征图进行了可视化,蓝色标记位置表示查询位置,红色位置表示相似分数最大的位置
对于融合阶段的attention,作者也进行了可视化,并且这里作者对其中一张图加了一个遮挡块来验证两张特征图的空间权重,明显没有被遮挡的那张图的选中区域分数更高 文章来源:https://uudwc.com/A/AvE4
文章来源:https://uudwc.com/A/AvE4
总结
看到这个标题就想下载这篇论文,左右两边cross-attention的transformer是我个人觉得很适合插帧领域的一个idea,可以在不用光流warp实现解决大位移的情况,这篇文章没有提到这一点,我想可能是大位移的时候,初始图的中间位置又找不准了,可惜这个想法的结果并不是那么完美文章来源地址https://uudwc.com/A/AvE4