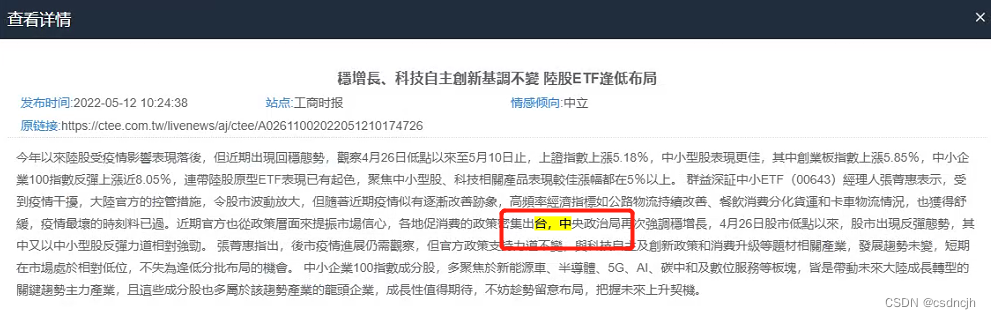
此次问题由一次测试提出的bug引起:测试检索功能时候,以 台中 为关键词检索,结果中出现了 台,中的结果,如图所示
复现问题
该字段用的是standard分词器
查询用的是match_phrase_prefix查询
准备数据
构建mapping
PUT my_index
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 1
}
},
"mappings": {
"my_doc": {
"dynamic": false,
"properties": {
"id": {
"type": "integer"
},
"content": {
"type": "text",
"analyzer": "standard",
"store": true
},
"name":{
"type":"text"
},
"createAt": {
"type": "date"
}
}
}
}
}批量插入
POST _bulk
{ "index" : { "_index" : "my_index", "_type" : "my_doc", "_id" : "1" } }
{ "id" : 1,"content":"各地促消費的政策密集出台,中央政治局再" }
{ "index" : { "_index" : "my_index", "_type" : "my_doc", "_id" : "2" } }
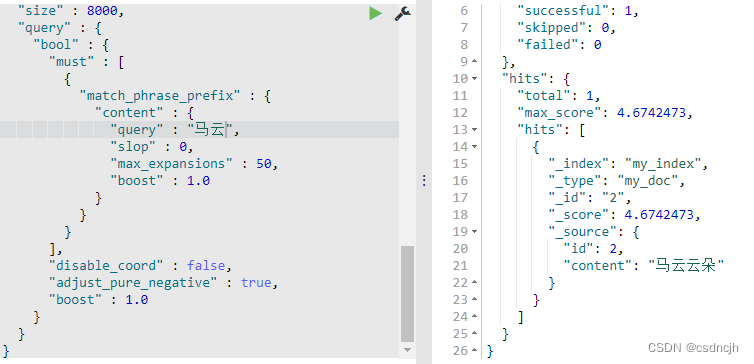
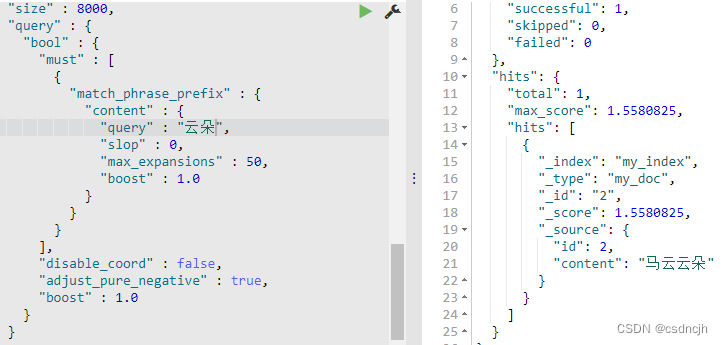
{ "id" : 2,"content":"马云云朵" }
{ "index" : { "_index" : "my_index", "_type" : "my_doc", "_id" : "3" } }
{ "id" : 3,"content":"他所在的台中便接獲基層學校反映" }
{ "index" : { "_index" : "my_index", "_type" : "my_doc", "_id" : "4" } }
{ "id" : 4,"content":"关注我,间隔系统学编程" }查询
GET my_index/_search
{
"size" : 8000,
"query" : {
"bool" : {
"must" : [
{
"match_phrase_prefix" : {
"content" : {
"query" : "台中",
"slop" : 0,
"max_expansions" : 50,
"boost" : 1.0
}
}
}
],
"disable_coord" : false,
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
}问题排查
初步怀疑是分词器造成的
测试被检索数据分词效果
POST _analyze
{
"analyzer": "standard",
"text": "各地促消費的政策密集出台,中央政治局再"
}结果:

文章来源地址https://uudwc.com/A/DzJLk
测试查询关键词分词效果
POST _analyze
{
"analyzer": "standard",
"text": "台中"
}结果

看看match_phrase查询原理就知道为什么会命中数据了。
match_phrase查询分析文本并根据分析的文本创建一个短语查询。match_phrase 会将检索关键词分词。match_phrase的分词结果必须在被检索字段的分词中都包含,而且顺序必须相同,而且默认必须都是连续的。
问题解决
换分词器
第一想法是换分词器,用ik分词器
删除索引
DELETE my_index
构建mapping
PUT my_index
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 1
}
},
"mappings": {
"my_doc": {
"dynamic": false,
"properties": {
"id": {
"type": "integer"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"store": true
},
"name":{
"type":"text"
},
"createAt": {
"type": "date"
}
}
}
}
}批量插入
POST _bulk
{ "index" : { "_index" : "my_index", "_type" : "my_doc", "_id" : "1" } }
{ "id" : 1,"content":"各地促消費的政策密集出台,中央政治局再" }
{ "index" : { "_index" : "my_index", "_type" : "my_doc", "_id" : "2" } }
{ "id" : 2,"content":"马云云朵" }
{ "index" : { "_index" : "my_index", "_type" : "my_doc", "_id" : "3" } }
{ "id" : 3,"content":"他所在的台中便接獲基層學校反映" }
{ "index" : { "_index" : "my_index", "_type" : "my_doc", "_id" : "4" } }
{ "id" : 4,"content":"关注我,间隔系统学编程" }查询
GET my_index/_search
{
"size" : 8000,
"query" : {
"bool" : {
"must" : [
{
"match_phrase_prefix" : {
"content" : {
"query" : "台中",
"slop" : 0,
"max_expansions" : 50,
"boost" : 1.0
}
}
}
],
"disable_coord" : false,
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
}查询结果
命中结果满足要求,没有多余命中

再测试其他查询条件,钧满足条件

修改standard配置
能不能通过调整standard分词器来实现呢?
一个标准的分词器包含三个部分,character filters、tokenizers和token filters。
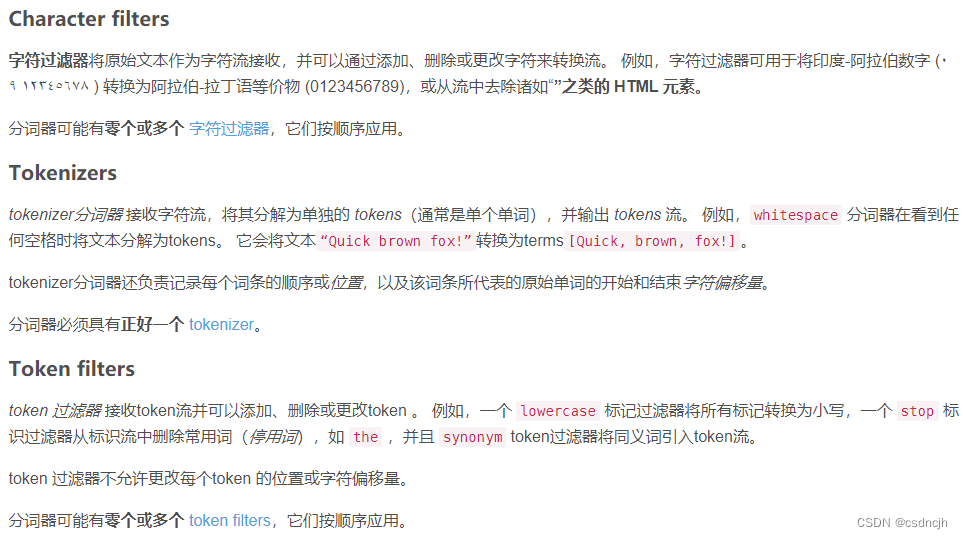
由此判断,文章内容中的中文逗号是在写入是分词时候被character filters过滤掉了,尝试将中文逗号保存下来是不是能满足要求。
删除索引
DELETE my_index
构建mapping
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"char_filter": [
"my_char_filter"
]
}
},
"char_filter": {
"my_char_filter": {
"type": "mapping",
"mappings": [
",=> 0"
]
}
}
}
},
"mappings": {
"my_doc": {
"dynamic": false,
"properties": {
"id": {
"type": "integer"
},
"content": {
"analyzer": "my_analyzer",
"store": true,
"type": "text"
},
"name":{
"type":"text"
},
"createAt": {
"type": "date"
}
}
}
}
}检测分词效果
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "各地促消費的政策密集出台,中央政治局再"
}
批量插入以后查询,查询结果满足条件。说明修改character filters也能达到效果,但是这这是一个探究,只是为了深入了解分词器,不建议生产环境使用。
总结
自带的几种分词器
分词器 解释 standard 标准标记器,标准过滤器,小写过滤器,停止过滤器 simple 小写的分词器 stop 小写标记器,停止过滤器 keyword 不分词,内容整体作为一个值 whitespace 以空格分词 language 以语言分词 snowball 标准标记器,标准过滤器,小写过滤器,停止过滤器,雪球过滤器 custom 自定义分词。至少需要指定一个 Tokenizer, 零个或多个Token Filter, 零个或多个Char Filter pattern 正则分词
es常用查询接口总结

精准查询
termQuery
精准或精确查询相当于sql语句中的 where auto_id = 1 或 userName = “test”, 字段一般不进行分词
样例
GET my_index/_search
{
"size" : 8000,
"query" : {
"bool" : {
"must" : [
{
"term" : {
"id" : {
"value" : "1",
"boost" : 1.0
}
}
}
],
"disable_coord" : false,
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
}
范围查询
rangeQuery
类似于 sql 中的 > 、>=、 <和 <= ,进行范围限定
样例
GET my_index/_search
{
"size" : 8000,
"query" : {
"bool" : {
"must" : [
{
"range" : {
"pubtime" : {
"from" : "2022-05-12 10:00:00",
"to" : "2022-05-12 10:50:00",
"include_lower" : true,
"include_upper" : false,
"boost" : 1.0
}
}
}
],
"disable_coord" : false,
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
}关键词查询
matchQuery
精确查询搜索条件太严格,使用场景有限,所以催生出 关键词查询,只要字段值term列表中包含 关键词分词后的term即可
样例
GET my_index/_search
{
"size" : 8000,
"query" : {
"bool" : {
"must" : [
{
"match" : {
"content" : {
"query" : "台中",
"operator" : "AND",
"prefix_length" : 0,
"max_expansions" : 50,
"fuzzy_transpositions" : true,
"lenient" : false,
"zero_terms_query" : "NONE",
"boost" : 1.0
}
}
}
],
"disable_coord" : false,
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
}短语查询
PhraseQuery
由于精准/精确查询要求太严格,而关键词查询只是取决于包含与否,并不对term之间的位置有所要求,但是 对于 短语来说是有位置要求的,如 hello world这一短语,当进行 关键词搜索keywords = world hello,也会返回出来因为 关键词查询只进行包含判断,并不进行位置判断,那么在这种情况下 短语查询应运而生。
样例
GET my_index/_search
{
"size" : 8000,
"query" : {
"bool" : {
"must" : [
{
"match_phrase" : {
"content" : {
"query" : "台中",
"slop" : 0,
"boost" : 1.0
}
}
}
],
"disable_coord" : false,
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
}短语前缀查询
PhrasePrefixQuery
PhrasePrefixQuery和PhraseQuery的区别
摘自ES官网:The match_phrase_prefix is the same as match_phrase, except that it allows for prefix matches on the last term in the text.
当搜索项为中文时,几乎无差别,当搜索英文时存在较大差异,比如quick brown fox,
当搜索 quick brown f时 addPhraseQuery不会返回结果,当进行addPhrasePrefixQuery 时会返回结果,因为会对最后一个 term 的前缀进行匹配;
样例
GET my_index/_search
{
"size" : 8000,
"query" : {
"bool" : {
"must" : [
{
"match_phrase_prefix" : {
"content" : {
"query" : "台中",
"slop" : 0,
"max_expansions" : 50,
"boost" : 1.0
}
}
}
],
"disable_coord" : false,
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
}
来源
一文搞懂match、match_phrase与match_phrase_prefix的检索过程 - 知乎
【ES实战】ES分词器介绍_顧棟的博客-CSDN博客_es 分词器
ES分词器 - Character Filters - 简书
es进行分词测试以及自定义分词_小六神通的博客-CSDN博客_es 分词测试
ES 分词器使用和配置_小P聊技术的博客-CSDN博客_es 配置分词器
Elastic Search常用命令_胖毁青春,瘦解百病的博客-CSDN博客文章来源:https://uudwc.com/A/DzJLk