文章来源地址https://uudwc.com/A/EZgn
RNN是一类拥有隐藏状态,允许以前的输出可用于当前输入的神经网络,
输入一个序列,对于序列中的每个元素与前一个元素的隐藏状态一起作为RNN的输入,通过计算当前的输出和隐藏状态。当前的影藏状态作为下一个单元的输入...
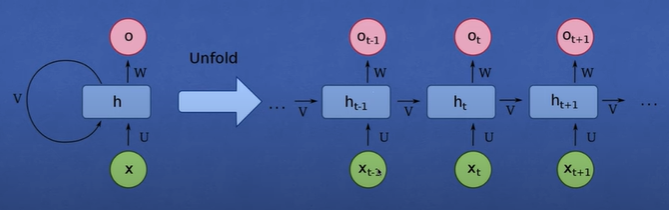
RNN的种类
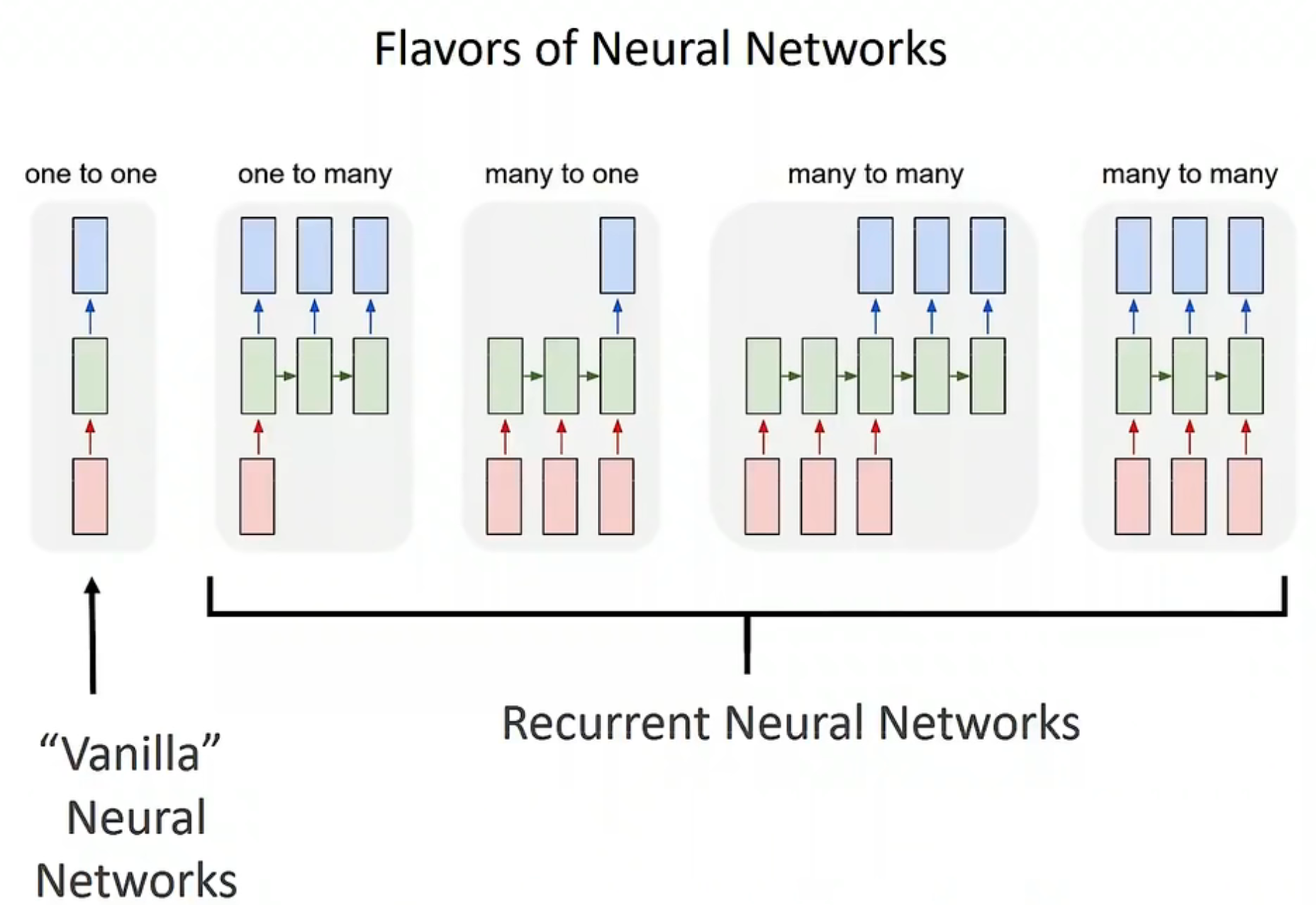
上图中的红色方块代表输入,蓝色方块代表输出,绿色方块代表
一对一(one to one)
一对一的结构一般指经典的卷积神经网络和全连接神经网络,被誉为香草神经网络,它们处理固定大小的输入,并输出固定大小的输出,主要用于图像分类任务。
下面介绍循环神经网络RNN的几种结构和其应用:
多对一(many to one)
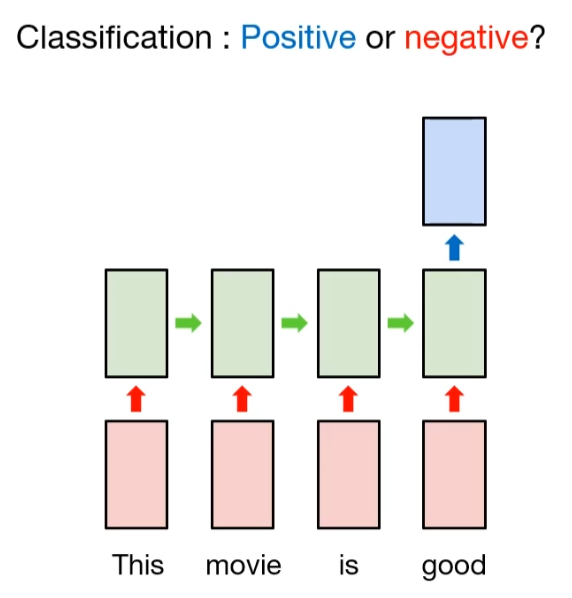
多对一结构用于分类,如情感分类(输入一个句子,判断是积极还是消极的情感)
一对多(one to many)
一对多可用于生成,如音乐生成,还可以用于图像字幕(输入一张图片,输出一个文本句子)
多对多(many to many)
多对多结构可用于机器翻译(输入一个英文句子,输出一个中文句子)和视频分类(视频中的多个帧作为输入,对视频中的每一帧进行分类)
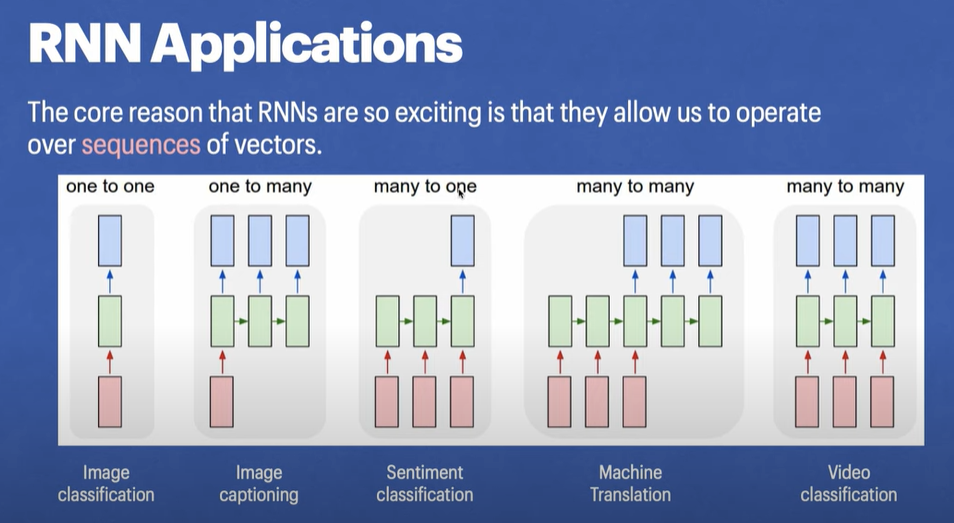
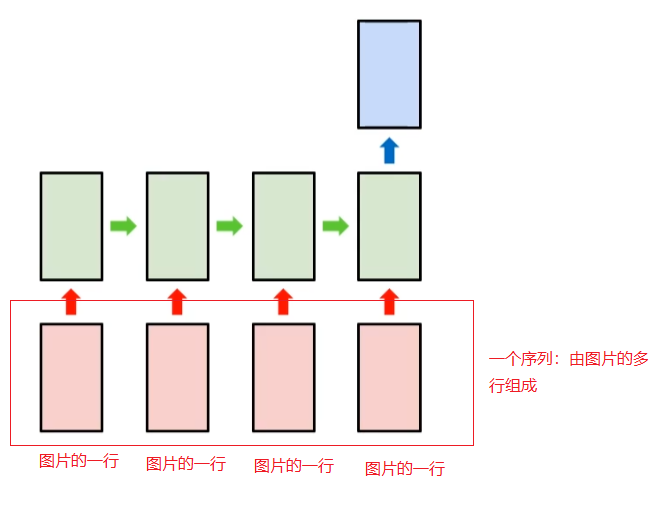
RNN多对一用于图像分类
下面介绍使用RNN进行分类(图像分类)的方法。RNN用于分类任务的结构是多对一结构。假设图像的尺寸是28x28的黑白图片,将每一个张图片作为RNN的输入,每一行作为一个输入特征,所有的行构成一个序列。
RNN的输出只选择最后一行的输出(使用out[:, -1, :]),这就是多对一的精髓。最后再套一个全连接层,使用交叉熵作为判断准则。
RNN图像分类的示例代码
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Hyper-parameters
# input_size = 784 # 28x28
hidden_size = 128
num_classes = 10
num_epochs = 2
batch_size = 100
learning_rate = 0.001
input_size = 28
sequence_length = 28
num_layers = 2
# MNIST dataset
train_dataset = torchvision.datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor())
# Data loader
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
examples = iter(test_loader)
example_data, example_targets = next(examples)
# for i in range(6):
# plt.subplot(2,3,i+1)
# plt.imshow(example_data[i][0], cmap='gray')
# plt.show()
# Fully connected neural network with one hidden layer
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(RNN, self).__init__()
self.num_layers = num_layers
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
# x: (batch_size, sequence_len, input_size)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
out, _ = self.rnn(x, h0)
# out: batch_size, seq_length, hidden_size
# out: (N, 28, 128)
out = out[:, -1, :]
# out (N, 128)
out = self.fc(out)
return out
model = RNN(input_size, hidden_size, num_layers,num_classes).to(device)
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Train the model
n_total_steps = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# origin shape: [100, 1, 28, 28]
# resized: [100, 28, 28]
images = images.reshape(-1, sequence_length, input_size).to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print (f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{n_total_steps}], Loss: {loss.item():.4f}')
# Test the model
# In test phase, we don't need to compute gradients (for memory efficiency)
with torch.no_grad():
n_correct = 0
n_samples = 0
for images, labels in test_loader:
images = images.reshape(-1, sequence_length, input_size).to(device)
labels = labels.to(device)
outputs = model(images)
# max returns (value ,index)
_, predicted = torch.max(outputs.data, 1)
n_samples += labels.size(0)
n_correct += (predicted == labels).sum().item()
acc = 100.0 * n_correct / n_samples
print(f'Accuracy of the network on the 10000 test images: {acc} %')
文章来源:https://uudwc.com/A/EZgn

