目录
1、zset有序集合
2、zset相关命令
2.1、添加或更新指定的元素——zadd
2.2、获取有序集合zset的元素个数相关命令:zcard、zcount
2.3、返回指定区间元素相关命令:zrange、arevrange、zrangebyscore
2.4、删除相关命令:zpopmax、zpopmin、bzpopmax、bzpopmin、zrem、zremrangebyrank、zremrangebyscore
2.5、返回指定元素的排名——zrank、zrevrank
2.6、返回指定元素的分数——zscore
2.7、为指定的元素的关联分数添加指定的分数值——zincrby
2.8、集合间操作:zinterstore、zunionstore
3、应用场景
1、zset有序集合
zset中使用的是member和score【score为一个浮点数】,而不是键值对key value;
score member和key vlaue的区别;score有两个特殊取值:inf 无穷大 ,-inf无穷小 ---二者的绝对值都是无限大的~
- member score:既可以通过member找score,也可以通过score找member
- key value:只能通过key来找对应的value
zset的特点:
- 有序的---按照分数升序排列,分数score相同的按照member的字典序排列
- member值需要唯一,score可以不唯一
2、zset相关命令
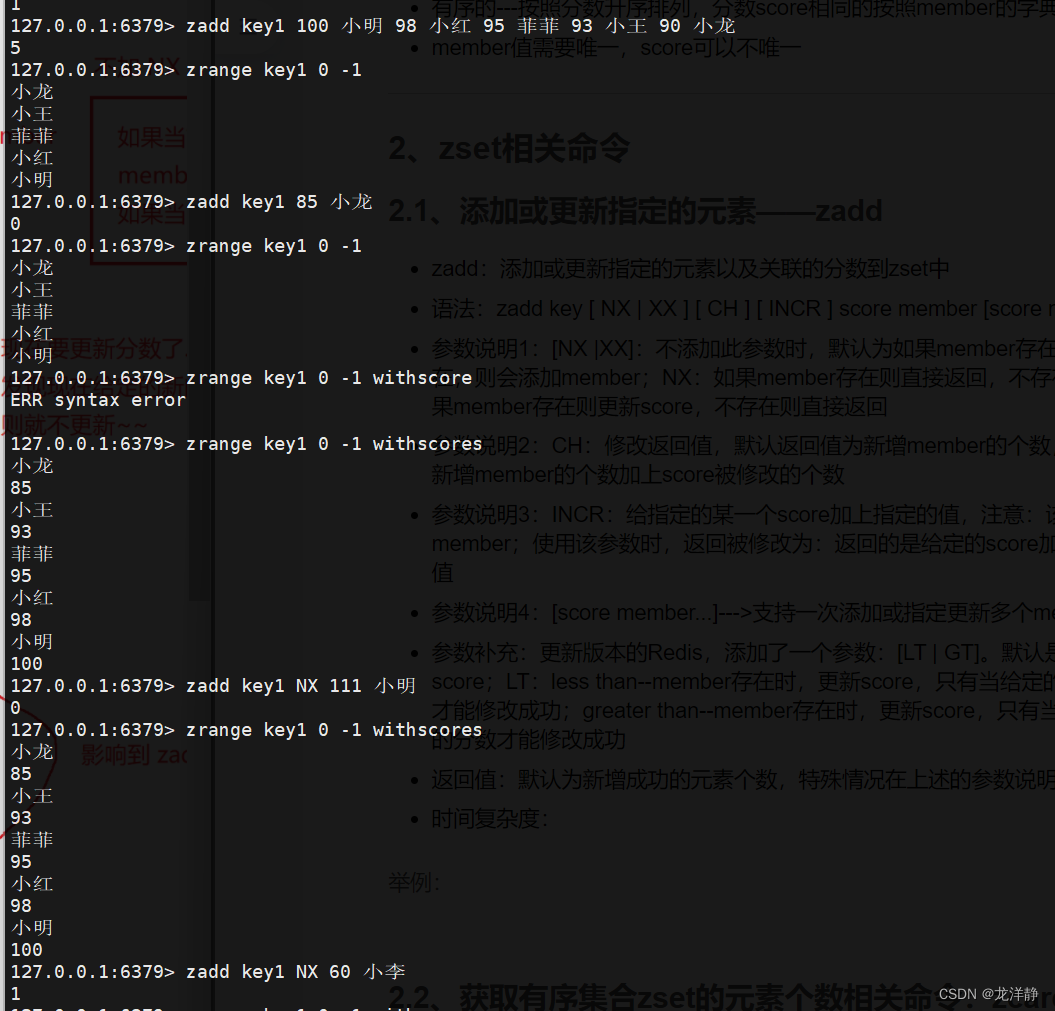
2.1、添加或更新指定的元素——zadd
- zadd:添加或更新指定的元素以及关联的分数到zset中
- 语法:zadd key [ NX | XX ] [ CH ] [ INCR ] score member [score member...]
- 参数说明1:[NX |XX]:不添加此参数时,默认为如果member存在,则更新score值,如不存在,则会添加member;NX:如果member存在则直接返回,不存在则新增member;XX:如果member存在则更新score,不存在则直接返回
- 参数说明2:CH:修改返回值,默认返回值为新增member的个数,添加该参数后,返回值为新增member的个数加上score被修改的个数
- 参数说明3:INCR:给指定的某一个score加上指定的值,注意:该参数一次只能操作一个member;使用该参数时,返回被修改为:返回的是给定的score加上指定值后,新的score的值
- 参数说明4:[score member...]--->支持一次添加或指定更新多个member
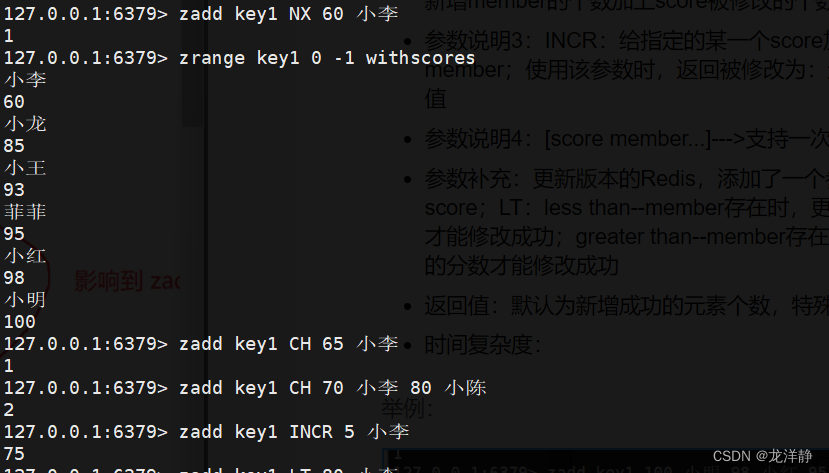
- 参数补充:更新版本的Redis,添加了一个参数:[LT | GT]。默认是若member存在,则修改score;LT:less than--member存在时,更新score,只有当给定的新的分数小于原来的分数才能修改成功;greater than--member存在时,更新score,只有当给定的新的分数大于原来的分数才能修改成功
- 返回值:默认为新增成功的元素个数,特殊情况在上述的参数说明已经提及了~
- 时间复杂度:logN--zset内部数据结构主要是跳表,每次新增或修改后,内部都会进行再次排序,保证zset内部一直是有序的,具体怎么推导出时间复杂度是logN,后续文章会持续更新的~
举例:
2.2、获取有序集合zset的元素个数相关命令:zcard、zcount
zcard:获取一个zset的基数,也就是zset中某个key的元素个数
- 语法:zcard key
- 返回值:zset中某key中的元素个数
- 时间复杂度O(1)
举例:

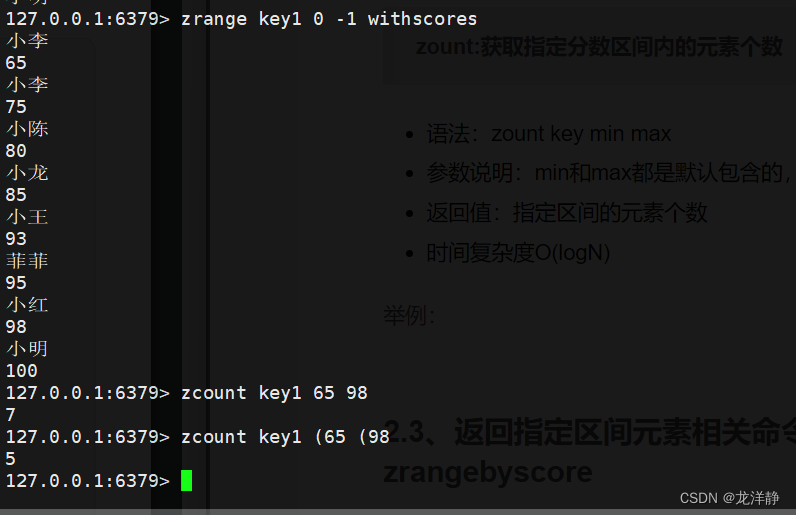
zount:获取指定分数区间内的元素个数
- 语法:zount key min max
- 参数说明:min和max都是默认包含的,不想包含的话,需要在min或max左边加上左括号(
- 返回值:指定区间的元素个数
- 时间复杂度O(logN)----根据min找到对应的元素,再根据max找到对应的元素,查询到元素后就可以获取到他的次序,也就是下标,直接对应下标相减即可~
举例:
2.3、返回指定区间元素相关命令:zrange、zrevrange、zrangebyscore
zrange:返回指定区间内的元素,按分数升序排列
- 语法:zrange key start stop [withscores]
- 参数说明:默认返回member值,加上该参数后,会带着分数一起返回;start sotp支持负数
- 返回值:区间内元素的列表
- 时间复杂度O(log(N)+M)----logN:根据start找到对应元素;M:start-stop区间的元素个数
举例:
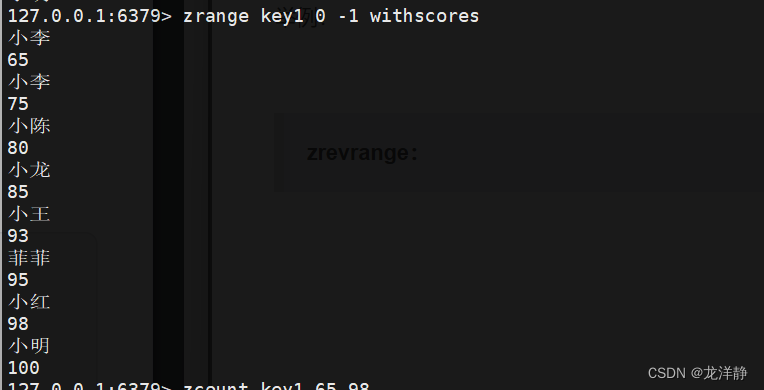
zrevrange:返回指定区间内的元素,按照分数降序排列---注意这里的按照降序是,将原本的整个zset先进行降序排列,具体下标也会随之变化,例如原本ll是在下标为len-1的地方,降序调整后,ll是在下标为0的地方~
- 语法:zrevrange key start stop [withscores]
- 返回值:区间内的元素列表
- 时间复杂度:O(log(N)+M)----logN:根据start找到对应元素;M:start-stop区间的元素个数
举例:
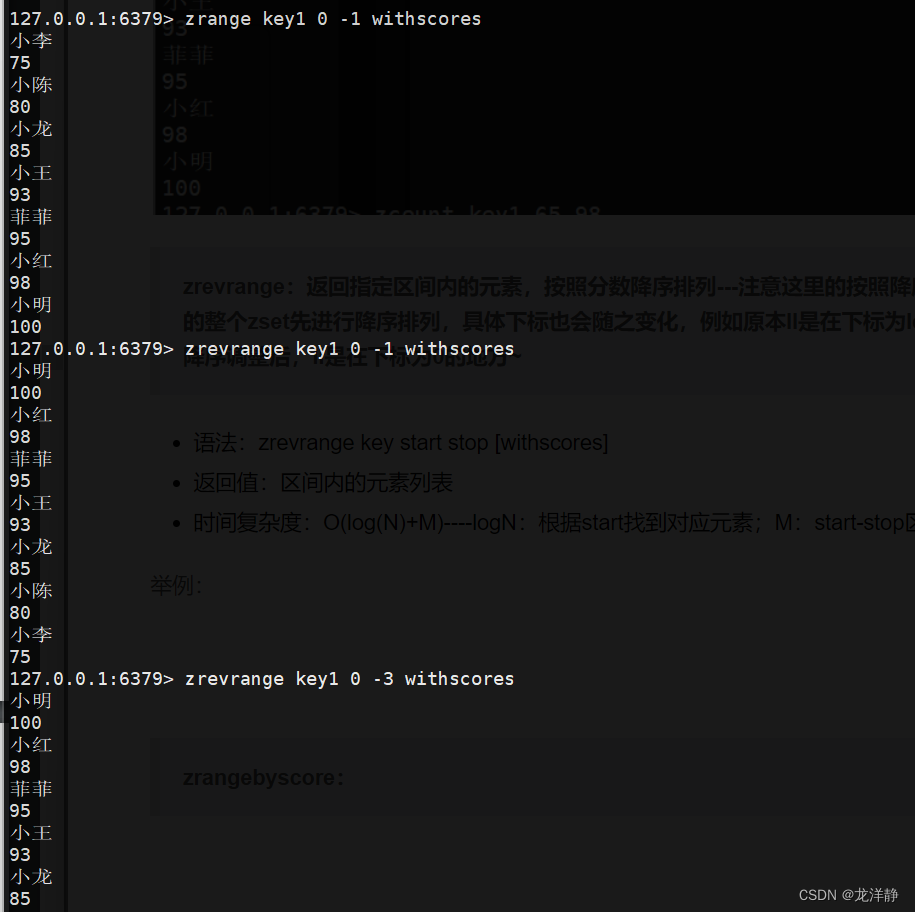
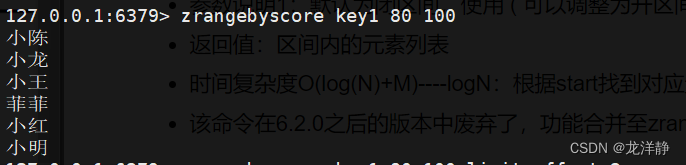
zrangebyscore:返回某分数段之间的元素
- 语法:zrangescore key min max [withscores]
- 参数说明1:默认为闭区间,使用 ( 可以调整为开区间
- 返回值:区间内的元素列表
- 时间复杂度O(log(N)+M)----logN:根据start找到对应元素;M:start-stop区间的元素个数
- 该命令在6.2.0之后的版本中废弃了,功能合并至zrang命令中
举例:
2.4、删除相关命令:zpopmax、zpopmin、bzpopmax、bzpopmin、zrem、zremrangebyrank、zremrangebyscore
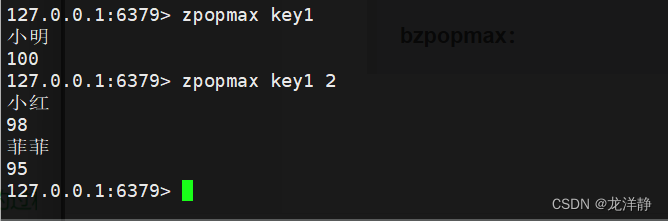
zpopmax:删除并返回分数最高的count个元素,默认为1
- 语法:zpopmax key [count]
- 返回值:分数和元素列表
- 时间复杂度:O(log(N)*M)----N指的是集合中元素个数;M指的是count
举例;
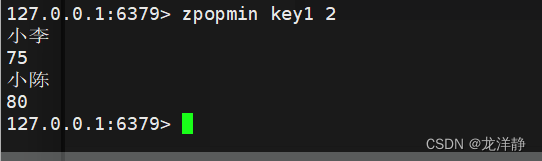
zpopmin:删除并返回分数最低的count个元素,默认为1
- 语法:zpopmin key [count]
- 返回值:分数和元素列表
- 时间复杂度:O(log(N)*M)----N指的是集合中元素个数;M指的是count
举例:
bzpopmax:zpopmax阻塞版本
- 语法:bzpopmax key [key...] timeout
- 返回值:分数和元素列表
- 时间复杂度:O(log(N)*M)----N指的是集合中元素个数;M指的是count
- 该命令阻塞时,redis依旧可以处理其他命令
bzpopmin:zpopmin阻塞版本
- 语法:bzpopmin key [key...] timeout
- 返回值:分数和元素列表
- 时间复杂度:O(log(N)*M)----N指的是集合中元素个数;M指的是count
- 该命令阻塞时,redis依旧可以处理其他命令
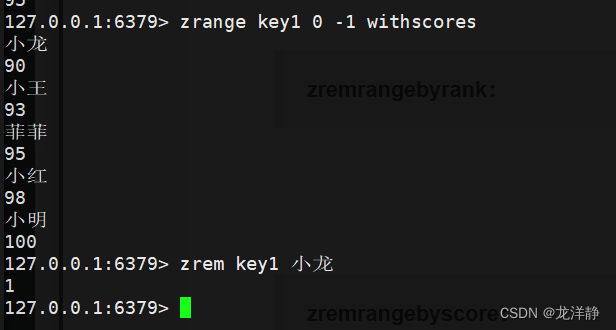
zrem:删除指定元素
- 语法:zrem key member [member...]
- 返回值:成功删除的元素个数
- 时间复杂度:O(M*log(N))-----N:整个集合中元素个数;M:member的个数
举例;
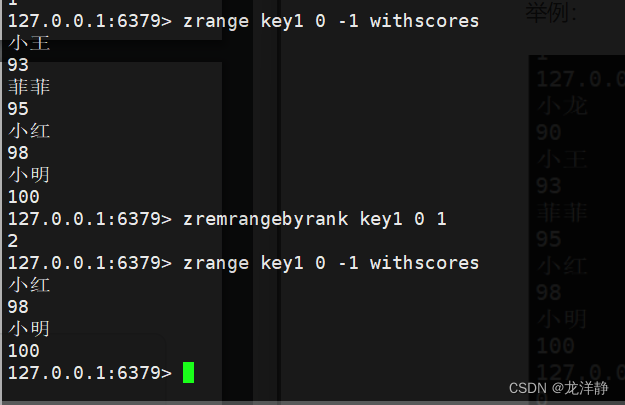
zremrangebyrank:按照升序,删除指定范围的元素
- 语法:zremrangebyrank key start stop
- 返回值:成功删除的元素个数
- 时间复杂度:O(log(N)+M)
举例:
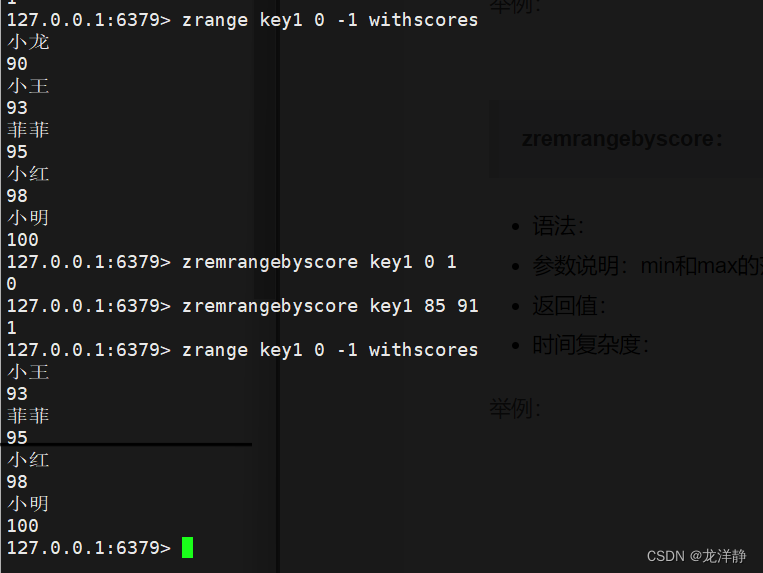
zremrangebyscore:按照分数删除指定区间范围的元素
- 语法:zremrangebyscore key min max
- 返回值:成功删除的元素个数
- 时间复杂度:O(log(N)+M)
举例:
2.5、返回指定元素的排名——zrank、zrevrank
zrank:返回指定元素的排名-升序
- 语法:zrank key member
- 返回值:该member的排名
- 时间复杂度:O(logN)
举例:
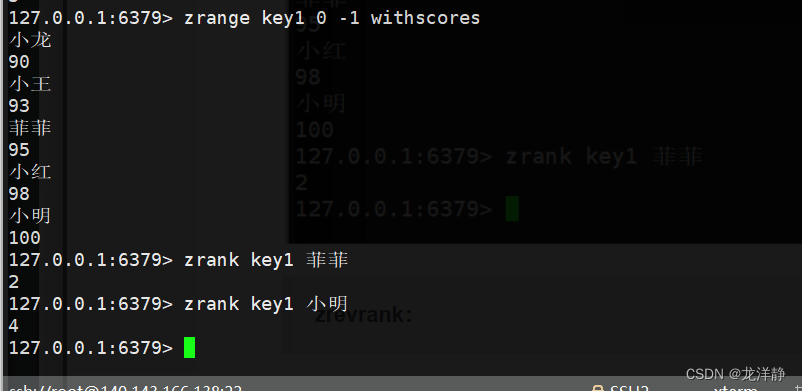
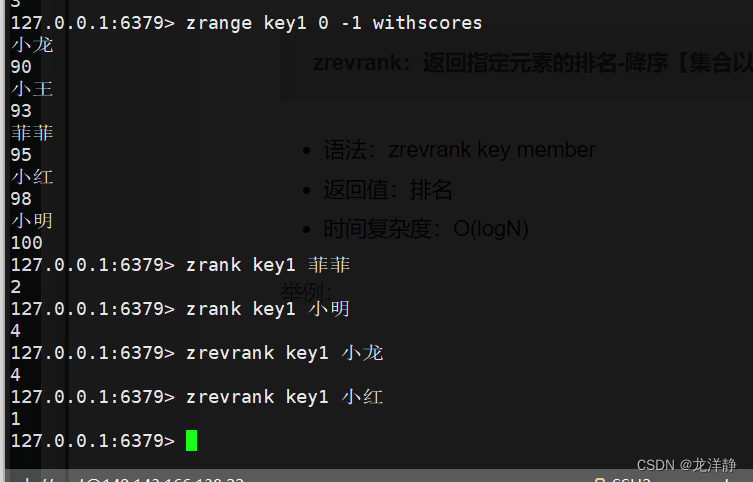
zrevrank:返回指定元素的排名-降序【集合以降序排列,指定元素的排名】
- 语法:zrevrank key member
- 返回值:排名
- 时间复杂度:O(logN)
举例:
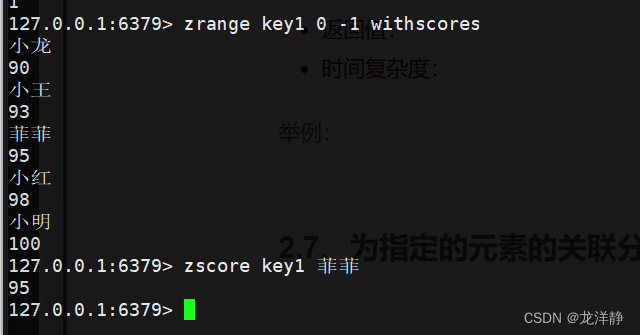
2.6、返回指定元素的分数——zscore
- zscore:返回指定元素的分数
- 语法:zscore key member
- 返回值:分数
- 时间复杂度:O(1)----这里也是要进行查询操作,为什么时间复杂度不是O(logN)呢?因为redis中对于这样的查询操作做了特殊优化,付出了额外的空间代价~
举例:
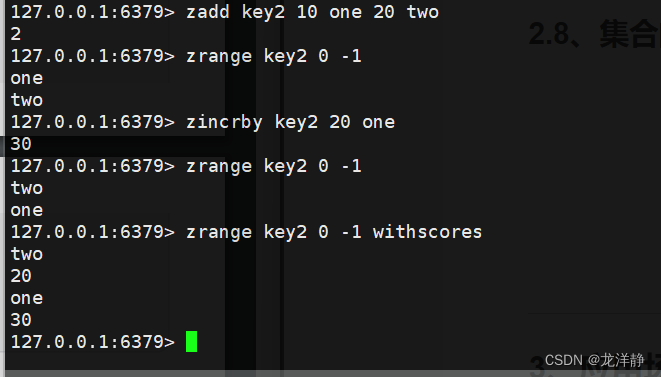
2.7、为指定的元素的关联分数添加指定的分数值——zincrby
- 语法:zincrby key incrment member
- 返回值:增加后元素的分数
- 时间复杂度:O(logN)
举例:
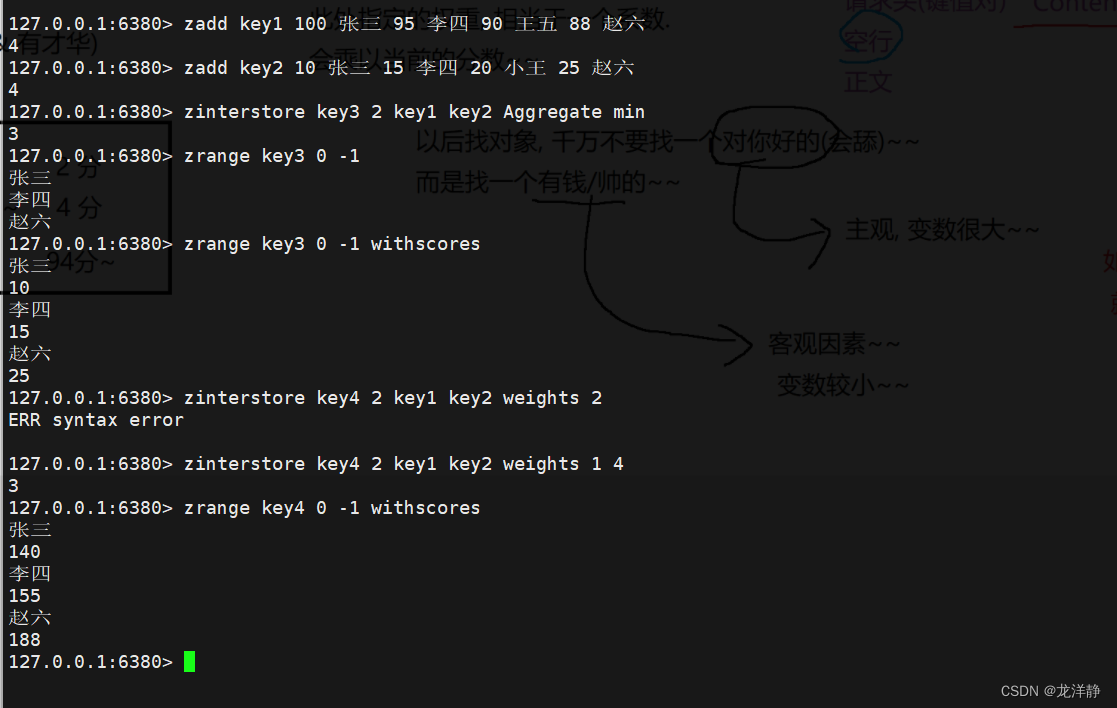
2.8、集合间操作:zinterstore、zunionstore
zinterstore:几个集合的交集,并将结果保存到另一个key中
- 语法:zinterstore destination numkeys key [key...] [WEIGHTS weight] [AGGREATE sum | min | max]
- 参数说明1:destination指的是交集结果存入到的目标key
- 参数说明2:numkeys指的是个数,后面有多少个key的个数。因为后面可能还有会其它参数,为了将key值与其他的参数做区分~
- 参数说明3:weights-->指的是指定每个key所占的权重,看下图举例中的最后一个命令,weights后面跟了一个 1 和 4,意思就是给前面对应位置的key1乘1,对应的key2乘4~【在应用场景排行榜中,例如总综测成绩排名可能涉及到成绩,和课外活动,而成绩占比百分之七十,课外活动占三十,就可以使用这个命令来解决此类问题】
- 参数说明4:AGGREATE-->解决的是在取交集时,number相同而score不同时,应当以谁为准,sum指score相加,min取最大小的score,max取最大的score【默认取sum】
- 返回值:目标集合中的元素个数
- 时间复杂度:O(N*K)+O(M*log(M))----N:输入的有序集合中,最小的集合的元素个数;K:输入了几个有序集合;M:最终结果的有序集合的元素个数
举例:
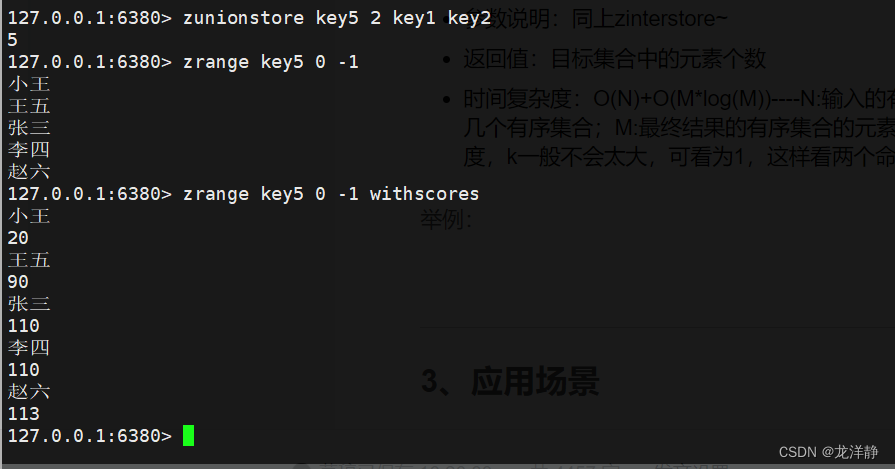
zunionstore:几个集合的并集,并将结果保存到另一个key中
- 语法:zunionstore destination numkeys key [key...] [WEIGHTS weight] [AGGREATE sum | min | max]
- 参数说明:同上zinterstore~
- 返回值:目标集合中的元素个数
- 时间复杂度:O(N)+O(M*log(M))----N:输入的有序集合中,最小的集合的元素个数;K:输入了几个有序集合;M:最终结果的有序集合的元素个数 【上一个命令zinterstore命令的时间复杂度,k一般不会太大,可看为1,这样看两个命令的时间复杂度就是一样的了~】
举例:
3、应用场景
排行榜——使用redis的zset实现排行榜,能够实时的保证排行榜的更新~文章来源:https://uudwc.com/A/Ev8P4
好啦,下期见咯~文章来源地址https://uudwc.com/A/Ev8P4