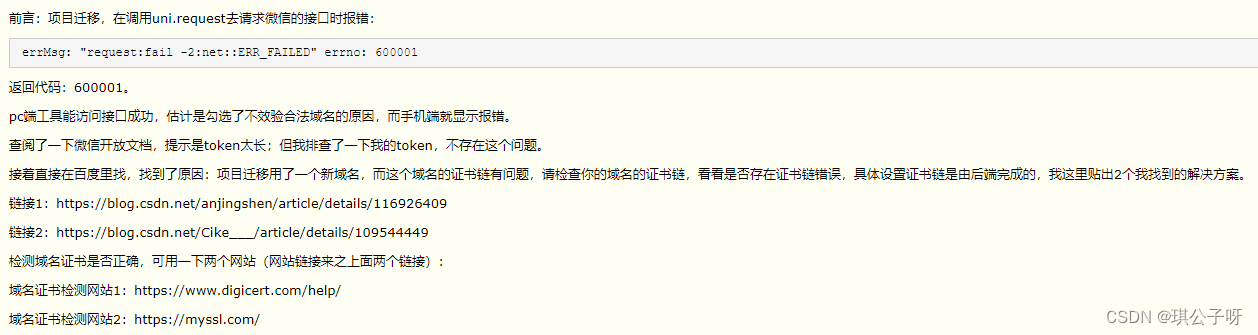
进行机器学习主要包含以下步骤:
获取数据:首先需要获取用于学习的数据,数据的质量和数量都会影响机器学习的效果。如果自己的数据量较少,可以尝试在网上寻找公开数据集进行训练,然后使用自己的数据进行微调。另一种方法是使用对抗网络生成更多的数据。
获取数据是机器学习的重要步骤之一。以下是一些获取数据的途径:
网上寻找公开数据集:这是一个非常常见的数据来源,一些常用的公开数据集包括Kaggle、Open Data、UCI Machine Learning Repository等。这些数据集通常包含大量数据和详细的标签,非常适合用来训练和测试机器学习模型。
自己的数据:如果你在自己的业务中拥有大量数据,那么可以使用这些数据进行训练和微调。这些数据可能包括用户行为数据、交易数据、传感器数据等。不过需要注意的是,自己的数据量可能较少,需要合理利用并选择合适的数据清洗和预处理方法。
生成更多的数据:如果自己的数据量不足或者质量不高,可以使用生成对抗网络(GAN)等技术来生成更多的数据。这些数据可以用来扩充数据集,提高模型的泛化能力。
无论使用哪种方法获取数据,都需要关注数据的质量和数量。好的数据可以训练出更好的模型,提高模型的准确率和泛化能力。同时,不同的数据源也可能需要不同的数据清洗和预处理方法,以确保数据的准确性和可靠性。
数据预处理与特征选择:从原始数据中提取出良好的特征,让机器学习算法能够更好地学习并做出准确的预测。数据预处理包括数据清洗、归一化、离散化、因子化、缺失值处理、去除共线性等步骤。特征选择是关键的一步,需要仔细筛选出与目标任务相关的显著特征,摒弃非显著特征。这需要深入理解业务,并运用特征有效性分析的相关技术,如相关系数、卡方检验、平均互信息、条件熵、后验概率、逻辑回归权重等方法。
选择合适的算法:根据特定任务的需求,选择合适的机器学习算法。监督学习是机器学习中最常用的方法,其中包括线性回归、逻辑回归、决策树、深度神经网络等算法。
训练模型:使用获取的数据和选择的算法训练模型。训练过程中,通常会使用到各种参数,包括学习率、迭代次数、隐藏层数等。
验证与调整:训练完模型后,需要通过验证数据来评估模型的性能,并根据验证结果对模型进行调整。
应用模型:当模型经过验证并确定达到预期效果后,可以将其应用于实际场景中,例如进行文本分类、图像识别、推荐系统等任务。
以上就是进行机器学习的主要步骤,希望对你有所帮助。如有更深入或具体的需求,建议咨询专业的机器学习工程师或查阅相关文献。
附录:为什么要使用激活函数
激活函数在神经网络中扮演着重要的角色,它的主要作用包括:
增加模型的非线性表达能力:激活函数引入了非线性因素,使得神经网络能够更好地学习和表示复杂的非线性输入输出关系,从而提高了模型的表达能力。
实现隐含层的输出转换:激活函数将隐含层的输出进行非线性转换,将输入数据映射到输出层,这个过程有助于解决各种复杂的分类和回归问题。
增加模型的鲁棒性:加入激活函数可以增加模型的鲁棒性,对于输入数据的小的扰动,模型不会产生太大的误差,提高了模型的鲁棒性。
防止过拟合:激活函数有助于增加模型的复杂度,同时在一定程度上可以防止过拟合问题。
因此,使用激活函数对于神经网络的性能和效果至关重要。文章来源:https://uudwc.com/A/EvRGm
文章来源地址https://uudwc.com/A/EvRGm