目录
Flink是什么
Flink部署模式
会话模式(Session Mode )
单作业模式(Per-Job Mode)
应用模式(Application Mode)
Flink集群搭建
Standalone运行模式
会话模式
单作业模式部署
应用模式部署
YARN运行模式
会话模式部署
单作业模式部署
应用模式部署
文章来源地址https://uudwc.com/A/GywjA
Flink是什么
Flink是“数据流上的有状态计算”
具体说明是:Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。

Flink部署模式
会话模式(Session Mode )、单作业模式(Per-Job Mode)、应用模式(Application Mode)
它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的main方法到底在哪里执行——客户端(Client)还是JobManager。
会话模式(Session Mode )
会话模式是最符合常规思维的,我们需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业。集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源。

会话模式比较适用于单个规模小、执行时间短的大量作业
单作业模式(Per-Job Mode)
单作业模式是每提交一个作业启动一个集群,实现资源的隔离。作业完成后,集群就会关闭,所有资源也会释放。单作业模式在生产环境运行更加的稳定,所有也是实际应用的首选模式。
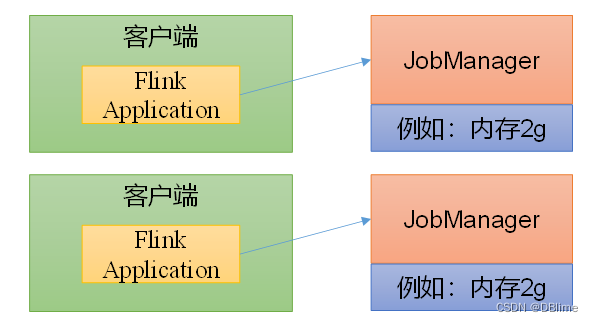
Flink本身无法直接这样运行,需要借助一些资源管理框架来启动集群,比如yarn、Kubernetes(K8S)
应用模式(Application Mode)
前面提到的两种模式 下,应用代码都是在容广端上执行,然后由客广端提交给JobManager。但是这种方式客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给JobManager;加上很多情況下我们提交作业用的是同一个客户端,就会加重客户端所在节点的资源消耗。
所以解决办法就是,我们不要客户端了,直接把应用提交到JobManager 上运行。而这也就代表着,我们需要为每一个提交的应用单独启动一个JobManager,也就是创建一个集群。这个JobManager只为执行这一个应用而存在,执行结束之后JobManager也就关闭了,这就是所谓的应用模式。

应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接用JobManager执行应用程序的。
Flink集群搭建
Standalone运行模式
会话模式
0)集群规划
集群角色分配
| 节点服务器 |
hadoop102 |
hadoop103 |
hadoop104 |
| 角色 |
JobManager TaskManager |
TaskManager |
TaskManager |
具体安装部署步骤如下:
1)下载并解压安装包
(1)下载安装包flink-1.13.1-bin-scala_2.12.tgz,注意此处选用对应scala版本为scala 2.12的安装包。将该jar包上传到hadoop102节点服务器的/opt/software路径上。
(2)在/opt/software路径上解压flink-1.13.0-bin-scala_2.12.tgz到/opt/module路径上。
[DBlime@hadoop102 software]$ tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/
2)修改集群配置
(1)进入conf路径,修改flink-conf.yaml文件,指定hadoop102节点服务器为JobManager
[DBlime@hadoop102 conf]$ vim flink-conf.yaml
修改如下内容:
# JobManager节点地址.
jobmanager.rpc.address: hadoop102
(2)修改workers文件,指定hadoop103和hadoop104为TaskManager
[DBlime@hadoop102 conf]$ vim workers
修改如下内容:
hadoop102
hadoop103
hadoop104
(3)另外,在flink-conf.yaml文件中还可以对集群中的JobManager和TaskManager组件进行优化配置,主要配置项如下:
- jobmanager.memory.process.size:对JobManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1600M,可以根据集群规模进行适当调整。
- taskmanager.memory.process.size:对TaskManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1728M,可以根据集群规模进行适当调整。
- taskmanager.numberOfTaskSlots:对每个TaskManager能够分配的Slot数量进行配置,默认为1,可根据TaskManager所在的机器能够提供给Flink的CPU数量决定。所谓Slot就是TaskManager中具体运行一个任务所分配的计算资源。
- parallelism.default:Flink任务执行的并行度,默认为1。优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量。
关于Slot和并行度的概念,我们会在下一章做详细讲解。
3)分发安装目录
配置修改完毕后,将Flink安装目录发给另外两个节点服务器。
[DBlime@hadoop102 module]$ xsync flink-1.13.0/
4)启动集群
(1)在hadoop102节点服务器上执行start-cluster.sh启动Flink集群:
[DBlime@hadoop102 flink-1.13.1]$ bin/start-cluster.sh
(2)查看进程情况:
[DBlime@hadoop102 flink-1.13.1]$ jpsall
=============== hadoop102 ===============
4453 StandaloneSessionClusterEntrypoint
4533 Jps
=============== hadoop103 ===============
2872 TaskManagerRunner
2941 Jps
=============== hadoop104 ===============
2948 Jps
2876 TaskManagerRunner
5)访问Web UI
启动成功后,同样可以访问http://hadoop102:8081对flink集群和任务进行监控管理。

单作业模式部署
Flink的Standalone集群并不支持单作业模式部署。因为单作业模式需要借助一些资源管理平台。
应用模式部署
应用模式下不会提前创建集群,所以不能调用start-cluster.sh脚本。我们可以使用同样在bin目录下的standalone-job.sh来创建一个JobManager。

具体步骤如下:
(0)环境准备。在hadoop102中执行以下命令启动netcat。
[DBlime@hadoop102 flink-1.13.1]$ nc -lk 7777
(1)进入到Flink的安装路径下,将应用程序的jar包放到lib/目录下。
[DBlime@hadoop102 flink-1.13.1]$ mv FlinkTutorial-1.0-SNAPSHOT.jar lib/
(2)执行以下命令,启动JobManager。
[DBlime@hadoop102 flink-1.13.1]$ bin/standalone-job.sh start --job-classname com.DBlime.wc.SocketStreamWordCount
这里我们直接指定作业入口类,脚本会到lib目录扫描所有的jar包。
(3)同样是使用bin目录下的脚本,启动TaskManager。
[DBlime@hadoop102 flink-1.13.1]$ bin/taskmanager.sh start
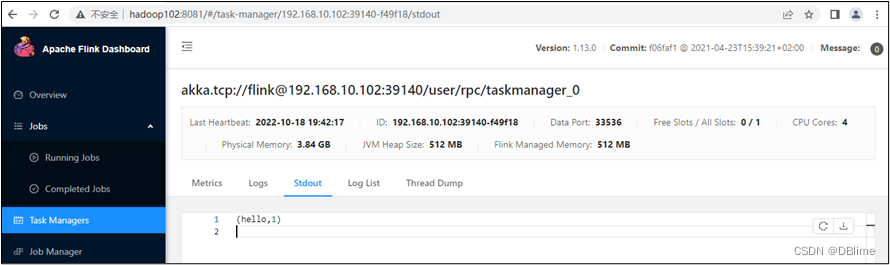
(4)在hadoop102上模拟发送单词数据。
[DBlime@hadoop102 ~]$ nc -lk 7777
hello
(5)在hadoop102:8081地址中观察输出数据
YARN运行模式
相关准备和配置
在将Flink任务部署至YARN集群之前,需要确认集群是否安装有Hadoop,保证Hadoop版本至少在2.2以上,并且集群中安装有HDFS服务。
具体配置步骤如下:
(1)配置环境变量,增加环境变量配置如下:
$ sudo vim /etc/profile.d/my_env.sh
HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
(2)启动Hadoop集群,包括HDFS和YARN。
[DBlime@hadoop102 hadoop-3.1.3]$ start-dfs.sh
[DBlime@hadoop103 hadoop-3.1.3]$ start-yarn.sh
(3)在hadoop102中执行以下命令启动netcat。
[DBlime@hadoop102 flink-1.13.1]$ nc -lk 7777
会话模式部署
YARN的会话模式与独立集群略有不同,需要首先申请一个YARN会话(YARN Session)来启动Flink集群。具体步骤如下:
1)启动集群
(1)启动Hadoop集群(HDFS、YARN)。
(2)执行脚本命令向YARN集群申请资源,开启一个YARN会话,启动Flink集群。
[DBlime@hadoop102 flink-1.13.1]$ bin/yarn-session.sh -nm test
可用参数解读:
- -d:分离模式,如果你不想让Flink YARN客户端一直前台运行,可以使用这个参数,即使关掉当前对话窗口,YARN session也可以后台运行。
- -jm(--jobManagerMemory):配置JobManager所需内存,默认单位MB。
- -nm(--name):配置在YARN UI界面上显示的任务名。
- -qu(--queue):指定YARN队列名。
- -tm(--taskManager):配置每个TaskManager所使用内存。
注意:Flink1.11.0版本不再使用-n参数和-s参数分别指定TaskManager数量和slot数量,YARN会按照需求动态分配TaskManager和slot。所以从这个意义上讲,YARN的会话模式也不会把集群资源固定,同样是动态分配的。
YARN Session启动之后会给出一个Web UI地址以及一个YARN application ID,如下所示,用户可以通过Web UI或者命令行两种方式提交作业。
2023-4-7 15:20:52,711 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hadoop104:40825 of application 'application_1668668287070_0005'.
JobManager Web Interface: http://hadoop104:40825
2)提交作业
(1)通过Web UI提交作业
这种方式比较简单,与上文所述Standalone部署模式基本相同。

(2)通过命令行提交作业
① 将FlinkTutorial-1.0-SNAPSHOT.jar任务上传至集群。
② 执行以下命令将该任务提交到已经开启的Yarn-Session中运行。
[DBlime@hadoop102 flink-1.13.0]$ bin/flink run
-c com.DBlime.wc.SocketStreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
客户端可以自行确定JobManager的地址,也可以通过-m或者-jobmanager参数指定JobManager的地址,JobManager的地址在YARN Session的启动页面中可以找到。
也可通过以下命令指定job提交到哪个会话集群中,标红指的是会话集群在yarn上面的applicationId
bin/flink run -t yarn-session -Dyarn.application.id=application_1676965346833_0001 -c com.DBlime.day01.Flink03_Stream_Unbounded_WordCount xxxx.jar
③ 任务提交成功后,可在YARN的Web UI界面查看运行情况。hadoop103:8088。
单作业模式部署
在YARN环境中,由于有了外部平台做资源调度,所以我们也可以直接向YARN提交一个单独的作业,从而启动一个Flink集群。
(1)执行命令提交作业。
[DBlime@hadoop102 flink-1.13.0]$ bin/flink run -d -t yarn-per-job -c com.DBlime.wc.SocketStreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
注意:如果启动过程中报如下异常。
Exception in thread “Thread-5” java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration ‘classloader.check-leaked-classloader’.
at org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders
解决办法:在flink的/opt/module/flink-1.13.1/conf/flink-conf.yaml配置文件中设置
[DBlime@hadoop102 conf]$ vim flink-conf.yaml
classloader.check-leaked-classloader: false
(2)可以使用命令行查看或取消作业,命令如下。
[DBlime@hadoop102 flink-1.13.1]$ bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
[DBlime@hadoop102 flink-1.13.1]$ bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
这里的application_XXXX_YY是当前应用的ID,<jobId>是作业的ID。注意如果取消作业,整个Flink集群也会停掉。
应用模式部署
应用模式同样非常简单,与单作业模式类似,直接执行flink run-application命令即可。
(1)执行命令提交作业。
[DBlime@hadoop102 flink-1.13.1]$ bin/flink run-application -t yarn-application -c com.DBlime.wc.SocketStreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
(2)在命令行中查看或取消作业。
[DBlime@hadoop102 flink-1.13.1]$ bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
[DBlime@hadoop102 flink-1.13.1]$ bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>
(3)也可以通过yarn.provided.lib.dirs配置选项指定位置,将jar上传到远程。
[DBlime@hadoop102 flink-1.13.1]$ bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://myhdfs/my-remote-flink-dist-dir" -c xxx.xxx.wordCount hdfs://myhdfs/jars/my-application.jar
这种方式下jar可以预先上传到HDFS,而不需要单独发送到集群,这就使得作业提交更加轻量了。文章来源:https://uudwc.com/A/GywjA
