参考资料:
【word2vec词向量模型】原理详解+代码实现
NLP自然语言处理的经典模型Word2vec
论文背景知识
词的表示方法
One-hot Representation:独热表示
简单,但词越多,向量越长。且无法表示词与词之间的关系。
论文储备知识-pre-knowledge
语言模型的概念
语言模型是计算一个句子是句子的概率的模型。(语法和语义上)
语言模型的发展
基于专家语法规则的语言模型
语言学家企图总结出一套通用的语法规则,比如形容词后面接名词等。
统计语言模型
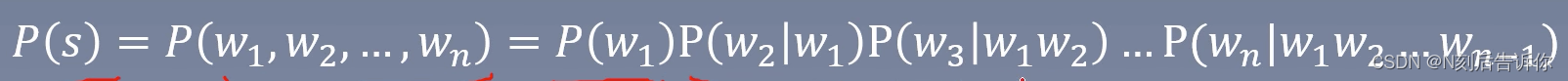


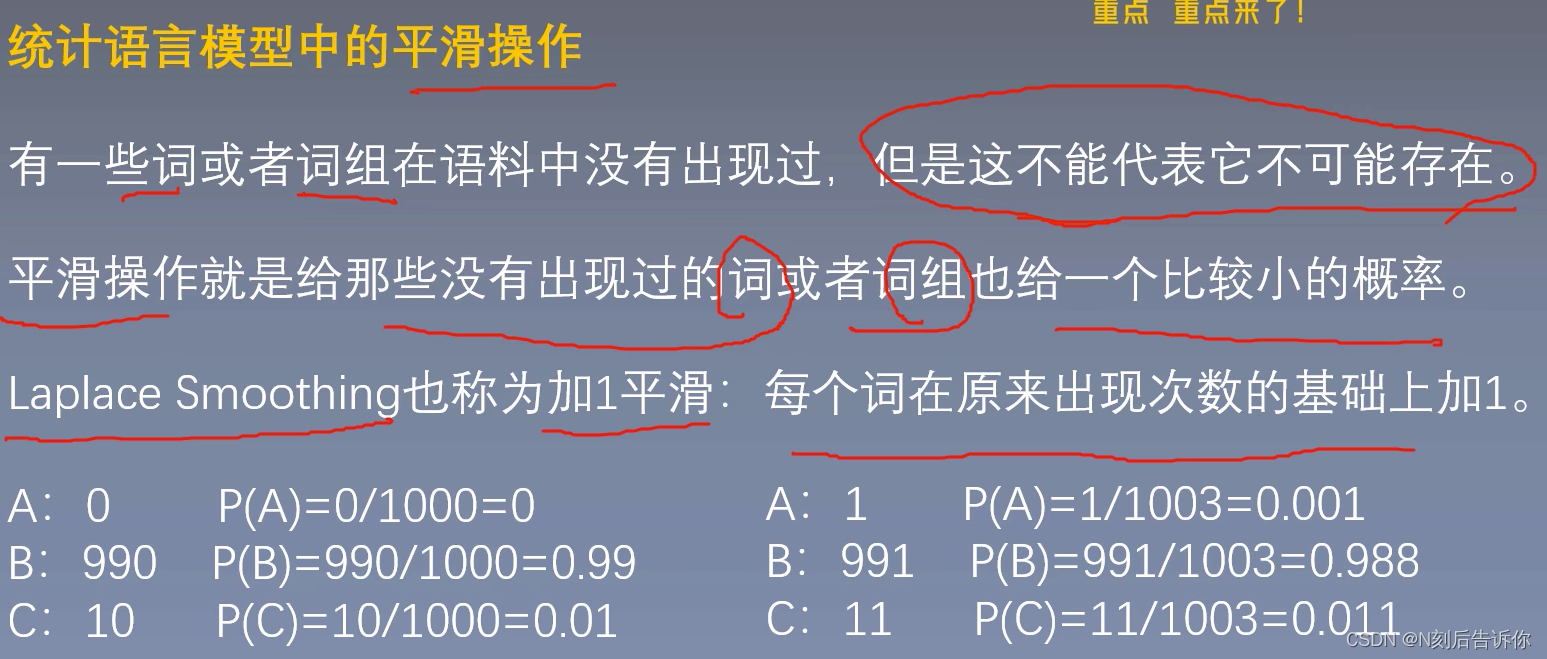
有些词可能没出现在语料中,或者短语太长了。所以概率为0。为了解决这个问题,下面提出统计语言模型中的平滑操作。
统计语言模型中的平滑操作
但这只解决了词的概率。
为了解决参数空间过大的问题,引入马尔可夫假设。
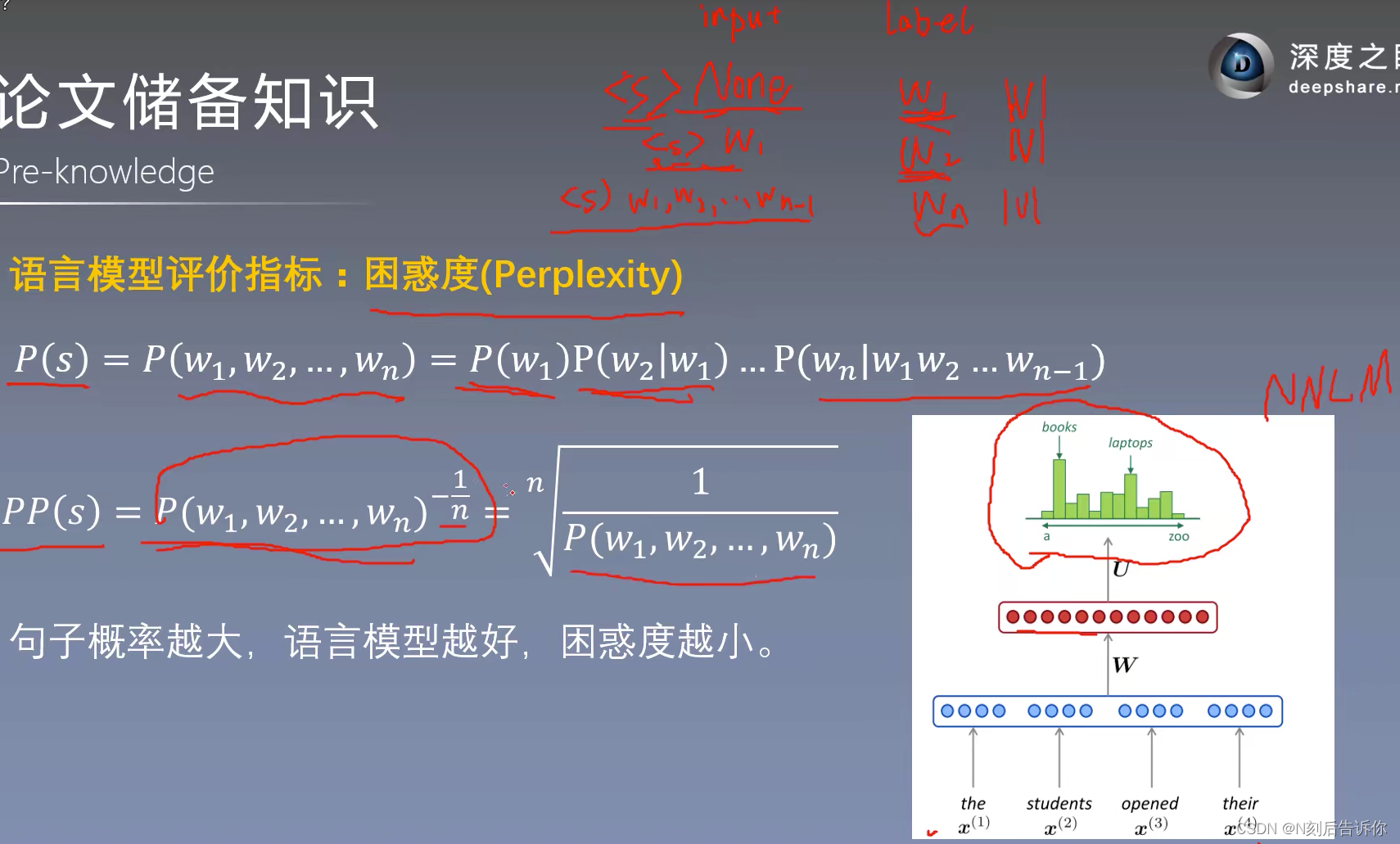
语言模型的评价指标
每个领域都有自己的评价指标。
语言模型可以看成是多分类问题
开n次方根是为了避免长句子的概率比小句子概率小,导致评价偏颇
对比模型
NNLM
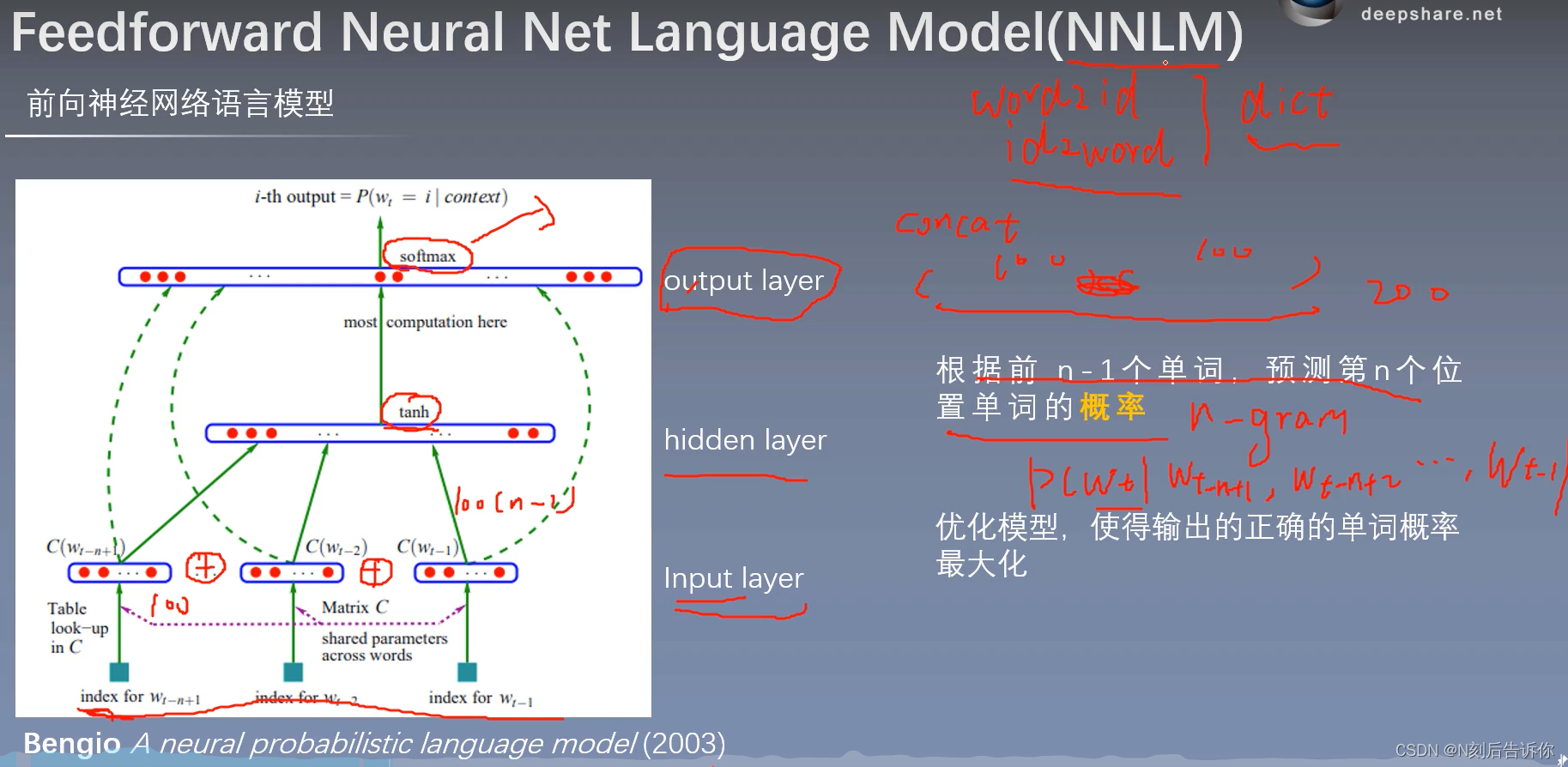
语言模型是无监督的,不需要标注语料。
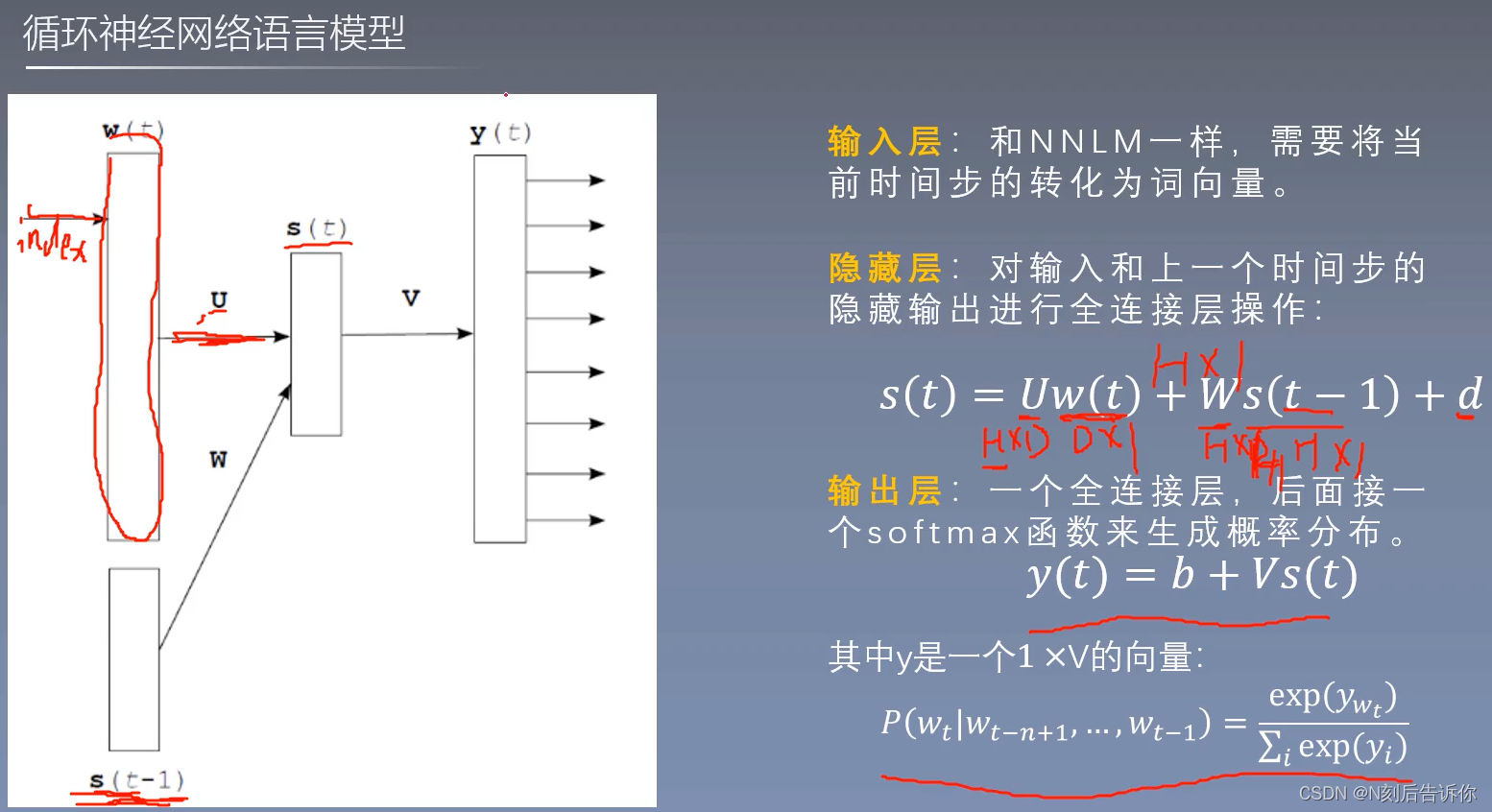
输入层
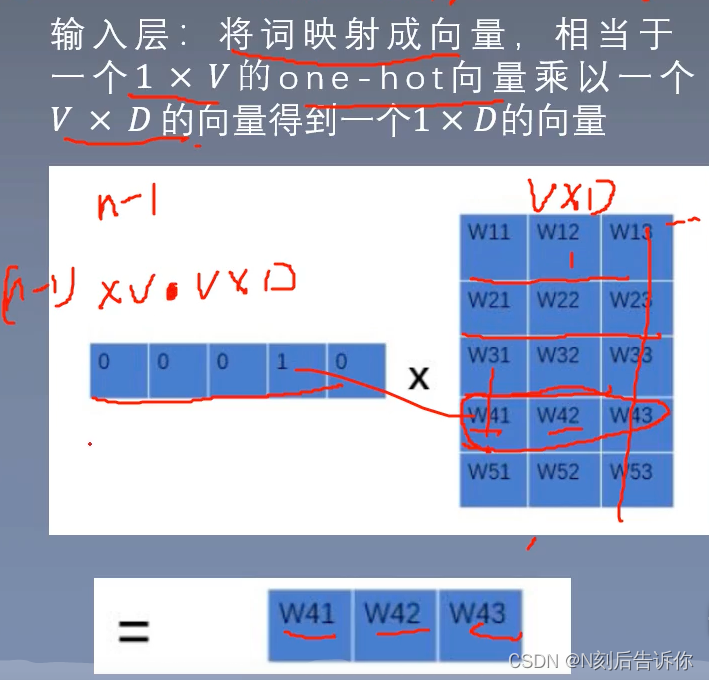
能不写成循环,写成矩阵就写成矩阵。能降低复杂度。
隐藏层
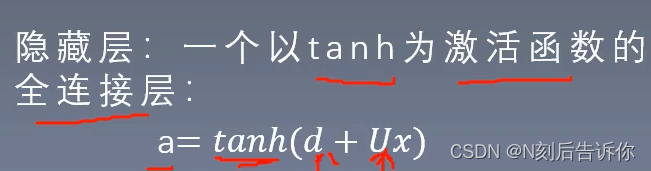
输出层

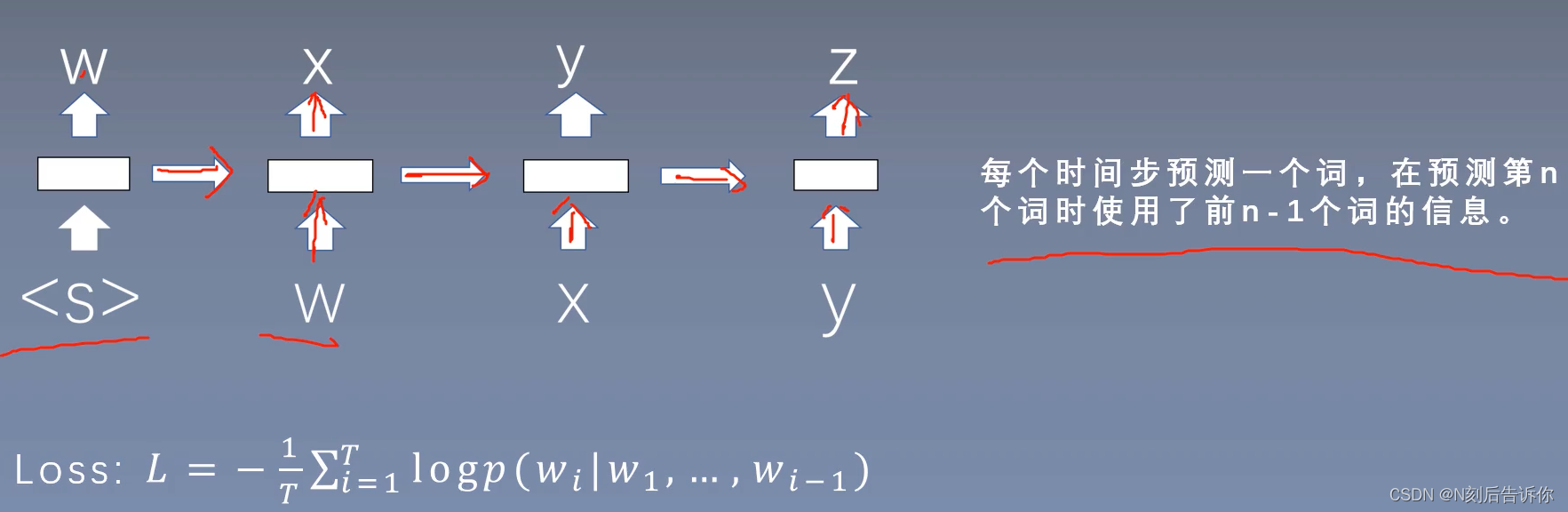
Loss

batchsize是一种tradeoff
由于句子长度不一,所以要补pad,但是最后要去掉
RNNLM
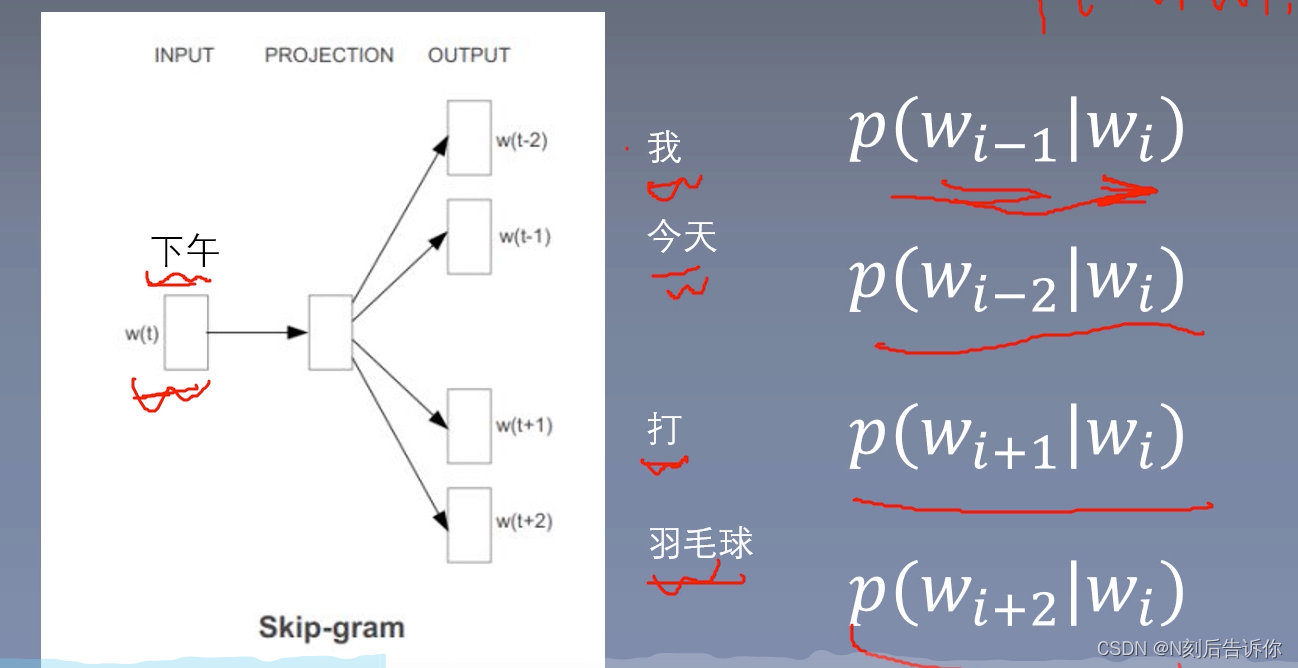
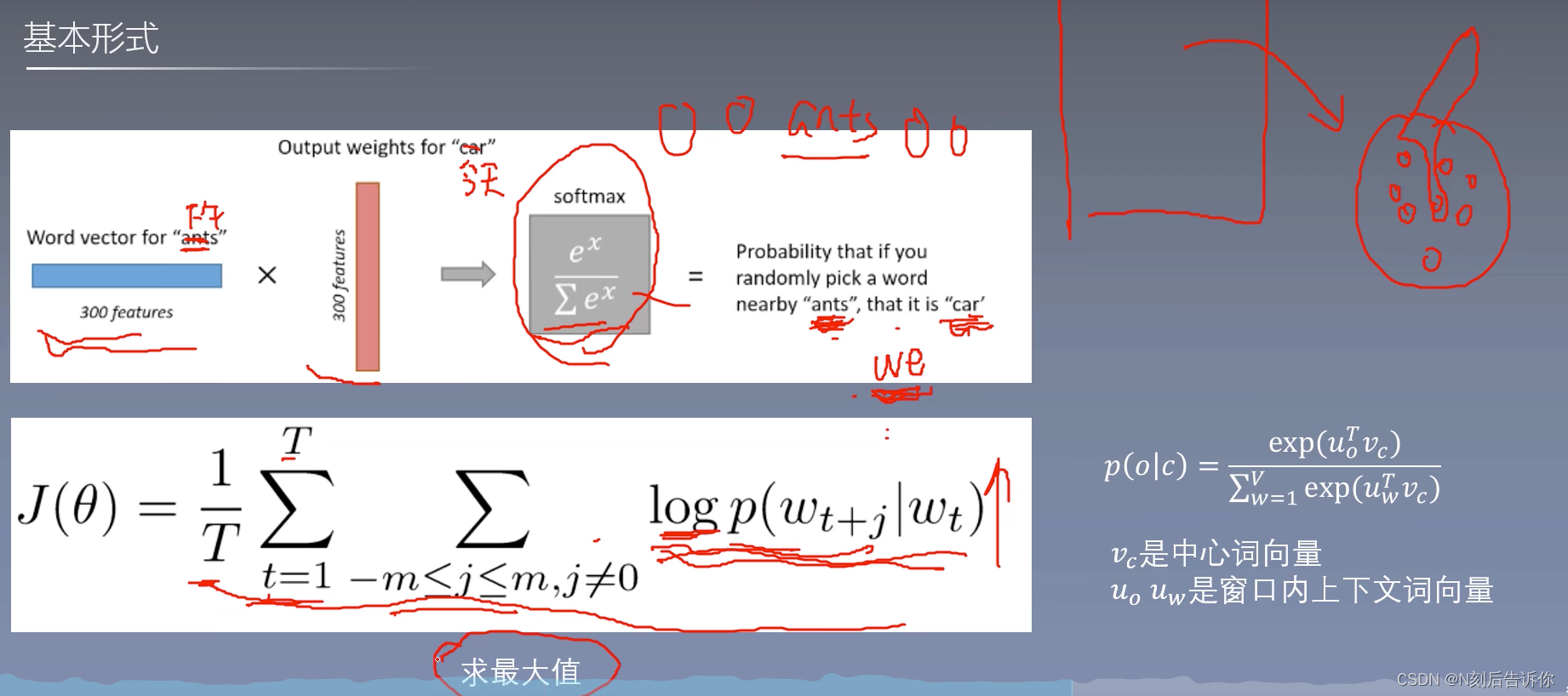
word2vec

多分类下的逻辑回归模型也是Log线性模型。
下面的skip-gram和cbow也都是Log线性模型。
word2vec的原理

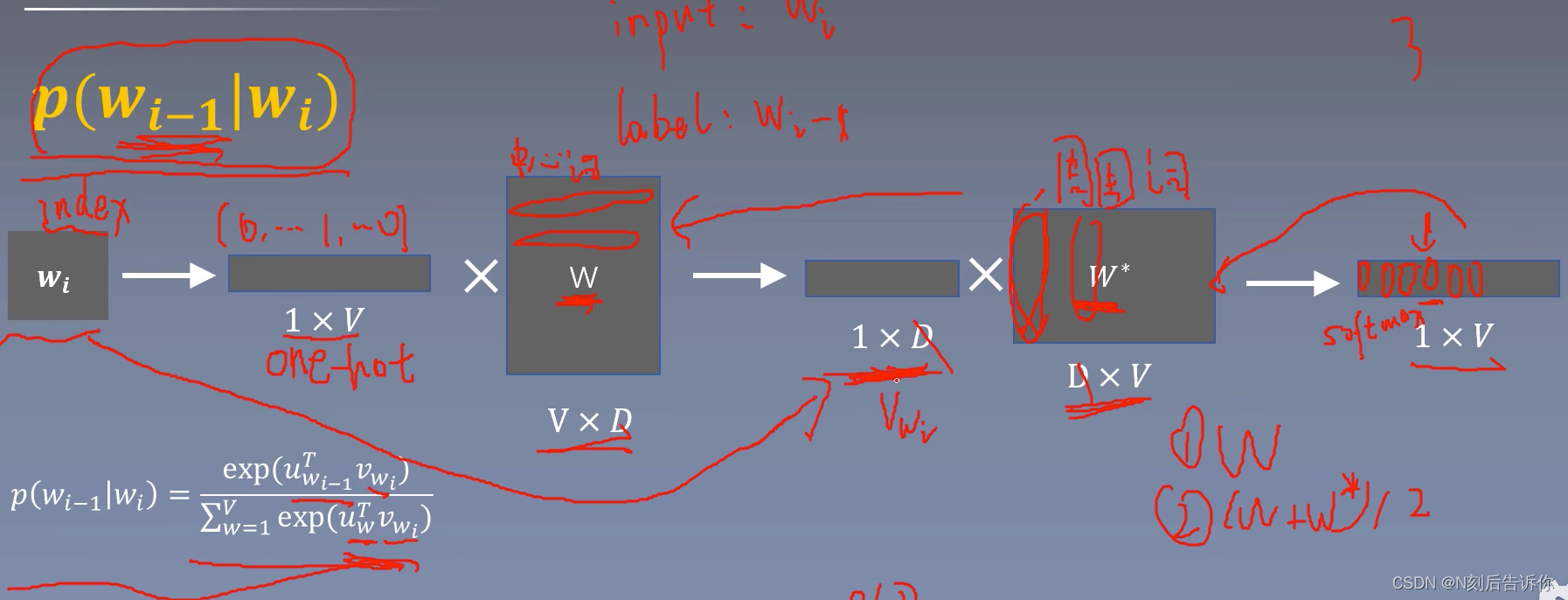
skip-gram
cbow
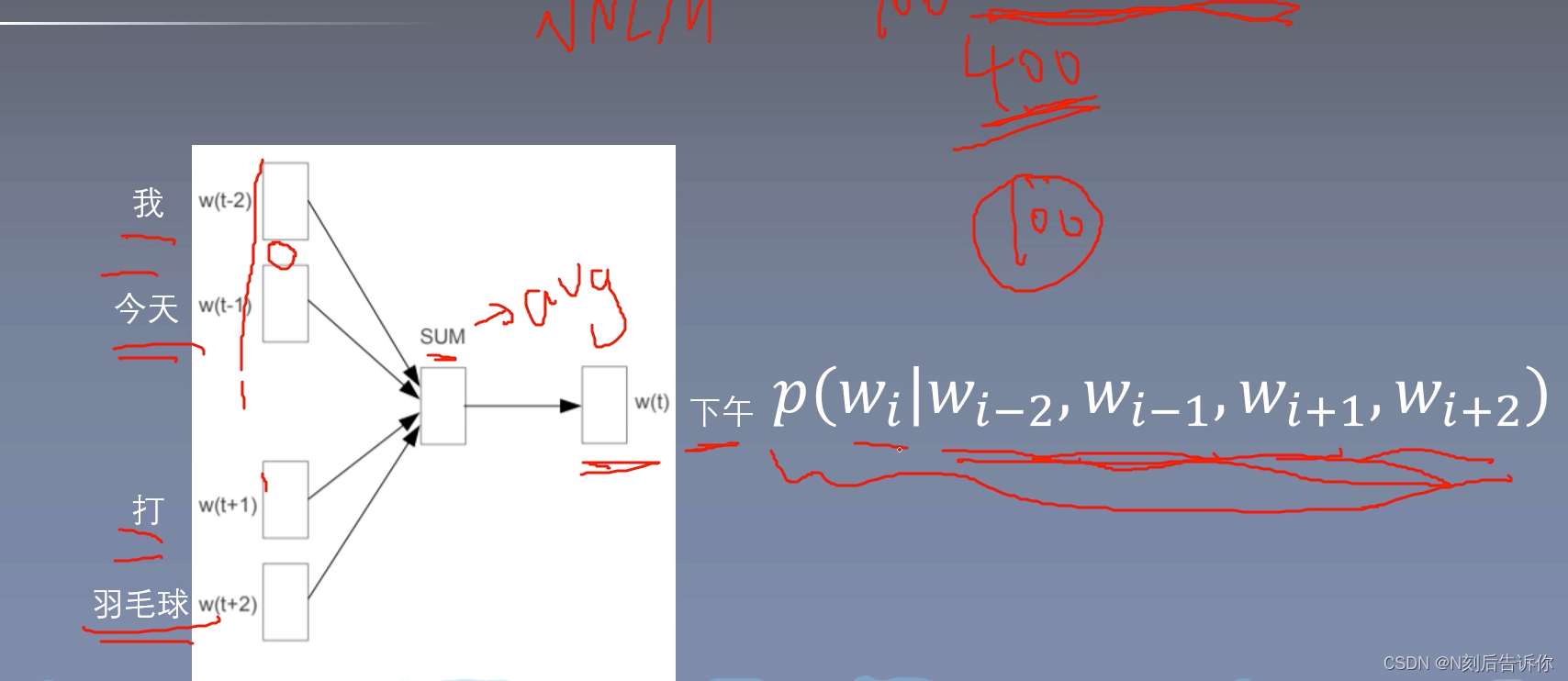
词袋模型,忽略词的顺序。
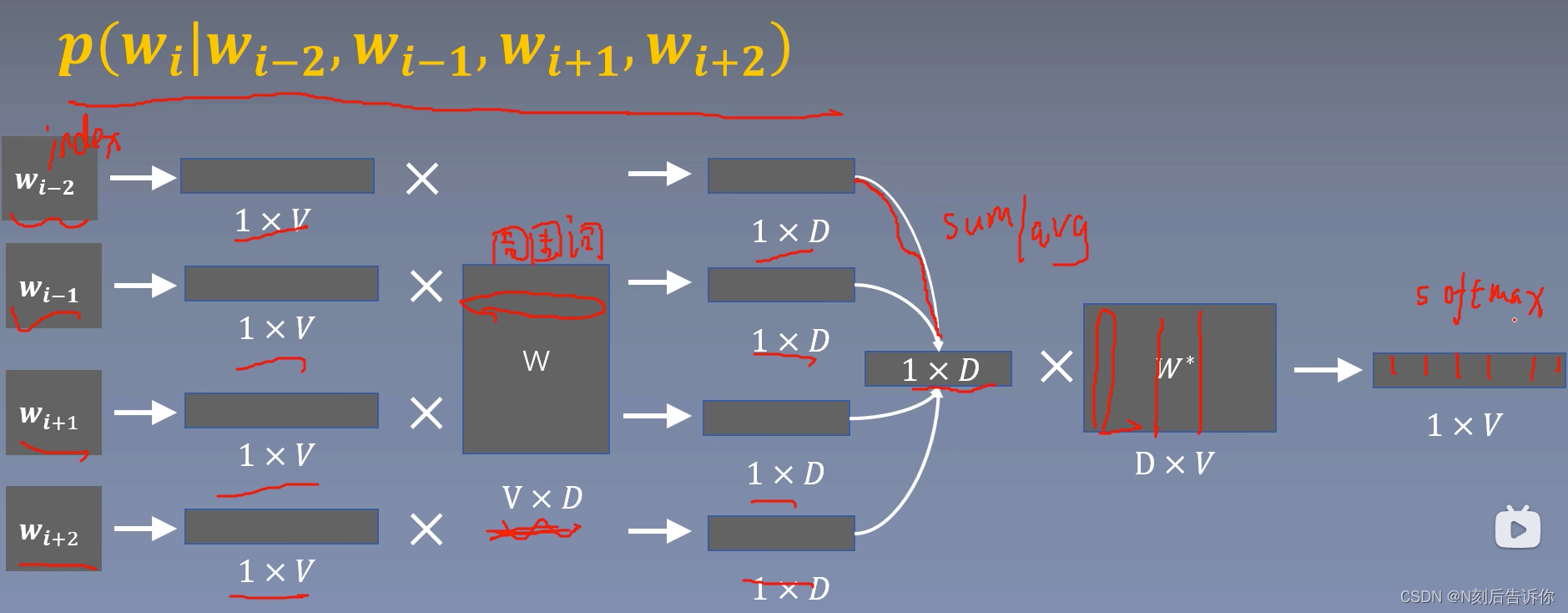

关键技术
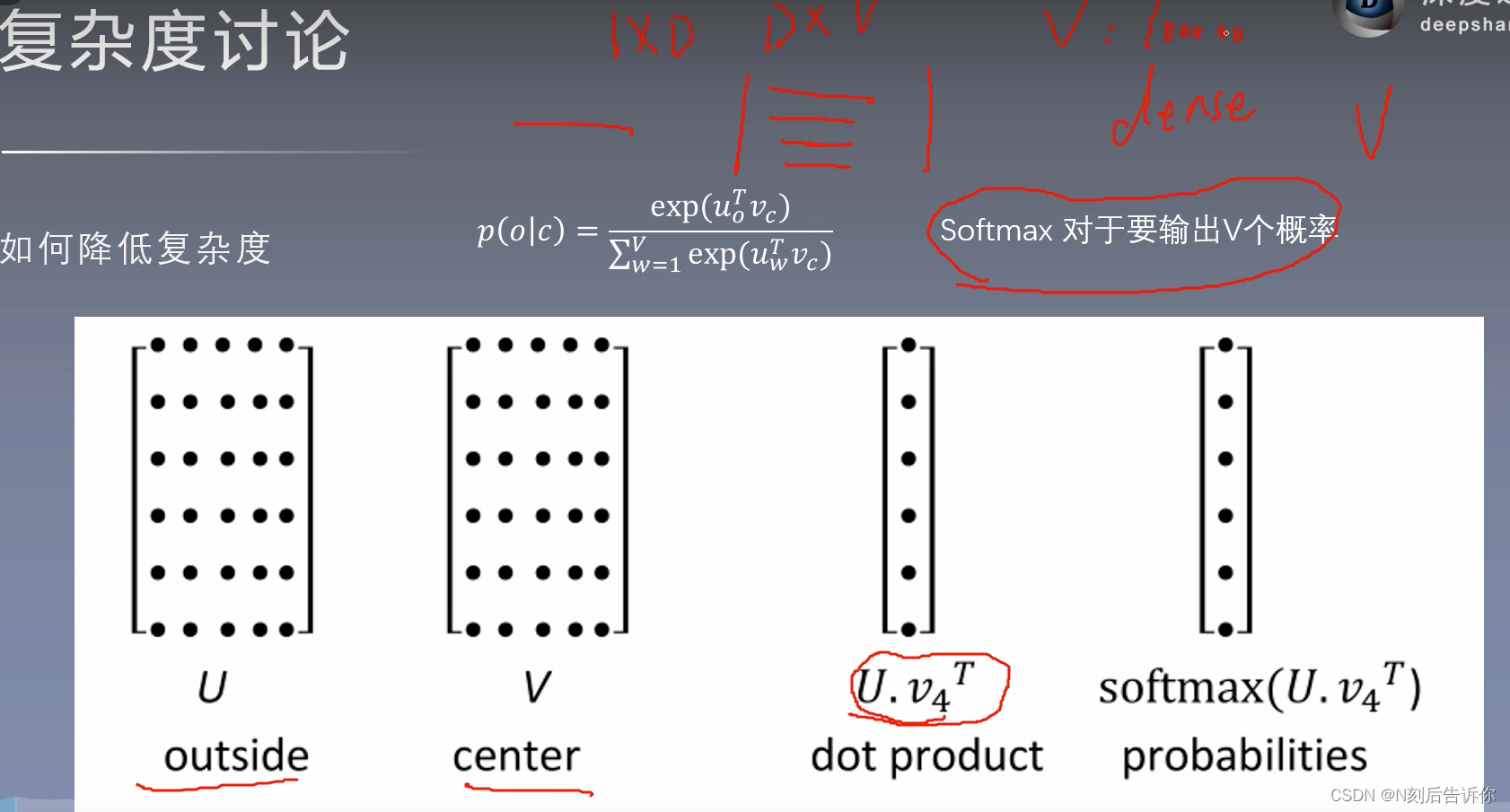
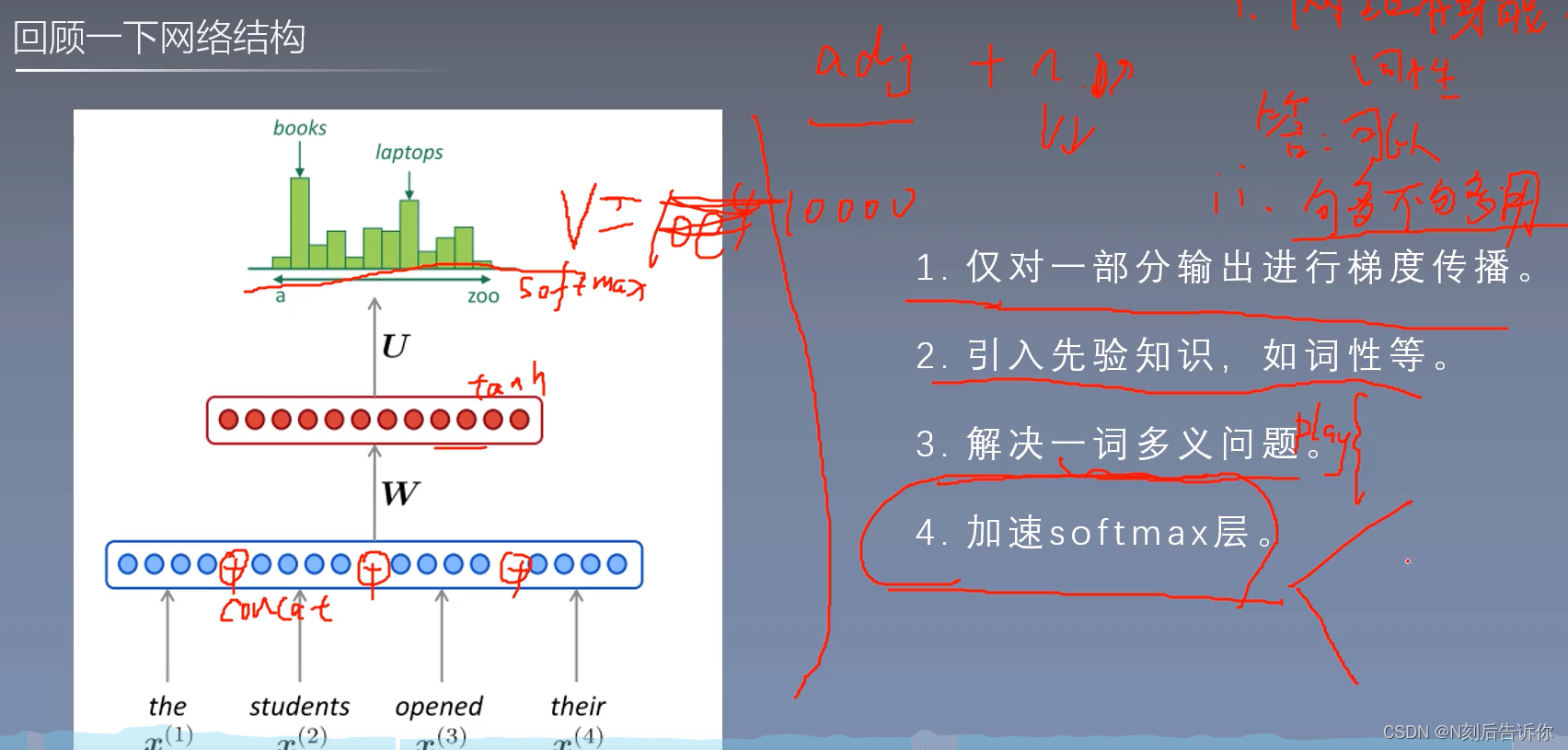
需要降低softmax的复杂度。
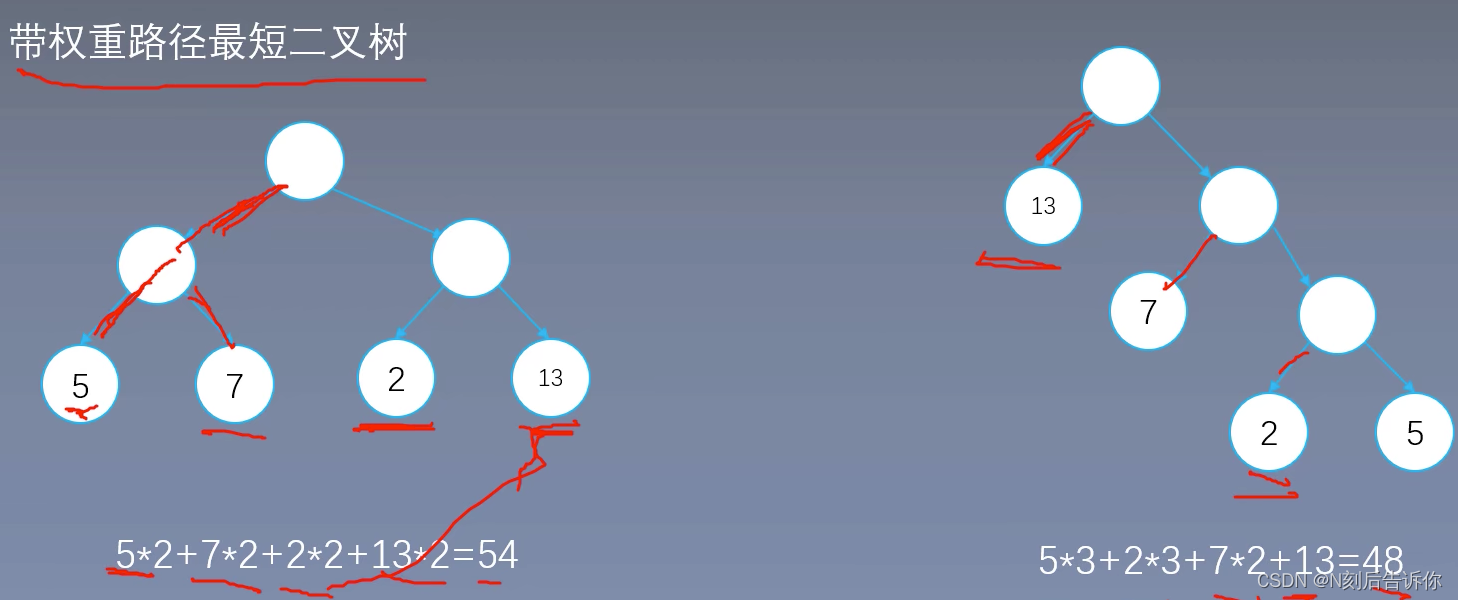
层次softmax
将softmax计算转化为求sigmoid的计算
写成二叉树的结构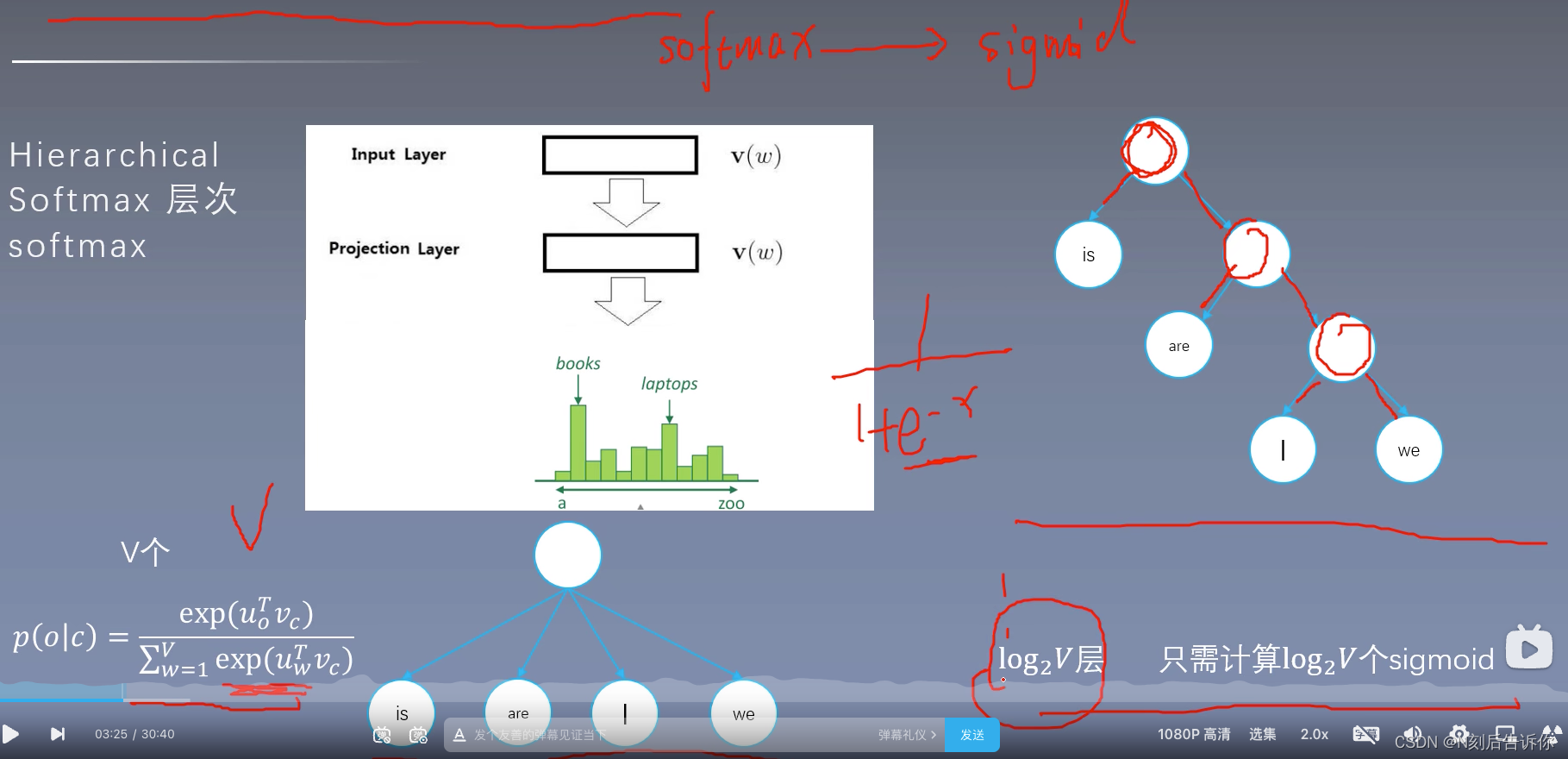
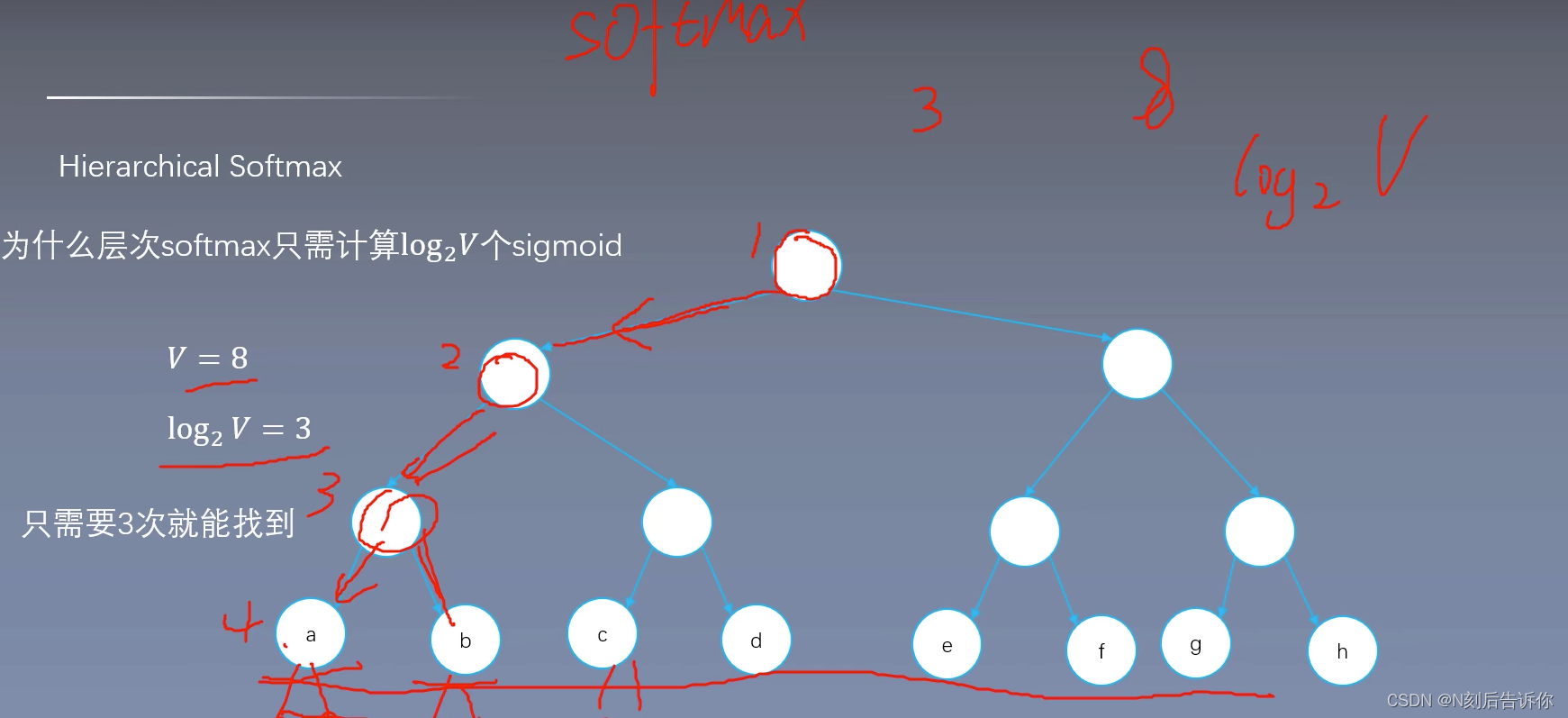
skip-gram中的层次softmax


cbow中的层次softmax

与skip-gram的层次softmax的区别是u0是上下文词向量avg
skip-gram只有一组完整的中心词向量,没法像之前一样将中心词向量和周围词向量相加求平均
cbow只有一组完整的周围词向量
负采样
思想:将多分类转化为二分类问题。
负采样效果比层次softmax要好。
一般采样3-10个负样本
skip-gram负采样
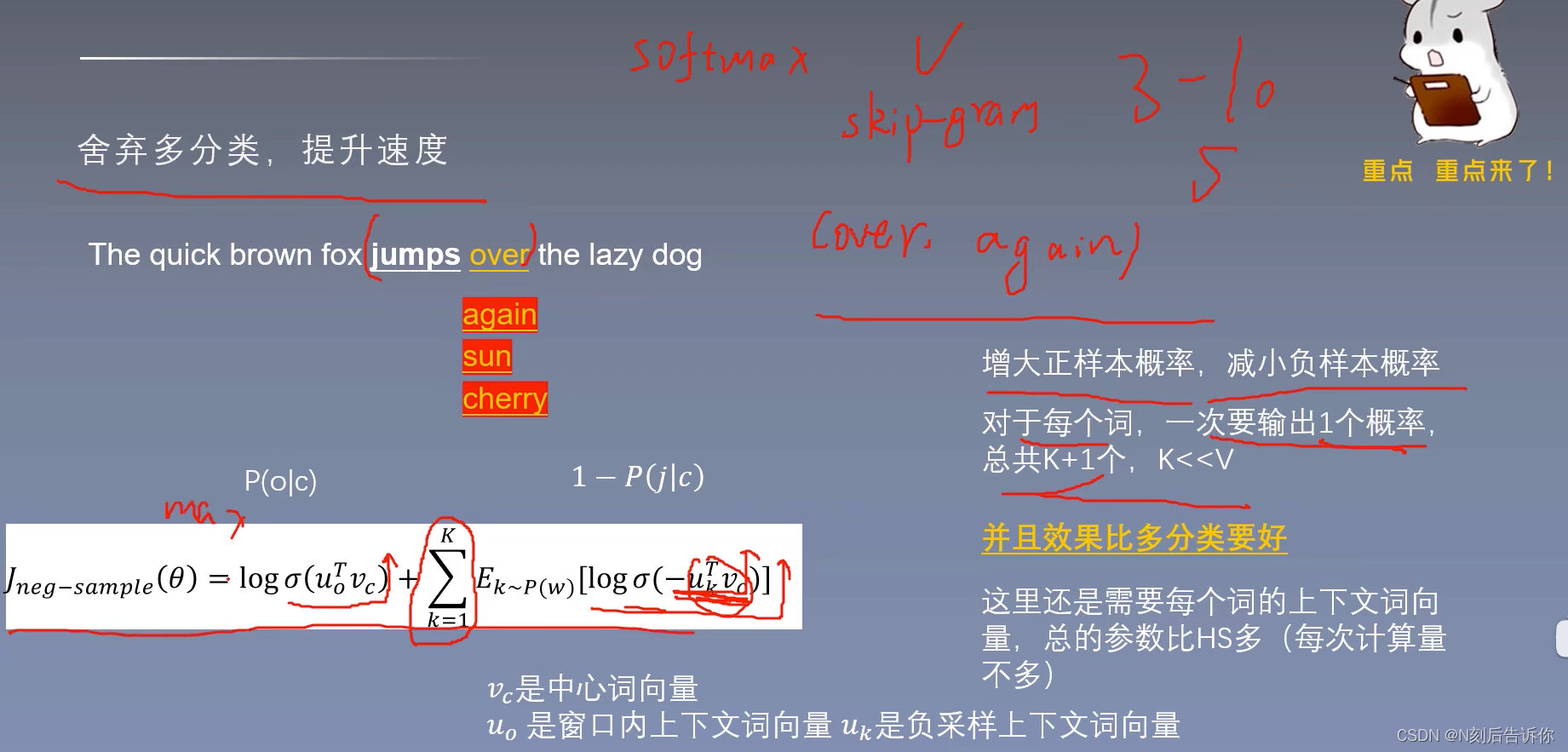
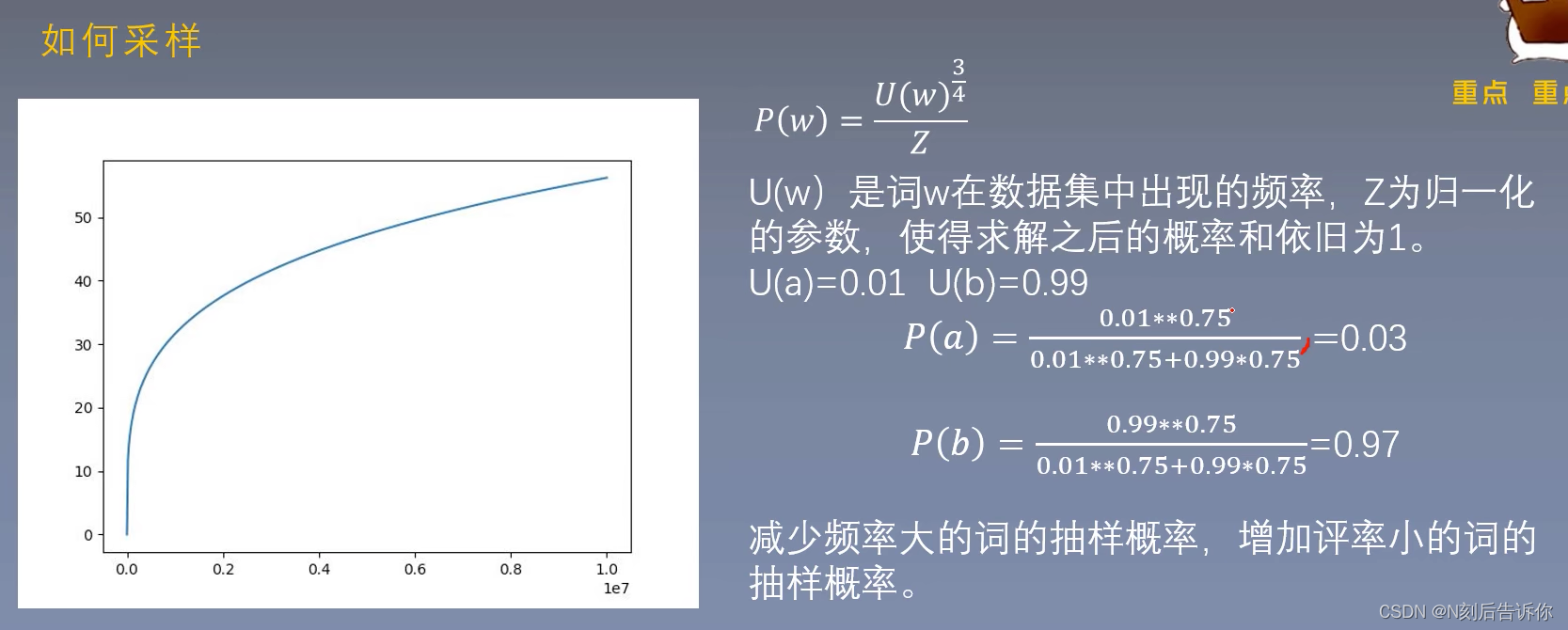
重要的词往往出现的频率比较小,不重要的词往往出现的频率比较高
CBOW负采样

重采样



模型复杂度

不同模型的E和T认为一样,所以下面用Q来代表模型复杂度。
NNLM
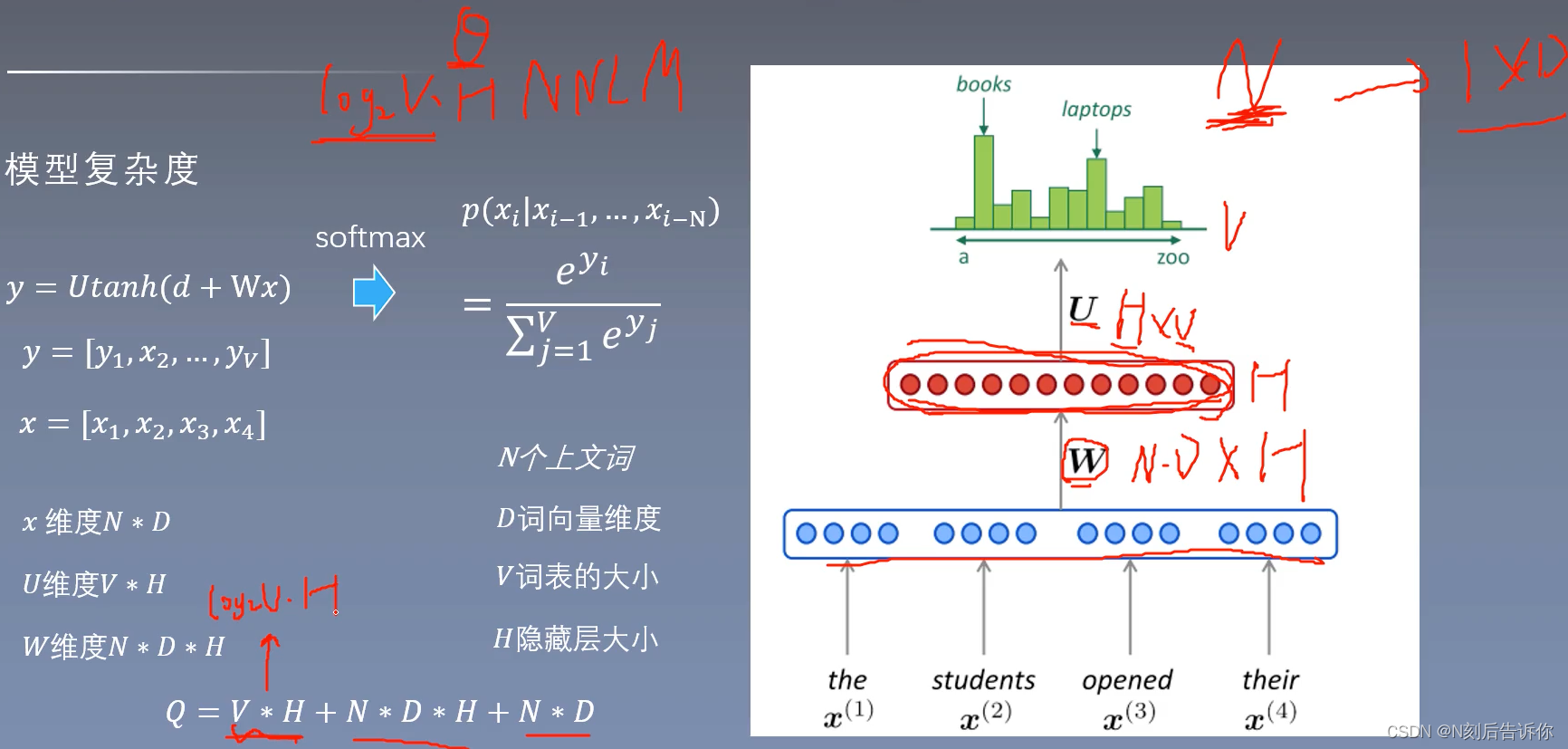
用层次softmax,V*H会变成 l o g 2 V ∗ H log_2V*H log2V∗H
RNNLM

Skip-gram
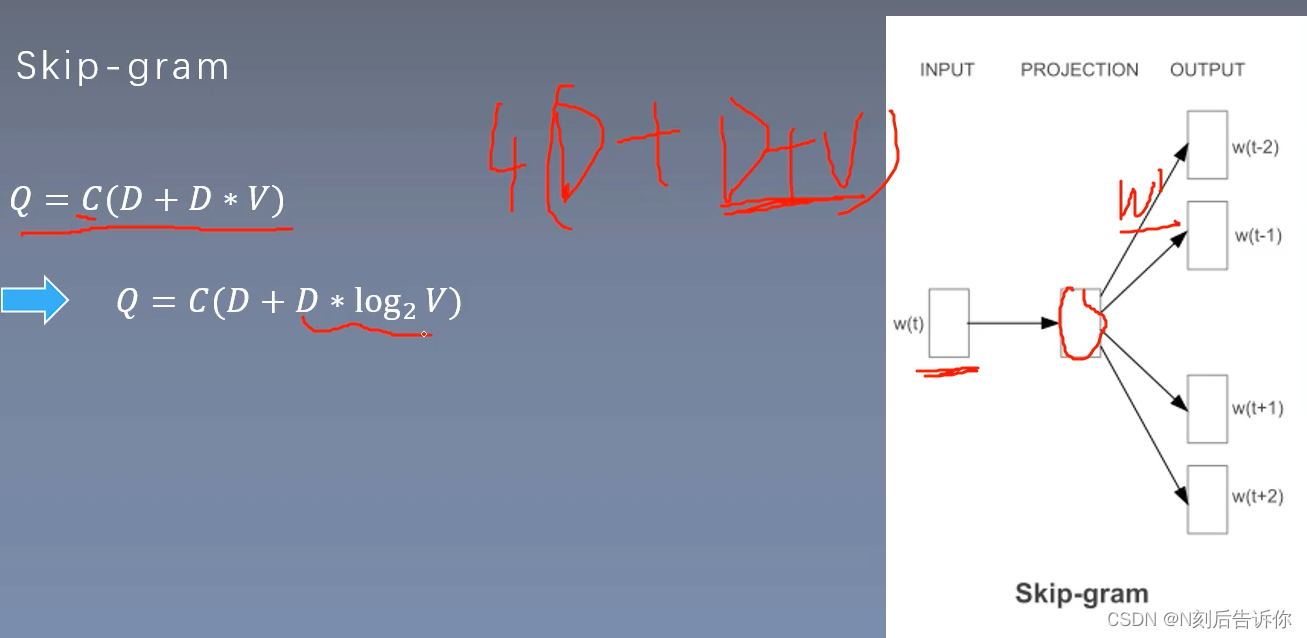
skip-gram负采样

CBOW
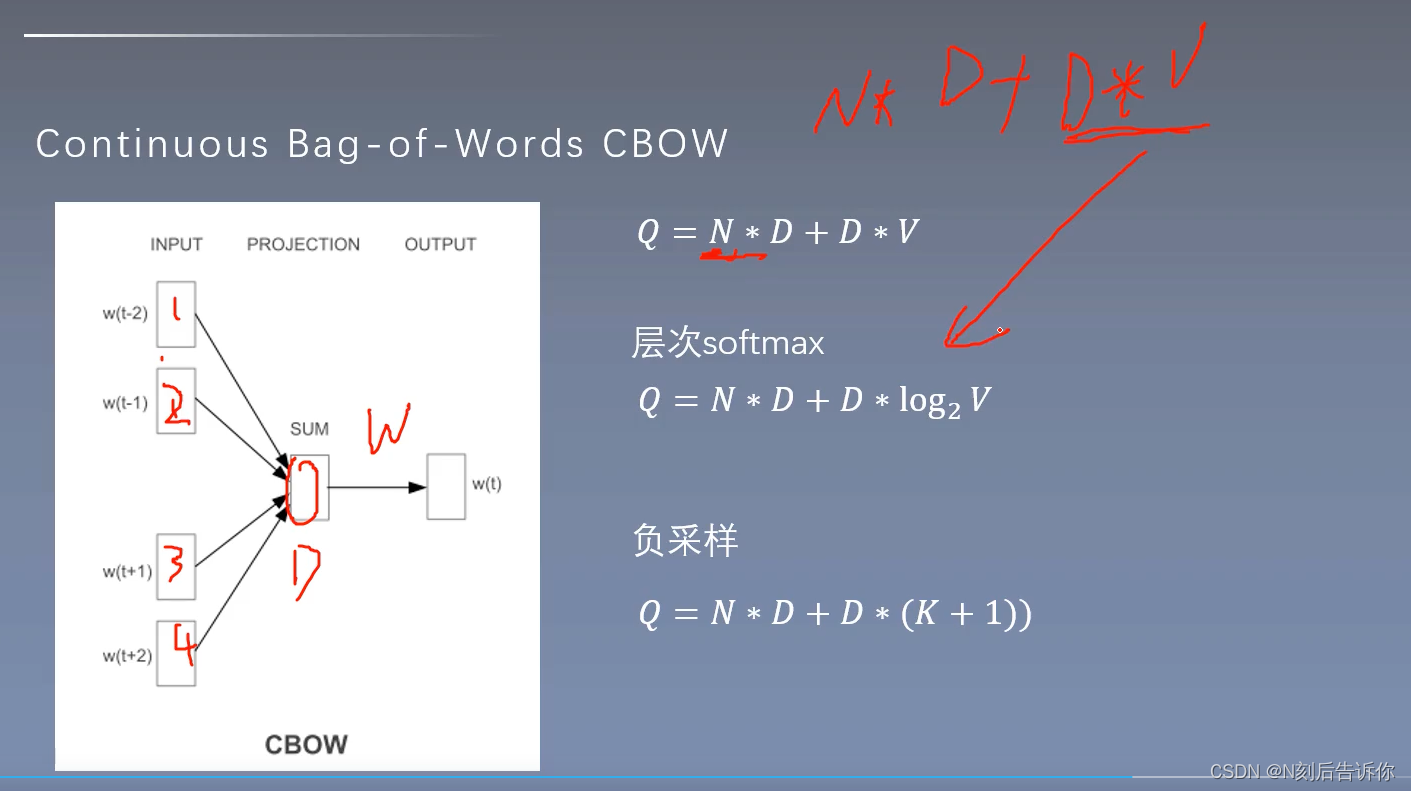 文章来源:https://uudwc.com/A/LaAg2
文章来源:https://uudwc.com/A/LaAg2
比较
 文章来源地址https://uudwc.com/A/LaAg2
文章来源地址https://uudwc.com/A/LaAg2
![[ubuntu]给WSL子系统ubuntu安一个桌面环境](https://img-blog.csdnimg.cn/2283b489693b439c9cb9cd60e03a1fc6.png)