?? 欢迎来到小林的博客!!
?️博客主页:✈️林 子
?️博客专栏:✈️ Linux
?️社区 :✈️ 进步学堂
?️欢迎关注:?点赞?收藏✍️留言
目录
- 线程与进程
- 重新认识进程
- 创建线程
- 线程中独立的资源
- 为什么线程切换的成本更低?
线程与进程
我们都知道,进程是操作系分配资源的基本实体。 每当操作系统创建一个新的进程时,都会为这个进程分配资源,例如 : 进程地址空间,页表…等。
那如何理解线程呢?
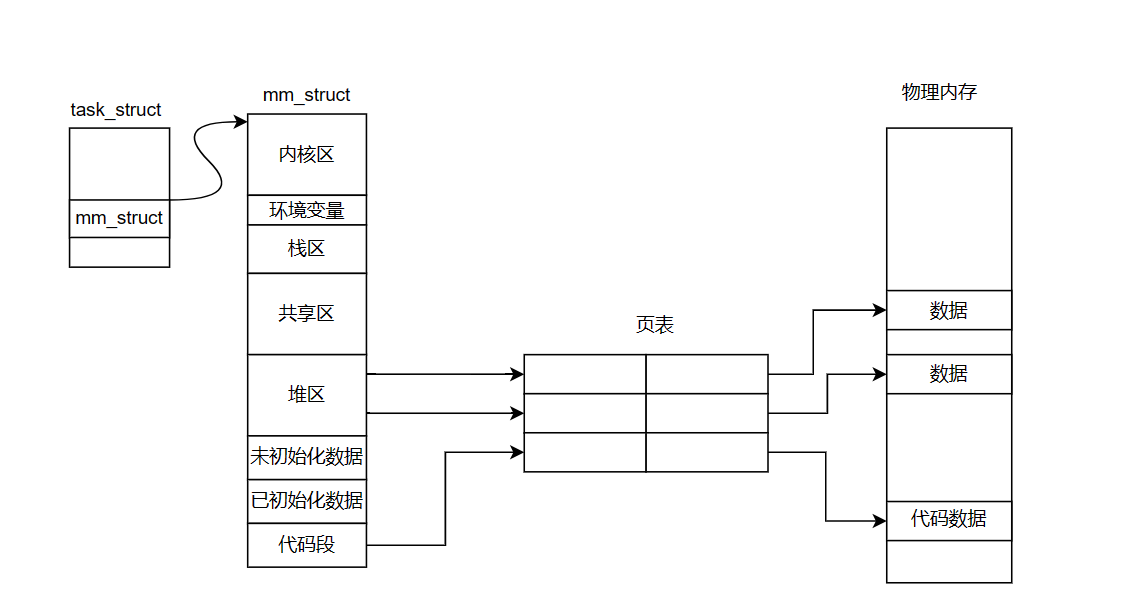
在Linux系统下,并没有真正意义上的线程。因为在Linux系统下,线程没有属于自己的数据结构。而windows操作系统是为线程设定了指定的数据结构。而在Linux系统下,线程复用了进程的PCB。也就是说,描述线程和进程的结构体都是task_struct。 而这些PCB都共享同一块进程地址空间,共享同一块页表…以及其他的资源。
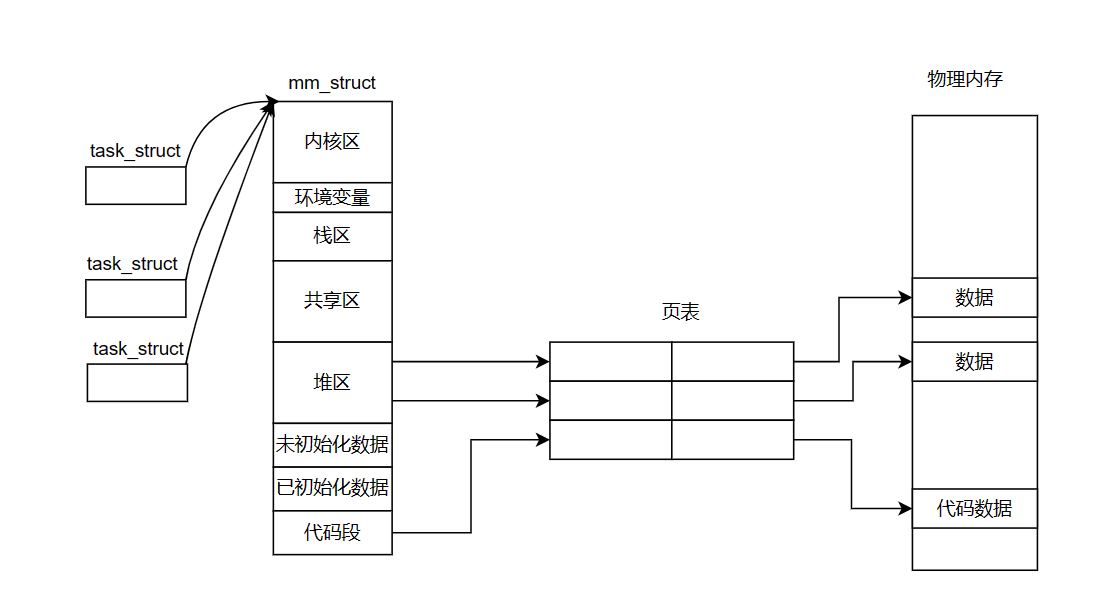
而这个时候,进程就不仅仅是一个PCB了,而是多个PCB + 当前进程的资源 = 进程。而每一个PCB都是一个执行流,无论是线程还是进程,CPU都不关心。因为CPU只负责调度PCB。而通过一定的技术手段,可以将进程的"资源"以一定的方式分配给不同的task_struct。
所以可以得出结论:
进程是承担操作系统分配资源的基本实体。
线程是在进程的内部执行。因为它们共享同一块进程地址空间以及其他资源。
线程是CPU调度的基本单元
重新认识进程
在之前的认知中,我们都认为一个进程就是一个PCB + 程序的代码和数据。 但是现在我们要重新认识进程了。当进程内部只有一个执行流的时候, 进程 = PCB + 程序的代码和数据。 当进程内部有多个执行流的时候 ,那么 进程 = 多个PCB + 程序的代码和数据。
在CPU的视角中,CPU其实根本不关心当前调用的是进程还是线程,因为它只认PCB,也就是task_struct。所以在linux系统下, PCB <= 其他OS内的PCB。因为当Linux下的进程包含多个执行流的时候,那么多个PCB其实共享了大部分资源,那么此时的PCB就会小于其他OS内的PCB。因为其他的OS,进程和线程都有属于各自的数据结构。
在Linux下,Linux是用进程来模拟线程的!
这也就意味着Linux并不能直接给我们提供线程相关的接口,只能提供轻量级进程接口!不过好在有一位Linux系统工程师在用户层实现了一套多线程方案,以库的方式提供给了用户进行使用,那就是 pthread线程库,也叫原生线程库。
创建线程
在初步了解线程之后,那么我们可以来创建一个线程,见见线程是什么样子的。
我们先认识一下创建线程的函数。
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
第一个参数为线程的tid
第二个参数为线程的属性
第三个参数是一个函数指针,为线程的执行函数
第四个参数为执行函数的参数
测试代码:
#include<iostream>
#include<pthread.h>
#include<unistd.h>
void* ThreadRun(void* name)
{
while(1)
{
std::cout << "this is " << (char*)name << ", pid = " << getpid() << std::endl;
sleep(1);
}
}
int main()
{
pthread_t tids[5];
char name[64];
for(int i = 0 ; i < 5 ; i++)
{
snprintf(name,sizeof name,"%s:%d","Thread ",i);
pthread_create(tids+i,nullptr,ThreadRun,(void*)name);
sleep(1);
}
while(1)
{
std::cout << "this is main thread , pid = " << getpid() << std::endl;
sleep(3);
}
}
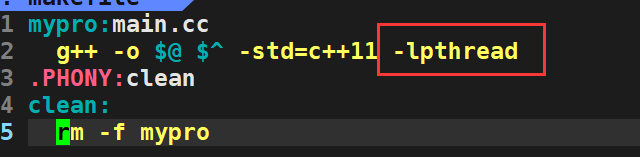
记得在编译的时候加上一个-lpthread选项,否则无法编译通过,因为 -lphtread原生线程库并不属于C/C++库。
然后运行后我们发现。5个线程+一个主线程,它们打印出来的进程pid都是一样的。
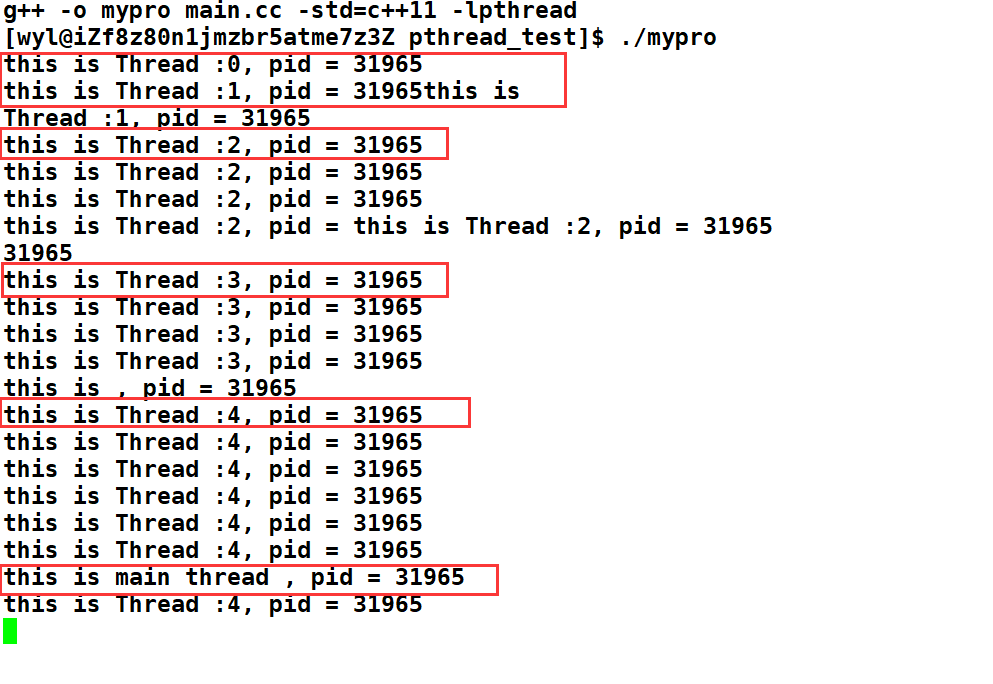
然后我们再用ps ajx | head -1 && ps ajx | grep “你的可执行程序名称” 来查看当前运行的进程

我们发现只有一个进程,这是因为线程是进程内部执行的!所以我们无法看到线程,如果想看线程,我们可以用ps -aL | head -1 && ps -aL | grep "要查看的进程名称" 即可查看当前进程下的线程。
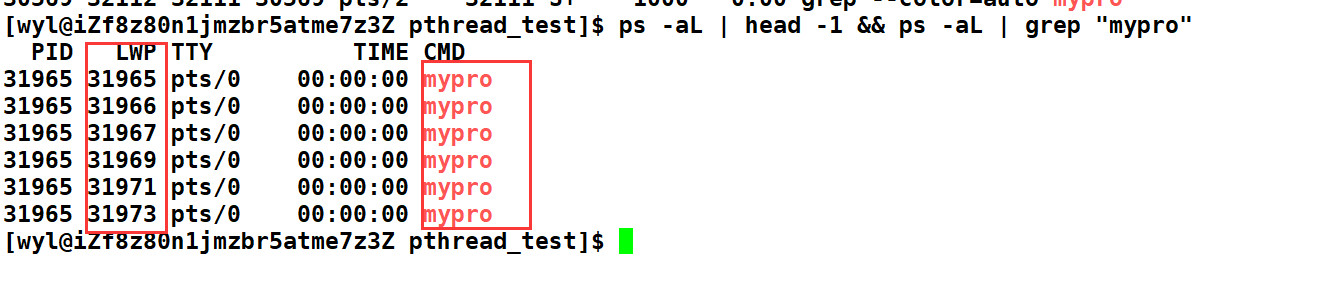
我们可以看到这个进程中有6个线程,一个主线程。剩下的5个创建的线程。 我们可以发现它们的PID都是一样的。但是LWP是不一样的! 所以,CPU调度看的是LWP还是PID 呢? 答案肯定是LWP,因为线程是CPU调度的基本单元。如果是根据PID进行调度,那么这么多线程的PID都一样,就会产生歧义。所以CPU调度实际是根据LWP字段调度的。
验证线程之间共享地址空间
很简单,我们只需要创建一个全集变量,并在主线程对该变量进行修改,然后让所有线程打印该变量。其他线程的值也发生了改变,那就说明线程之间共享了地址空间。
#include<iostream>
#include<pthread.h>
#include<unistd.h>
int x = 0;
void* ThreadRun(void* name)
{
while(1)
{
std::cout << "this is " << (char*)name << ", pid = " << getpid() << " x = " << x << std::endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,ThreadRun,(void*)"new thread");
while(1)
{
x++;
std::cout << "this is main thread , pid = " << getpid() <<" x = " << x << std::endl;
sleep(1);
}
}
运行结果:
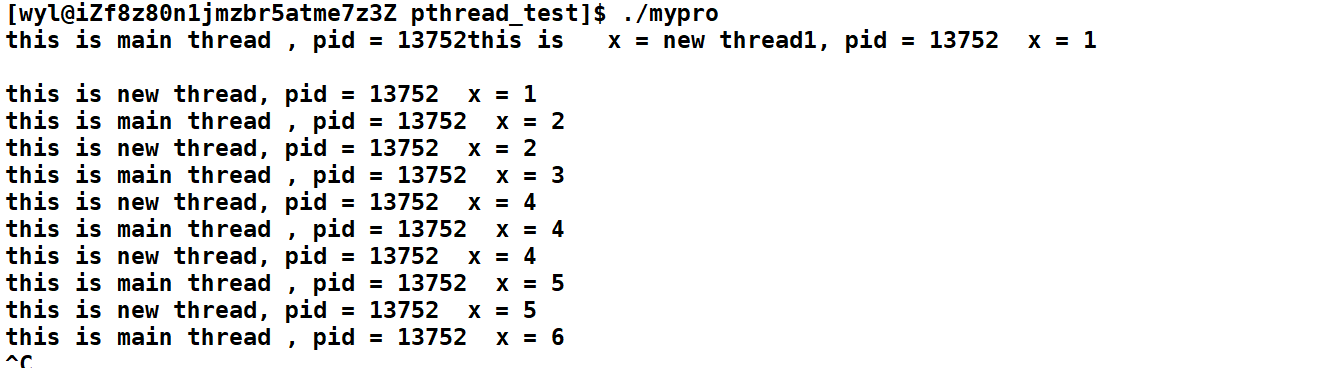
我们发现,全局变量x被所有线程所共享。
线程中独立的资源
线程共享进程数据,但也拥有自己的一部分数据,比如:
- 线程id
- 一组寄存器(相当于上下文)
- 栈(每个线程有独立的栈结构,让线程与线程之间独立)
- errno
- 信号屏蔽字
- 调度优先级
为什么线程切换的成本更低?
1.因为进程地址空间和页表不需要切换
但是地址空间和页表切换并没有太大的消耗。线程切换成本更低的本质原因是因为CPU内部有L1~L3 cache。文章来源:https://uudwc.com/A/LaWBJ
我们都知道,CPU处理指令是一条一条处理的。但如果每次CPU都去内存读一条指令,那么速度是非常非常慢的。所以CPU内部有个缓冲区。会先把内存中的指令放进CPU内部缓冲区。也就是预读代码,这样CPU就不用频繁的去内存中读取指令。而是直接在内部缓冲区里读,这样子速度是非常快的。而线程切换,cache不会失效。但如果是进程切换,那么cache就会立马失效,只能重新缓冲。所以这才是线程切换更快的本质原因,因为线程切换,CPU内部的缓冲区不用重新缓存。文章来源地址https://uudwc.com/A/LaWBJ