【Segment Anything Model】做分割的专栏链接,欢迎来学习。
【博主微信】cvxiaoyixiao
本专栏为公开数据集的介绍和预处理,持续更新中。
文章目录
- 1️⃣ ACDC数据集介绍
- 2️⃣ ACDC数据集样例
- 3️⃣ 预处理ACDC目标
- 4️⃣ 处理结果样图
- 5️⃣ 代码
- 6️⃣ 划分测试集和训练集
1️⃣ ACDC数据集介绍
他是一个
多类别的心脏3D MRI影像数据集`,2017年ACDC挑战赛(Automated Cardiac Diagnosis
Challenge)。
原数据集获取,网盘永久有效:
链接:https://pan.baidu.com/s/1F4Xq1crtUSmFcSKxwO4Eaw?pwd=ejfa 提取码:ejfa
–来自百度网盘超级会员V6的分享
2️⃣ ACDC数据集样例
首先夸夸? ,ACDC数据集存放格式非常规律? ,数据质量非常高? 清晰了分为3类别。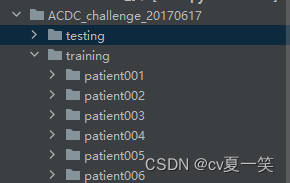
training里有100例患者,testing里有50例患者。每个nii的切片个数不同根据勾画的肿瘤。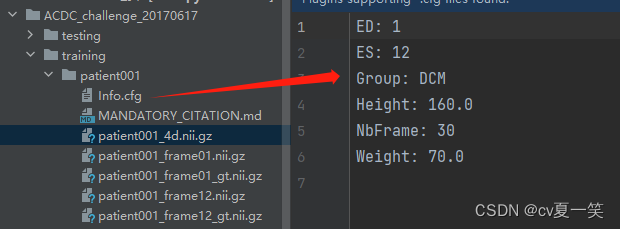
Info是媒体信息patient001_4d.nii.gz是全部的切片,我也不知道从医学上怎么描述,就是这个患者的立体影像,包括没有肿瘤的部分patient001_frame01.nii.gz是一个时期nii影响的压缩包patient001_frame01_gt.nii.gz对应patient001_frame01.nii.gz的肿瘤勾画的label的压缩包。用四种像素对应了四个类别包括背景。patient001_frame12.nii.gz是统一患者另一时期的影像patient001_frame12_gt.nii.gz是对应的label总之每个患者都有一个整体影像,还有两个不同成像和对应label。以下是打开之后的影像图。
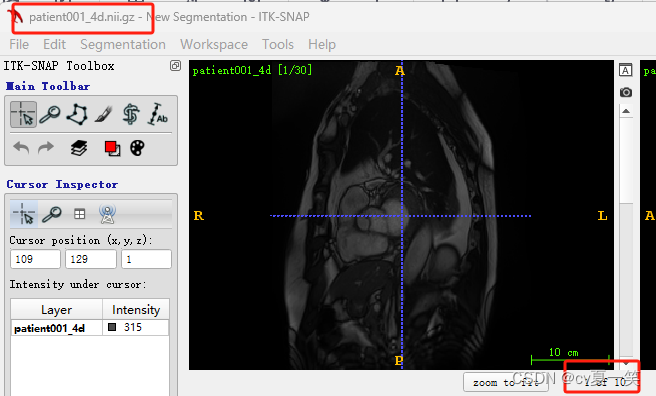
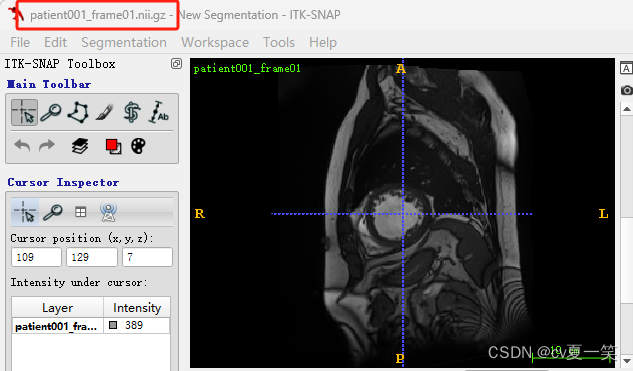
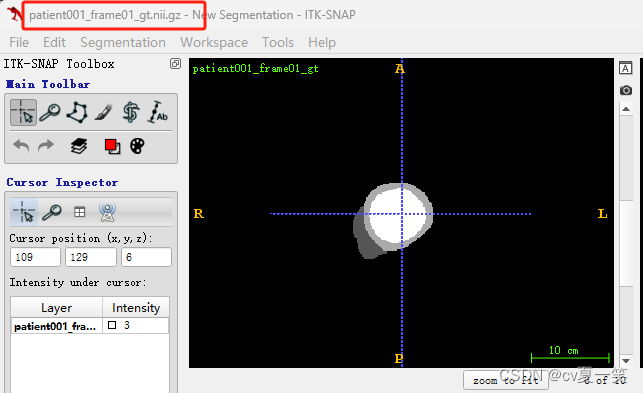
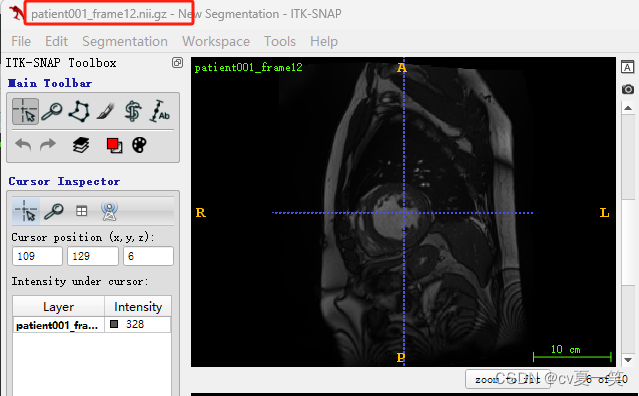
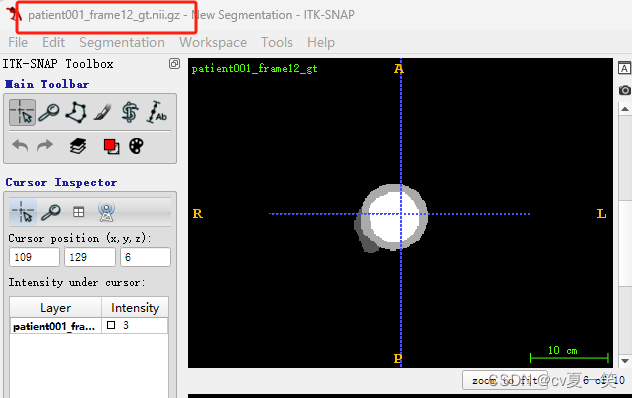
3️⃣ 预处理ACDC目标
目标:处理ACDC的nii.gz数据集到VOC格式的2d的png图片
VOC格式 这篇文章有讲直达
例如:将patient001_frame01.nii.gz处理成几张png作为网络image的输入。将patient001_frame01_gt.nii.gz处理成几张png作为label。只处理了training的100例患者,把training当成了整个集合划分了训练测试。并且只关心了frame01第一阶段,第二个阶段的未关心。只关心了留下的部分。够了。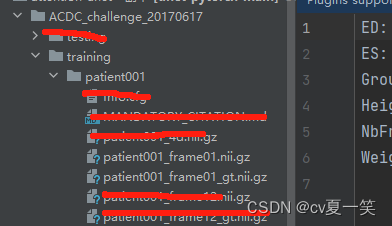
4️⃣ 处理结果样图
处理结果样图:
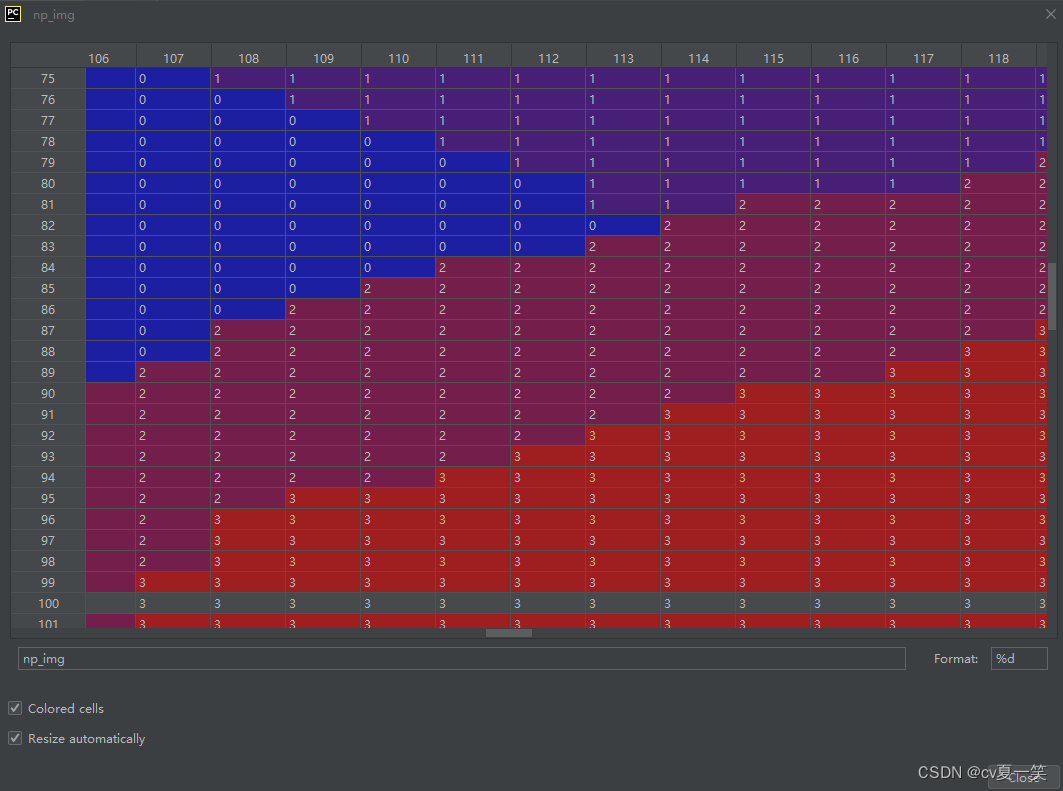
img转为jpg label转为png 并且像素为0-3. 0代表背景,1-3代表分类。label图像素太小,这里看不出来,可以看第三张数组图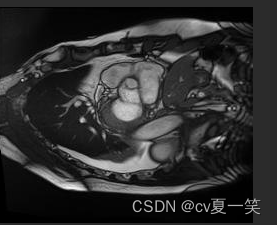

5️⃣ 代码
事先准备好VOC文件夹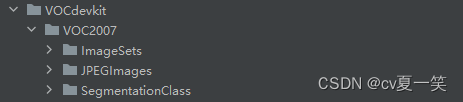 文章来源:https://uudwc.com/A/Lak3z
文章来源:https://uudwc.com/A/Lak3z
"""
处理官网下载的ACDC到网络要求的VOC格式,按需调用
author: cvxiayixiao
Wechat: cvxiayixiao
"""
import os
from os.path import join
import nibabel as nib
import gzip
import shutil
import matplotlib.pyplot as plt
import numpy as np
ori_ACDC_train_path = './ACDC_challenge_20170617/training'
def niigz2nii():
"""
解压每个患者的01阶段的nii.gz 和 gt.nii.gz 到输入文件夹"ACDC_nii"
"""
input_path = ori_ACDC_train_path
# 处理image
# target='frame01.nii'
# output_path = 'ACDC_nii/images'
# 处理gt
target = 'frame01_gt.nii'
output_path = 'ACDC_nii/labels'
for patient in os.listdir(input_path):
# ACDC_challenge_20170617/training/patient001
patient_path = join(input_path, patient)
for niigz in os.listdir(patient_path):
if target in niigz:
niigzpath = join(patient_path, niigz)
new_nii_path = join(output_path, niigz)
shutil.copy(niigzpath, new_nii_path)
# niigz2nii()
def convert_nii_to_jpg():
'''
将ACDC_nii/images中的nii转到VOCjpg中
:return:
'''
image_num = 0
nii_path = "./ACDC_nii/images"
output_dir = "./VOCdevkit/VOC2007/JPEGImages"
for patient in os.listdir(nii_path):
patient_path = join(nii_path, patient)
for one in os.listdir(patient_path):
one_patient_nii_path = join(patient_path, one)
# 加载 .nii 文件
nii_img = nib.load(one_patient_nii_path)
data = nii_img.get_fdata()
# 遍历数据的每个切片,并保存为 .png 文件
for i in range(data.shape[2]):
image_num += 1
# 获取当前切片数据
slice_data = data[:, :, i]
# 创建输出文件路径
num = f"{image_num}".zfill(6)
output_path = os.path.join(output_dir, f'{patient}_{num}.jpg')
# 以灰度图像格式保存切片数据为 .png 文件
plt.imsave(output_path, slice_data, cmap='gray')
# convert_nii_to_jpg()
def convert_nii_to_png():
'''
将ACDC_nii/labels中的nii转到ACDC_nii/tmp_png_label中
此时的像素是原label 中的像素,不是网络中的分类像素,还需要一部转换
:return:
'''
image_num = 0
nii_path = "./ACDC_nii/labels"
output_dir = "./tmp"
for patient in os.listdir(nii_path):
patient_path = join(nii_path, patient)
for one in os.listdir(patient_path):
one_patient_nii_path = join(patient_path, one)
# 加载 .nii 文件
nii_img = nib.load(one_patient_nii_path)
data = nii_img.get_fdata()
# 遍历数据的每个切片,并保存为 .png 文件
for i in range(data.shape[2]):
image_num += 1
# 获取当前切片数据
slice_data = data[:, :, i]
# 创建输出文件路径
num = f"{image_num}".zfill(6)
output_path = os.path.join(output_dir, f'{patient}_{num}.png')
# 以灰度图像格式保存切片数据为 .png 文件
plt.imsave(output_path, slice_data, cmap='gray')
from PIL import Image
def turnto255():
from PIL import Image
from PIL import Image
for i in os.listdir("tmp"):
output_path = os.path.join("./tmp1", i)
png_path = join("tmp", i)
# 读取图像
image = plt.imread(png_path)
# 取三个通道的平均值
im_gray = np.mean(image, axis=2)
im_gray = Image.fromarray((im_gray * 255).astype(np.uint8)).convert("L")
# 保存输出图像
im_gray.save(output_path)
def rename():
"""
处理好的VOC2007 train和test名称不同,名称不对应不能训练
转为对应的,之前的留作副本可以对应原图
:return:
"""
root = "VOCdevkit/VOC2007/SegmentationClass"
for i in os.listdir(root):
img_old_path = join(root, i)
new_png_path = join(root, i[-10:])
shutil.copy(img_old_path, new_png_path)
# rename()
将0-255转为0-3类代码,加微信cvxiayixiao
6️⃣ 划分测试集和训练集
import os
import random
import numpy as np
from PIL import Image
from tqdm import tqdm
# 修改train_percent用于改变验证集的比例 9:1
trainval_percent = 1
train_percent = 0.9
VOCdevkit_path = 'VOCdevkit'
if __name__ == "__main__":
random.seed(0)
print("Generate txt in ImageSets.")
segfilepath = os.path.join(VOCdevkit_path, 'VOC2007/SegmentationClass')
saveBasePath = os.path.join(VOCdevkit_path, 'VOC2007/ImageSets/Segmentation')
temp_seg = os.listdir(segfilepath)
total_seg = []
for seg in temp_seg:
if seg.endswith(".png"):
total_seg.append(seg)
num = len(total_seg)
list = range(num)
tv = int(num*trainval_percent)
tr = int(tv*train_percent)
trainval= random.sample(list,tv)
train = random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'val.txt'), 'w')
for i in list:
name = total_seg[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
成功划分 文章来源地址https://uudwc.com/A/Lak3z
文章来源地址https://uudwc.com/A/Lak3z

