加密恶意流量检测
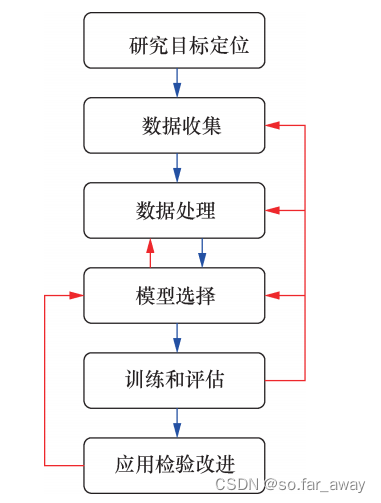
- 研究目标定位
- 数据收集
- 数据处理
- 基于特征分类算法的数据预处理
- 基于源数据分类算法的数据预处理
- 特征提取
- 模型选择
- 基于数据特征的深度学习检测算法
- 基于特征自学习的深度学习检测算法
- 训练和评估
- 精确性指标
- 实时性指标
- 应用检验改进
摘录自:Mingfang ZHAI,Xingming ZHANG,Bo ZHAO. Survey of encrypted malicious traffic detection based on deep learning[J]. Chinese Journal of Network and Information Security, 2020, 6(3): 66-77.
网络信息安全学报:Survey of encrypted malicious traffic detection based on deep learning
本文归纳总结“六步法”的加密恶意流量检测一般框架模型,为问题研究提供帮助。
“六步法”框架是针对加密恶意流量检测问题的,但对于普通的流量识别问题仍然适用(普适性)。
加密恶意流量检测的本质是学习数据特征,将流量数据进行正确分类。
如下是“六步法”的模型构造
研究目标定位
流量通常由5元组决定:源IP、目标IP、源端口、目标端口和协议。
可按以下方面对流量进行分类:
1)协议,如SSH、SSL/TLS
2)应用,如微信、滴滴出行、百度地图
3)服务,如聊天。购物
4)网站,如谷歌、百度
5)用户行为,如浏览、下载、上传
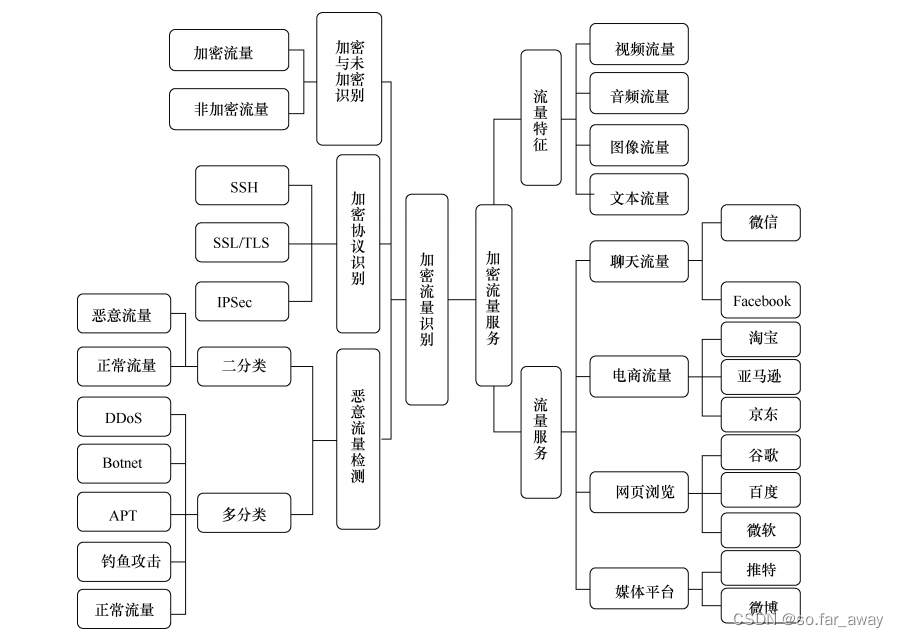
具体就加密流量而言,通常分为加密与未加密识别、加密协议识别、加密服务识别和恶意流量检测。
- 加密与未加密识别主要将流量区分为加密流量和非加密流量。
- 加密协议识别是根据协议的不同对加密流量进行归类。
- 加密服务识别是将流量按特征、服务类别或者应用程序进行分类。
- 异常流量检测的目的在于检测出隐藏在加密流量之中的DDoS、APT、Botnet等恶意流量,是保障网络安全的重要手段。
与加密协议识别和加密服务识别相比,异常流量检测的难点有:
①攻击者常常利用协议规则将攻击流量伪装成正常流量,增加检测的难度。
②数据集严重不平衡,攻击流量远远小于正常流量,可能会产生训练不充分的问题,从而影响检测精度。
③检测错误代价大,因此对检测精度要求更高。
下图是加密流量识别分类结构
数据收集
直接收集法:常用的数据采集软件有Wireshark、Sniffer、Fiddler等。
脚本收集法:拟合大多现有的攻击模式。
混合方法:直接收集法+脚本收集法。
数据处理
数据预处理是指将未加工数据转换为适合分析的形式,包括多数据源的数据融合、数据清洗、维规约等。
基于特征分类算法的数据预处理
该方法需要将原始数据处理为打上各种特征标签的数据,如统计标签、时间序列等,而后送入算法模型检测恶意流量与正常流量。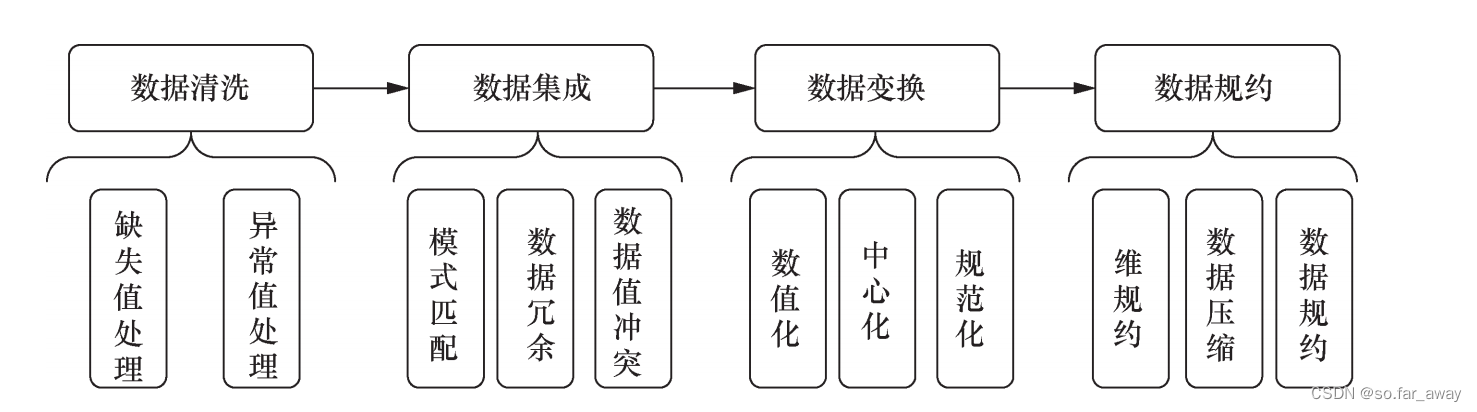
数据清洗:数据清洗是指对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误。对数据中存在的无效值或错误值常采用删除的方法,包括整列删除、变量删除和成对删除等方法。对缺失值处理有均值插补、同类均值插补及高维映射等方法。
数据集成:数据集成是将多个数据源收集的数据整合在一起,主要的困难在于多个数据源异构的问题,即几个数据源并不完全一致,收集的数据格式、长度等不同,相互之间存在冗余和不兼容等问题。
数据变换:数据变换即对数据进行规范化处理,以便于后续的信息挖掘,主要包括数值化、中心化和规范化等内容。数值化就是将非数据信息转化为数据,如网络协议信息,可用简单数值表示。中心化是指将数据减去均值或者某个指定数值的操作。规范化目的在于把数据整合到[0,1]内以方便实验,常用最大值规范化方法。
数据归约:数据规约指在保持数据原貌的前提下,最大限度地精简数据量。通常采取特征选择和数据采样的方法实现。
基于源数据分类算法的数据预处理
使用深度学习方法自动学习数据中所隐藏的特征,从而实现对加密恶意流量的检测。这类算法无须对数据进行特征提取操作。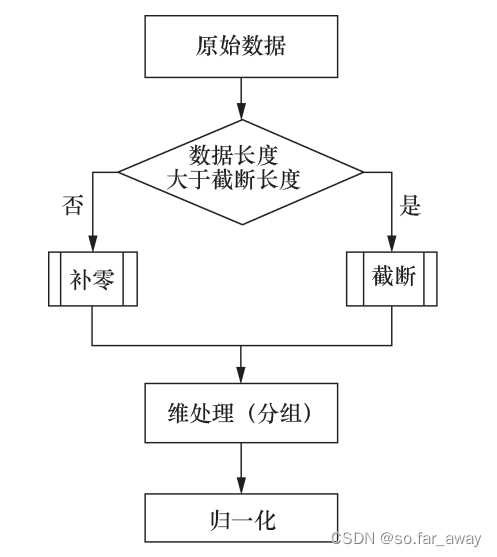
特征提取
在加密协议握手阶段,客户端与服务器往往需要通过明文协商相关加密参数,这一阶段可以得到许多与加密相关的宝贵数据,如加密采用的TLS版本、算法、证书、TLS扩展选项等。除此之外,数据包长度、流长度、报文的持续时间以及时间间隔等信息,都可以有效提升加密恶意流量检测的精度。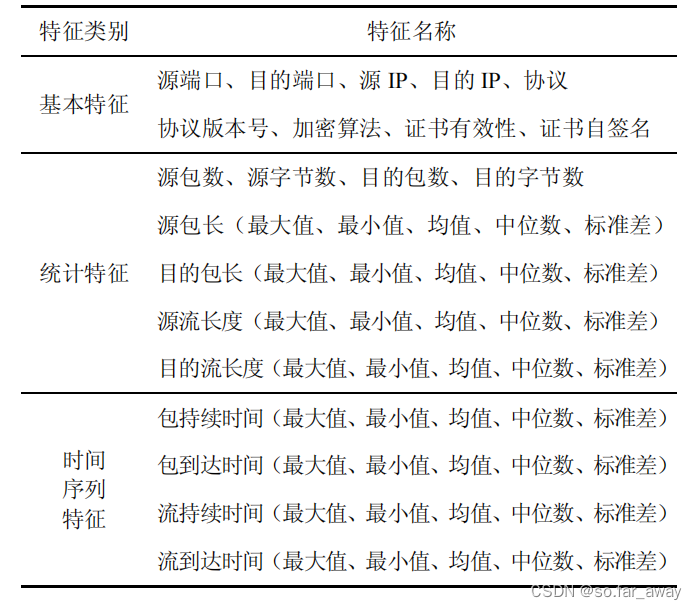
并不是特征越多越好,过量的特征选择反而可能导致检测性能的下降。另外,复杂的识别特征需要耗费大量的存储空间和计算能力,给硬件系统带来压力。
模型选择
基于深度学习的检测方法具有检测加密流量的天然优势。
检测模型主要分为两大类:一类是利用特征标签检测加密恶意流量;另一类是充分利用CNN、RNN等深度学习的特征学习能力,自动学习数据中隐含的特征进行恶意流量检测。
基于数据特征的深度学习检测算法
此类方法需要首先提取数据特征,然后将有特征标签类的数据输入深度学习算法进行训练检测。
基于特征自学习的深度学习检测算法
该类算法不需要提取数据特征,只对数据进行切片操作,而后由算法自动挖掘特征进行检测。
基于特征自学习的深度学习检测算法最大的特点是不需要再提取数据特征,对于数据集的要求低、依赖性小,可移植性好,使用更加灵活。
但这类方法也有着天然的不足:
①数据切片取多少字节合适并没有依据,只是凭经验取舍。
②切片数据长度不能太长,切片过长可能影响计算性能,进而影响训练的效率。
③训练过程可解释性相对较低,训练比较困难,容易引起检测性能不稳定。
训练和评估
模型构建后,即需要对模型进行训练和评估。
训练通常采用N折交叉验证,一般为10折。
评价指标有精确性指标和实时性指标。
精确性指标
精确性指标基于混淆矩阵生成,主要用来评估模型的检测能力和检测精度,包括准确率、召回率、精确度、误报率、F分数等。
混淆矩阵用于描述加密恶意流量检测中实际类别和预测类别之间的相互关系。
其中:
- TP(真正例)表示检测模型将攻击类型正确识别为攻击类型的样本个数;
- TN(真负例)表示检测模型将正常类型正确识别为正常类型的样本个数;
- FP(假正例)表示检测模型将正常类型错误识别为攻击类型的样本个数;
- FN(假负例)表示检测模型将攻击类型错误识别为正常类型的样本个数;
| 预测 | 攻击 | 正常 |
|---|---|---|
| 攻击 | TP | FN |
| 正常 | FP | TN |
基于上述定义,给出各种精度性能指标的公式化定义。
准确率
=
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
准确率=\frac{TP+TN}{TP+TN+FP+FN}
准确率=TP+TN+FP+FNTP+TN
召回率
=
T
P
T
P
+
F
N
召回率=\frac{TP}{TP+FN}
召回率=TP+FNTP
精确度
=
T
P
T
P
+
F
P
精确度=\frac{TP}{TP+FP}
精确度=TP+FPTP
误报率
=
F
P
F
P
+
T
N
误报率=\frac{FP}{FP+TN}
误报率=FP+TNFP
召回率、精确度和误报率体现了检测方法在每个攻击类别上的检测效果,特别是当数据不平衡时,这3个指标能够准确获知各类攻击的检测情况。
由于一般情况下召回率和精确率之间存在博弈,即召回率高,精确度就低;反之精确度高,召回率就低。于是引入F分数指标,F分数是综合考虑召回率和精确率的精确性评价指标。当β=1时,精确率和召回率同等重要,权重相同,此时F分数又被称为F1分数或F衡量。
F分数值越高表明算法的分类性能越好。
F
分数
=
(
1
+
β
2
)
P
r
e
c
i
s
i
o
n
×
R
e
c
a
l
l
β
2
P
r
e
c
i
s
i
o
n
+
R
e
c
a
l
l
F分数=(1+\beta^2)\frac{Precision×Recall}{\beta^2Precision+Recall}
F分数=(1+β2)β2Precision+RecallPrecision×Recall
上述精确性指标基于流或基于包,字节精度对评估流量分类算法的准确性至关重要。但是,字节精度可能耗费计算资源,提升计算复杂度。
实时性指标
实时性指标用于评估模型的检测效率,反映加密恶意检测可以在线、快速地识别加密恶意流量的能力,保证在实施恶意流量检测的过程中不影响核心网络性能。实时性主要体现在对流的前N个包的精确检测上。文章来源:https://uudwc.com/A/MxNR5
应用检验改进
关于“六步法”的最后一步应用检验改进,是指将构建的模型应用到实际网络中,进行实网加密恶意流量检测,通过网络运行,检验算法模型的实效性和健壮性,并定期对模型进行更新,不断完善模型以取得更高的检测精度和效能。文章来源地址https://uudwc.com/A/MxNR5