现有一链表的头指针 ListNode* pHead,给一定值x,编写一段代码将所有小于x的结点排在其余结点之前,且不能改变原来的数据顺序,返回重新排列后的链表的头指针。
思路,把链表分成两个新链表,然后连接起来
代码:文章来源:https://uudwc.com/A/MxRE3
class Partition {
public:
ListNode* partition(ListNode* pHead, int x) {
// write code here
if(pHead==NULL)
{
return pHead;
}
ListNode* ghead=NULL;
ListNode* gtail=NULL;
ListNode* lhead=NULL;
ListNode* ltail=NULL;
ListNode* cur=pHead;
while(cur)
{
if(cur->val<x)
{
if(ltail==NULL)
{
lhead=ltail=cur;
}else
{
ltail->next=cur;
ltail=ltail->next;
}
cur=cur->next;
}else
{
if(gtail==NULL)
{
ghead=gtail=cur;
} else{
gtail->next=cur;
gtail=gtail->next;
}
cur=cur->next;
}
}
if(gtail)//储存大的那个那个链表如果不是空,那么就要把最后一个节点的next置空
{
gtail->next=NULL;
}
else//如果gtail是空的话,那么就全都是小的数在lhead里,直接返回那么链表就行
{
return pHead;
}
if(lhead)
{
ltail->next=ghead;
return lhead;
}else {
return lhead;
}
}
};
判断头的代码过于繁琐,那么就利用链表的标兵: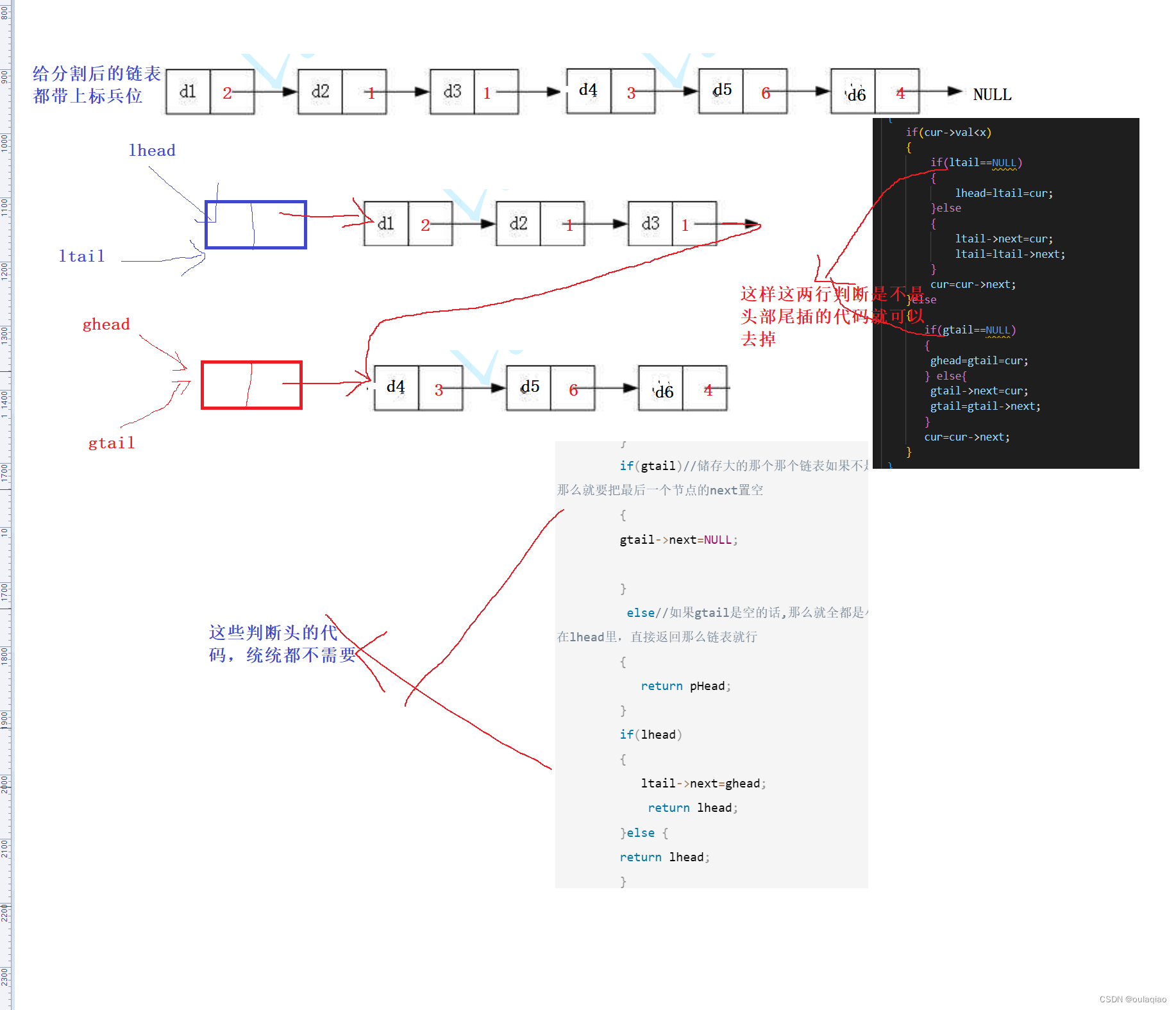
代码:文章来源地址https://uudwc.com/A/MxRE3
class Partition {
public:
ListNode* partition(ListNode* pHead, int x) {
// write code here
if(pHead==NULL)
{
return pHead;
}
ListNode* ghead=NULL;
ListNode* gtail=NULL;
ghead=gtail=(struct ListNode*)malloc(sizeof(struct ListNode));
ListNode* lhead=NULL;
ListNode* ltail=NULL;
lhead=ltail=(struct ListNode*)malloc(sizeof(struct ListNode));
ListNode* cur=pHead;
while(cur)
{
if(cur->val<x)
{
ltail->next=cur;
ltail=ltail->next;
}else
{
gtail->next=cur;
gtail=gtail->next;
}
cur=cur->next;
}
gtail->next=NULL;
ltail->next=ghead->next;
struct ListNode* per=lhead->next;
free(lhead);
free(ghead);
return per;
}
};