一、Python爬虫基础知识介绍
1.1 Python相关库
1、requests、re
2、BeautifulSoup
3、hackhttp
1.2 Python BeautifulSoup
Python BeautifulSoup模块的使用介绍∶
1、解析内容
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc)
2、浏览数据
soup.title
soup.title.string
3、BeautifulSoup正则使用
soup.find_all(name= ‘x’,attrs={‘xx’:re.compile(‘xxx’)})
二、Python爬虫简单实现
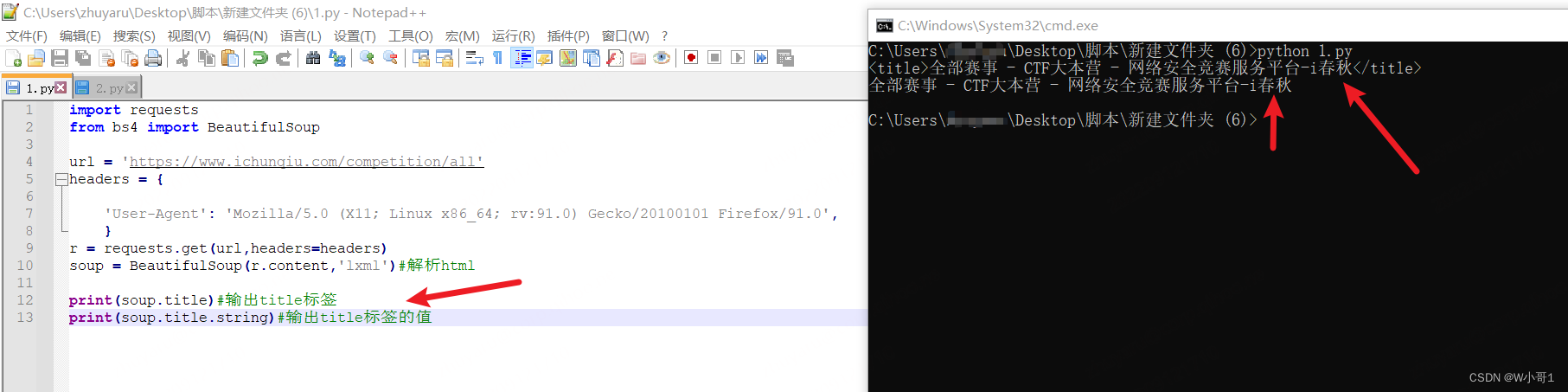
示例一:文章来源:https://uudwc.com/A/Mxq3w
import requests
from bs4 import BeautifulSoup
url = 'https://www.ichunqiu.com/competition/all'
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0',
}
r = requests.get(url,headers=headers)
soup = BeautifulSoup(r.content,'lxml')#解析html
print(soup.title)#输出title标签
print(soup.title.string)#输出title标签的值
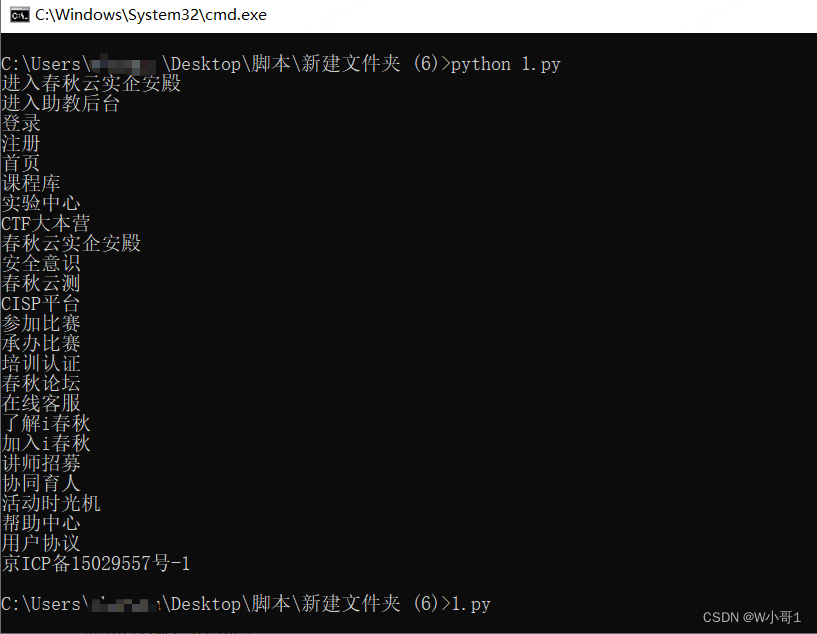
示例二:
import requests
from bs4 import BeautifulSoup
url = 'https://www.ichunqiu.com/competition/all'
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0',
}
r = requests.get(url,headers=headers)
soup = BeautifulSoup(r.content,'lxml')#解析html
#print(soup.title)#输出title标签
#print(soup.title.string)#输出title标签的值
com_nes = soup.find_all(name='a')#name=标签值,attrs=标签内的内容(可以不),示例:com_nes = soup.find_all(name='a',attrs={'class':'ui_colorG'}),
for coms in com_nes:
if coms.string != None:
print(coms.string)
示例三:
import requests
from bs4 import BeautifulSoup
import re
url = 'https://www.ichunqiu.com/competition/all'
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0',
}
r = requests.get(url,headers=headers)
soup = BeautifulSoup(r.content,'lxml')#解析html
#print(soup.title)#输出title标签
#print(soup.title.string)#输出title标签的值
com_nes = soup.find_all(name='a',attrs={'href':re.compile('ichunqiu')})#获取标签a中超链接含有ichunqiu的所有链接
for coms in com_nes:
print(coms)
万金油的使用方法BeautifulSoup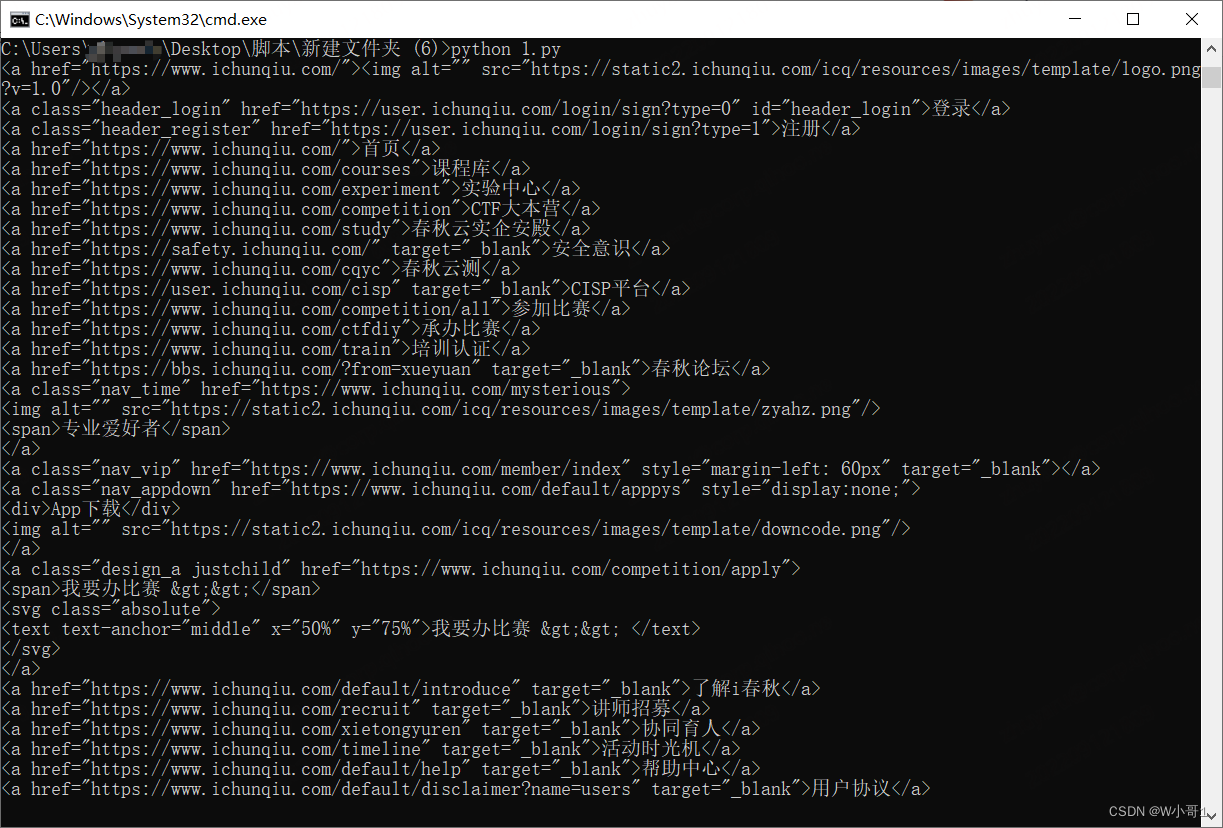
三、Python爬虫基础知识介绍
3.1 Python hackhttp
Python hackhttp模块的使用介绍∶
安装: pip install hackhttp
import hackhttp
hh = hackhttp.hackhttp()
url = “http://www.baidu.com”
code, head, html, redirect_url, log = hh.http(url)
发起get、post请求,发起http原始数据包
hackhttp介绍补充链接:
http://www.voidcc.com/project/hack-requests
示例一:
import HackRequests
from bs4 import BeautifulSoup
import re
url = 'https://www.cnvd.org.cn/'
hack = HackRequests.hackRequests()
url = "http://www.hacking8.com"
hh = hack.http(url)
print(hh.status_code)#
print(hh.content())
 文章来源地址https://uudwc.com/A/Mxq3w
文章来源地址https://uudwc.com/A/Mxq3w