在阅读本文之前,建议阅读文章:《GPT,GPT-2,GPT-3,InstructGPT的进化之路》
本文将介绍以下 LLM
- OPT
- LLaMa
- Alpaca
- Vicuna
- Moss
- chatGLM
- Baichuan
- Openbuddy
一、OPT
1、背景
OPT全称Open Pre-trained Transformer Language Models,即“开放的预训练Transformer语言模型”,是 Meta AI 团队在2022年5月发布了开源大模型OPT-175B,媲美 GPT-3,但是只需要 1/7 carbon footprint 的训练代价。
(Carbon Footprint:根据之前的研究和GPU设备的功耗估计以及碳效率,我们旨在计算模型训练所产生的碳排放量。实际GPU的功耗取决于其利用率,可能与我们作为GPU功耗估计所使用的热设计功耗(TDP)有所不同。需要注意的是,我们的计算不考虑互连或非GPU服务器功耗等进一步的功耗需求,也不考虑数据中心冷却系统的功耗。)
2、模型介绍
1)、开源资源
OPT模型论文地址:OPT: Open Pre-trained Transformer Language Models
Github仓库地址:https://github.com/facebookresearch/metaseq
代码链接:https://github.com/huggingface/transformers/blob/v4.19.0/src/transformers/models/opt/modeling_opt.py
175B模型申请访问权限地址:https://forms.gle/dag8g7nKiR4o4VZq5
OPT 训练日志:https://github.com/facebookresearch/metaseq/blob/main/projects/OPT/chronicles/OPT175B_Logbook.pdf
2)、模型介绍
-
OPT 模型是一种基于 Decoder Only 结构的模型,它采用了单向 Transformer Decoder 生成输出序列。
-
可在 huggingface 下载 OPT 开源模型:opt125m、opt350m、opt1.3b、opt2.7b、opt6.7b、opt13b、opt30b、opt66b等。
-
OPT系列模型包括了多组不同参数规模的模型权重,如图:
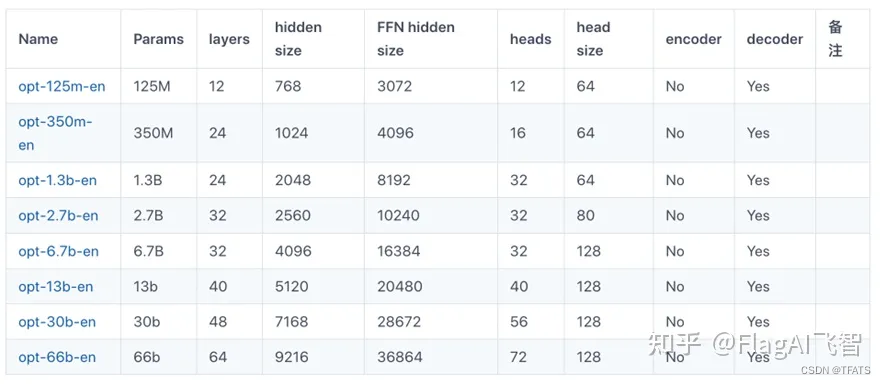
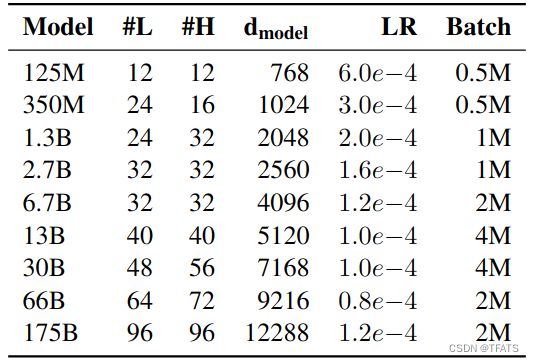
-
OPT 训练策略
对于权重初始化,OPT 遵循 Megatron-LM 代码库[1]中提供的设置,使用均值为零且标准差为 0.006 的正态分布。输出层的标准差按 1.0 / 2 L 1.0/\sqrt{2L} 1.0/2L 的比例缩放,其中 L L L 是层的总数。所有 bias 项初始化为 0,所有模型都使用 ReLU 激活和 2048 的序列长度训练。优化器使用 AdamW, ( B 1 , B 2 ) = 0.9 , 0.95 (B1,B2)=0.9,0.95 (B1,B2)=0.9,0.95,权重衰减 weight decay=0.1,Batch Size 范围从 0.5M 到 4M,具体取决于模型大小。Dropout 设置为 0.1 (Embedding 不使用)。
GPU 资源:使用 992 块 80GB 的 A100 GPU 训练,每个 GPU 最多 147 个 TFLOP/s 的利用。
训练加速:Fully Sharded Data Parallel 技术,Megatron-LM Tensor Parallelism。
为了避免下溢,OPT 使用了动态损失函数缩放。
-
OPT 预训练语料库
预训练语料库包含以下。RoBERTa:使用 RoBERTa 语料库的 BookCorpus 和 Stories 子集,和更新的 CCNews 版本。
Pile:使用 Pile 语料库的子集 CommonCrawl,DM Mathematics,Project Gutenberg,HackerNews,OpenSubtitles,OpenWebText2,,USPTO 和 Wikipedia。作者去掉了 Pile 的其他子集,因为这样可以减轻训练不稳定的风险。
http://PushShift.io Reddit:使用 Pushshift.io 语料库的子集 Reddit。
所有语料库之前都被收集或过滤以包含主要英文文本,但通过 CommonCrawl 在语料库中仍然会出现少量非英语数据。作者对预训练语料库中的重复文档进行了删除操作,发现在 Pile 内部包含许多重复的文档,并建议未来的研究人员对该数据集进行额外的重复数据删除处理。
Tokenizer 使用 GPT-2 byte level BPE tokenizer,最终的训练数据量包含约 180B tokens。
-
OPT 的局限性
- OPT 当指令是声明性说明或填空疑问句时效果不佳,会输出一些 “从此类指令开始的对话的模拟”,而不是 “真正要回答的答案”。针对这个问题,InstructGPT 给出了一些解决的方案。
- OPT-175B 生成的结果也往往是重复的,很容易陷入循环中。未来的工作可能希望结合更多的生成策略来减少重复和改进生成内容的多样性。
- OPT 也会有一些不正确的回复,这点在一些信息准确性很重要的应用里面是有害的。融入一些检索增强 (retrieval-augmentation) 的技术手段也会获益。
- OPT-175B 还是具有很高的生成有毒语言和生成带有有害刻板印象内容的倾向,强化学习改进。
-
综上所述,这项技术对于商业部署来说是过早的。
二、LLaMa
1、背景
LLaMA (Large Language Model Meta AI) 是 Meta 在 2023 年2月发布的一款开源的人工智能大型语言模型(共有7B、13B、33B、65B 四种版本,训练使用多达 14,00B tokens 语料。)。在 2023 年7月,Meta发布了其最新版本LLaMA 2。 相较上一代,LLaMA 2训练所用的token翻了一倍至2万亿,Llama2可免费开源商用。
其模型参数如下表所示: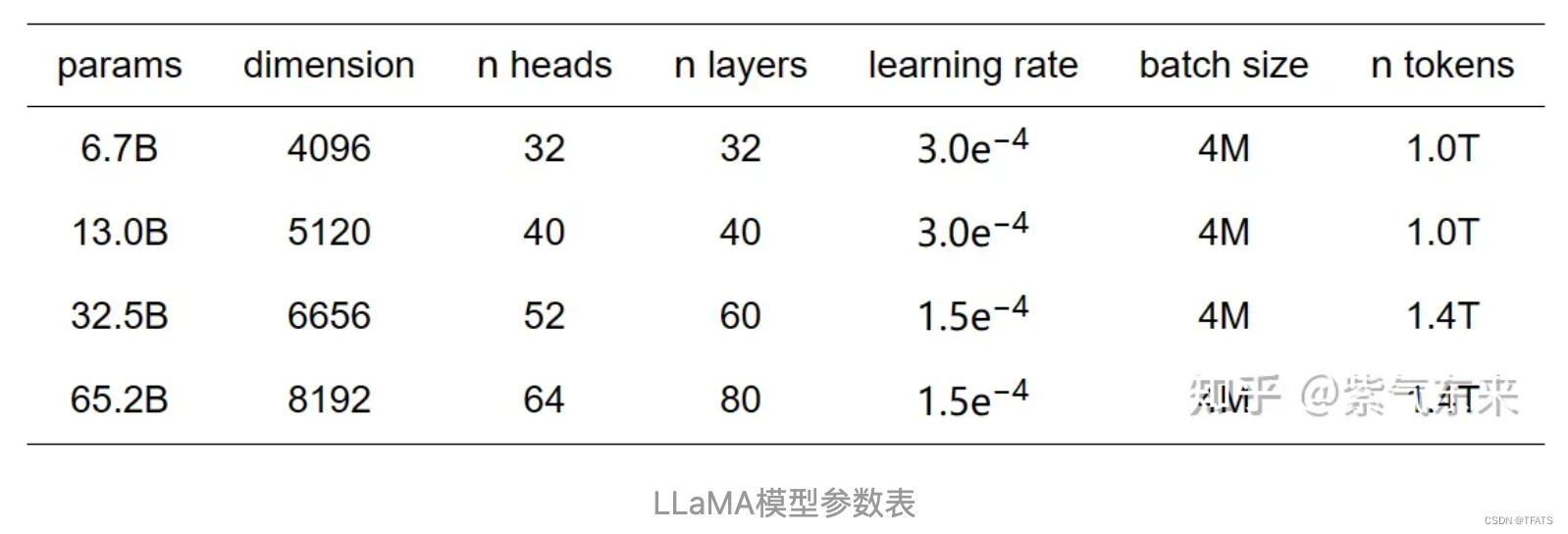
2、模型介绍
1)、开源资源
论文地址: LLaMA: Open and Efficient Foundation Language Models
代码地址: https://github.com/facebookresearch/llama
模型结构源码:llama 模型结构
模型地址:https://huggingface.co/models?sort=downloads&search=llama
2)、模型介绍
-
可在 huggingface 下载 llama-2 开源模型。
-
llama用了tranformer的decoder部分,是decoder-only结构。目前大部分生成式的语言模型都是采用这种结构,bert采用Encoder-only,google t5采用encoder-decoder结构。
-
为什么用decoder-only? 参考苏剑林【为什么现在的LLM都是Decoder-only的架构? - 科学空间|Scientific Spaces】,其中提到了attention在n×d的矩阵与d×n的矩阵相乘后再加softmax(n≫d),这种形式的Attention的矩阵因为低秩问题而带来表达能力的下降,但decoder only因为用了masked attention,是一个下三角矩阵,attention一定是满秩的。
-
与 LLaMA1 相比 LLaMA2 有以下改进:
https://github.com/facebookresearch/llama/issues/384 -
与原始的 transformer Decoder 相比,LLaMA主要有以下改进:
-
a )Pre-normalization
为了提高训练的稳定性,Pre-norm很早就被提出,原生的transformer中使用的是post-norm,也就是在每个子层输出后进行归一化,相比post-norm,pre-norm是在每个子层输入前对输入的数据归一化,pre-norm的训练会更稳定,甚至都可以不需要做warm-up也能很好地训练transformer大模型。除此之外,LLaMa还是用RMSNorm(Root Mean Square Layer Normalization)取代了Layer Norm,RMSNorm是Layer Norm的一种变体,和Layer Norm中减去均值、除以方差的归一化方式不同,RMSNorm是直接除以均方根。 -
b)SwiGLU激活函数
LLaMa使用SwiGLU激活函数替代了原有的ReLU激活函数,以提高性能。SwiGLU是Swish和GLU两个函数的结合
其中Swish=x⋅sigmoid(βx),SwiGLU=Swish(Wx+b)⨂(Vx+c) -
c)RoPE旋转位置编码
LLaMA删除了绝对位置嵌入,使用旋转位置编码,详见:
Transformer升级之路:2、博采众长的旋转式位置编码 -
d)Grouped-query attention(GQA)
由 Transformer 的 QKV,换成了 LLaMA2 的 GQA论文,不同于 LLaMA1、chatGLM 的 MQA(论文) 。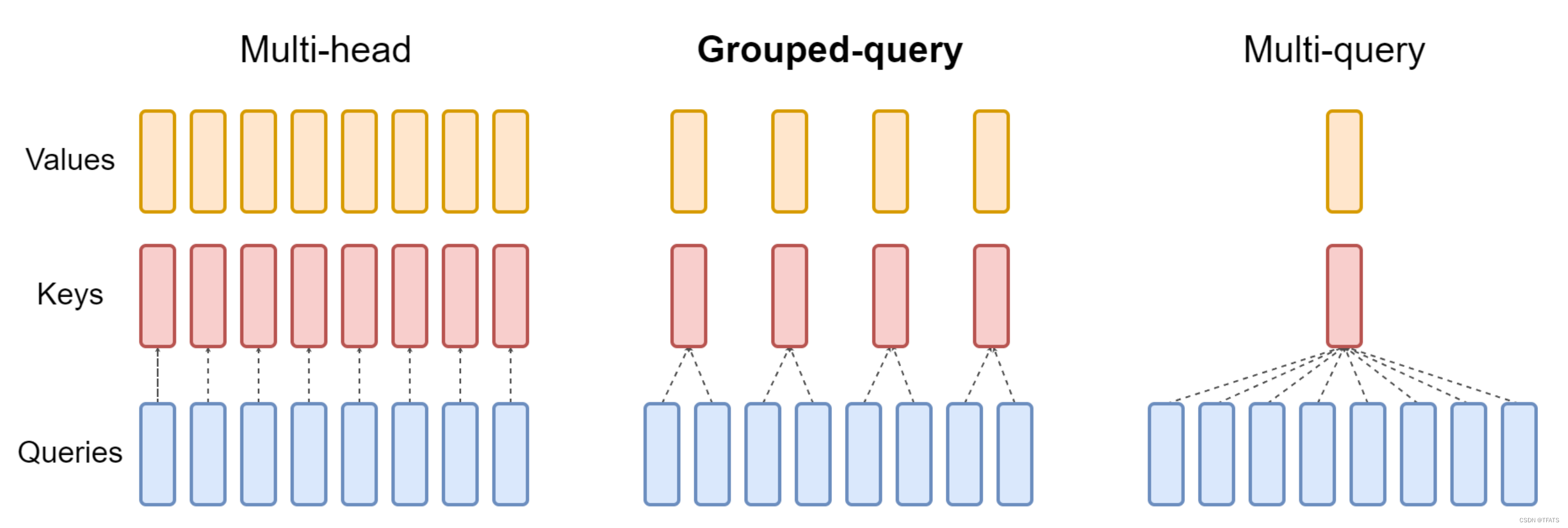
-
三、Alpaca(羊驼)
1、背景
Alpaca 是斯坦福在 LLaMa-7B 的基础上监督微调出来的模型,斯坦福是用OpenAI的Text-davinci-003 API配合 self-instruct 技术,使用175个提示语种子自动生成了52K条提示-回复的指示数据集,在LLaMa-7B上微调得到的模型,在8张80G的A100上训练了3小时。
2、模型介绍
1)、开源资源
文章地址: https://crfm.stanford.edu/2023/03/13/alpaca.html
代码地址: https://github.com/tatsu-lab/stanford_alpaca
2)、模型介绍
它使用 52K 个 intruction-following examples 来微调 Meta 的大语言模型 LLaMA 7B (Meta 开放了模型权重以及 Inference 代码,详见 https://github.com/facebookresearch/llama),从而生成了 Alpaca 7B。
但是这 52K 个 intruction-following examples 是如何生成的呢?Alpaca 团队使用 https://github.com/yizhongw/self-instruct 提供的 175 个 seed tasks,这些 seed tasks 长这样:
调用 OpenAI 的 text-davinci-003 模型,利用 OpenAI 的模型来产生有价值的 instructions!
不得不说,有点机智,这种方式很像蒸馏训练啊。将 OpenAI 性能完备的模型作为 Teacher,来指导参数更少的 Alpaca 模型进行训练,大幅降低了训练成本 。其中调用 OpenAI API 的成本不到 500 美刀,另外微调 7B 参数的 LLaMA 模型,使用云服务商提供的 8 块 80GB A100 显卡,训练 3 小时,消费不到 100 美刀。因此整体成本是小于 600 美刀。
相对来说,确实方便了独立的研究人员、学术机构以及大部分公司。
四、Vicuna(小羊驼)
1、背景
Vicuna 是UC伯克利大学的研究人员联合其它几家研究机构共同推出的一系列基于LLaMa-13B 微调的大语言模型。 数据集来自于ShareGPT.com 产生的用户对话数据,共70K条。通过GPT4来打分评测,Vicuna可以达到ChatGPT 90%的效果。基于LLaMA2的可免费商用授权协议。
2、模型介绍
1)、开源资源
中文领域 lora 训练: https://github.com/Facico/Chinese-Vicuna
2)、模型介绍
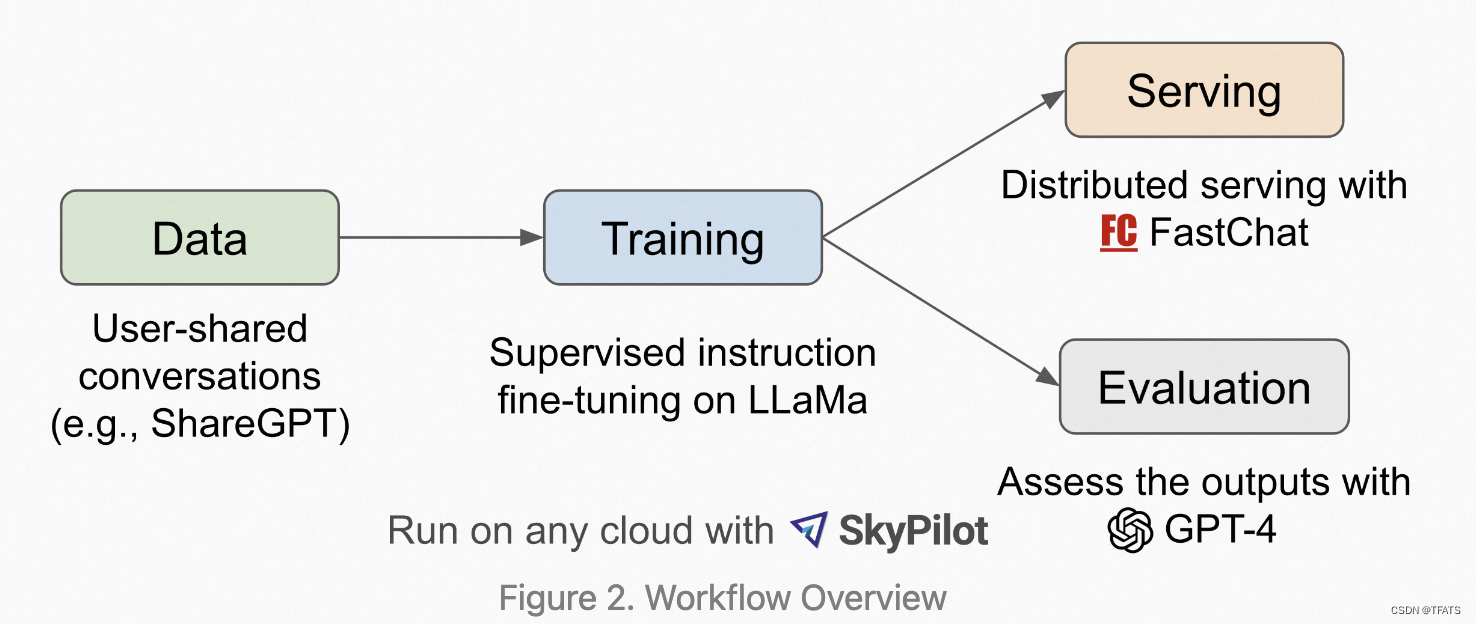
- Vicuna具体的工作流程如下图所示,首先,研究人员从 http://ShareGPT.com(一个供用户分享 ChatGPT 对话内容的网站)收集了约 7 万个对话,相较于Alpaca,Vicuna在训练中将序列长度由512扩展到了2048,并且通过梯度检测和flash attention来解决内存问题;调整训练损失考虑多轮对话,并仅根据模型的输出进行微调,最高支持16K上下文输入。
- 训练是在一天内通过 8 卡 A100 GPU 配合 PyTOrch FSDP 进行的full fine-tune。
- 为了提供演示服务,Vicuna研究人员建立了一个轻量级的分布式服务系统FastChat,创建了八个问题类别(如:角色扮演、编码/数学任务等)的 80 个不同问题,利用 GPT-4 来判断模型输出,借此对模型质量做初步评估。
- 为了比较两个不同的模型,Vicuna研究人员将每个模型的输出组合成每个问题的单个提示。 然后将提示发送到 GPT-4,GPT-4 评估哪个模型提供更好的响应。
五、Moss
1、背景
MOSS是复旦大学自然语言处理实验室发布的国内第一个对话式大型语言模型。2023年4月,复旦MOSS升级版开源上线。
2、开源资源
项目代码: https://github.com/OpenLMLab/MOSS
试用网址: https://moss.fastnlp.top
六、chatGLM
1、背景
ChatGLM-6B、ChatGLM2-6B 是由清华大学 KEG 实验室和智谱 AI 基于千亿基座模型 GLM-130B 开发的对话语言模型,ChatGLM 为 encoder-decoder 架构。
2、开源资源
项目代码:https://github.com/THUDM/ChatGLM2-6B
七、Baichuan
1、背景
2023年6月15日,百川智能公司推出了7B 参数量的中英文预训练大模型——baichuan-7B。2023 年 7月11日,百川智能正式发布参数量13B 的通用大语言模型Baichuan-13B-Base。Baichuan 中英文大模型集高性能、完全开源、免费可商用等于一身。
2、开源资源
项目代码:https://github.com/baichuan-inc/Baichuan2
模型下载:https://huggingface.co/models?search=baichuan
(可下载 7B、13B 模型。)
3、模型介绍
在算法层面:模型架构基本与 LLaMA 一致。
参考:
https://www.zhihu.com/question/606757218/answer/3075464500
https://www.zhihu.com/question/611507751/answer/3114988669
八、Openbuddy
1、背景
OpenBuddy团队发布了基于Meta的LLaMA2基座的跨语言对话模型OpenBuddy-LLaMA2-13B。 LLaMA2仍存在一些局限性,如主要以英语训练数据为主,无法很好地应用于非英语语系的语言。为此,OpenBuddy团队设计并实验了多种微调方案,成功完成了OpenBuddy-LLaMA2-13B的首个版本的训练工作。
2、开源资源
Website: https://openbuddy.ai
GitHub: https://github.com/OpenBuddy/OpenBuddy
Huggingface: https://huggingface.co/OpenBuddy文章来源:https://uudwc.com/A/Mxq65
参考文献:文章来源地址https://uudwc.com/A/Mxq65
- https://github.com/NVIDIA/Megatron-LM/blob/main/examples/pretrain_gpt3_175B.sh
- LLM 系列超详细解读 (五):OPT:完整开源的 GPT-3 复刻版
- https://zhuanlan.zhihu.com/p/618695885