目录
- 架构分类
- 不同架构的有限字长考虑
- s_axis_config的配置
- CP_LEN
- FWD_INV
- SCALE_SCH
- SCALE_SCH位宽
- SCALE_SCH配置的实例
架构分类
分为流水线架构,基-4突发架构,基-2突发架构,基-2LITE突发架构,原文1如下:

基-2和基-4是FFT算法的不同实现形式,简而言之,基-2算法按照时间或频率对序列进行抽取,将序列一分为二,基-4是一分为四。流水线算法能实现数据的连续输出。基-2LITE突发架构基于基-2架构,能比基-2消耗更少的资源,但需要的转换时间更长。几种方法的吞吐量和资源消耗量如图: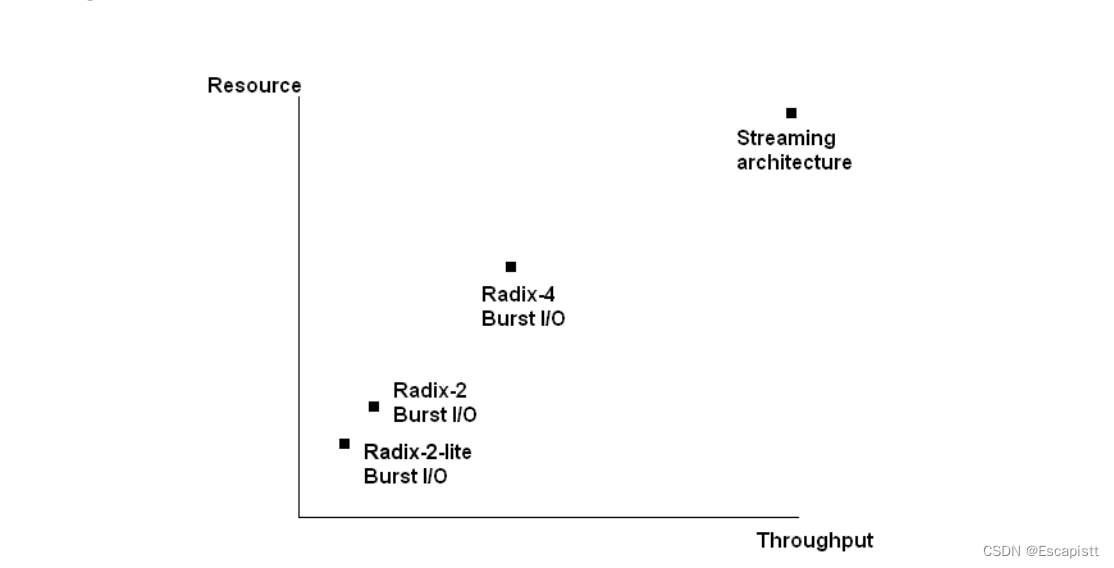
对于使用FFT IP而言,仅需简单了解FFT算法即可,FFT算法通过蝶形运算实现,对于基-2FFT算法,会有log2(N)级蝶形运算,如对于16点的FFT,有4级蝶形运算。基-4FFT算法的级数为log4(N),如对于16点的FFT,有2级蝶形运算。
资源消耗实例:在vivado使用FFT IP,256长度的FFT,位宽为16,旋转因子精度为16,数据为fixed point,截断选项选择scaled,舍入类型为truncation,各种架构的资源消耗量:
| 架构类型 | DSP48 Slices | Block Rams |
|---|---|---|
| 流水线架构 | 9 | 2 |
| 基-4突发架构 | 9 | 7 |
| 基-2突发架构 | 3 | 3 |
| 基-2LITE突发架构 | 2 | 2 |
比较意外的是基-4突发架构比流水线架构消耗了更多Block Rams的资源,评论区有了解原因的朋友欢迎讨论。
不同架构的有限字长考虑
对于基-4架构,每一级会带来的数据增长为5.242:
1
+
3
2
≈
5.242
1+3\sqrt{\smash[b]{2}}\approx5.242
1+32≈5.242
对于基-2架构,每一级会带来的数据增长为2.414:
1
+
2
≈
2.414
1+\sqrt{\smash[b]{2}}\approx2.414
1+2≈2.414
因此对于基-4架构,每级需要增长的位宽为3,基-2为2。
这是需要数据进行缩放的根本原因,所以后面需要配置SCALE_SCH,或者选择不进行缩放,但这样会让输出数据的位宽变得很大,也会消耗更多的资源。
s_axis_config的配置
CP_LEN
一般用于OFDM技术中,用于插入循环前缀,CP_LEN用于配置循环前缀的长度,它的位宽是log2(N),N为FFT/IFFT点数,如点数为256,位宽就是8。配置的数值为循环前缀长度的二进制表示,如循环前缀长度设置为64,则CP_LEN配置为8’b0100_0000。
FWD_INV
配置1或0来实现FFT/IFFT
| 数值 | 含义 |
|---|---|
| FWD_INV = 1 | FFT |
| FWD_INV = 0 | IFFT |
SCALE_SCH
这个参数配置比较复杂,和FFT使用的计算架构有关系,原文1如下: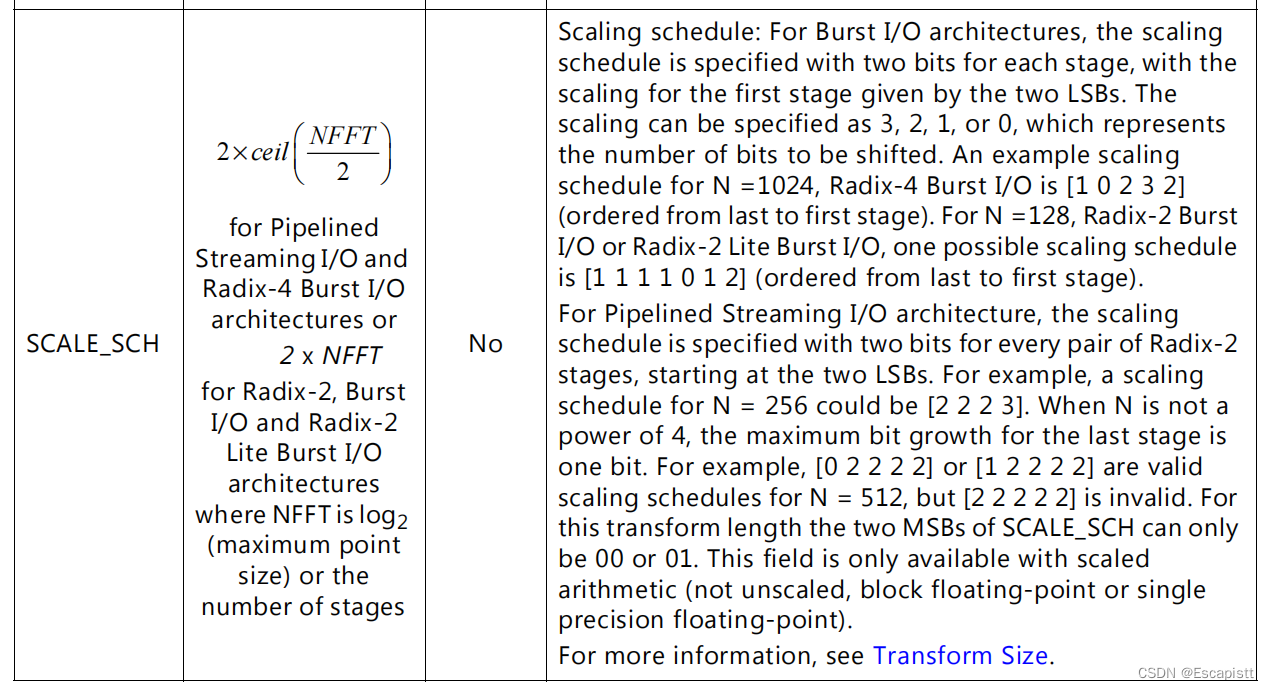
SCALE_SCH位宽
对于基-2架构,宽度为2* NFFT,如对于128长度,宽度为2*log2(128)=14,其中,NFFT=log2(N),这是因为对于基-2FFT算法,会有log2(N)级蝶形运算,每一级都需要有缩放;
对于流水线架构或基-4架构,宽度为2* ceil(NFFT/2),如对于1024长度,2* ceil(NFFT/2)=2* ceil(log2(1024)/2)=10;这是因为基-4FFT算法的级数为log4(N),而流水线架构,原文如下:
In the scaled fixed-point mode, the data is scaled after every pair of Radix-2 stages.
即每对基-2的级进行一次缩放,所以其位宽与流水线架构一样为基-2的1/2。
SCALE_SCH配置的实例
在vivado使用FFT IP,参数还是256长度的FFT,位宽为16,旋转因子精度为16,数据为fixed point,截断选项选择scaled,舍入类型为truncation,架构选择为流水线。此时s_axis_config的宽度为16,[8:1]位为SCALE_SCH,[0:0] 位为FWD_INV,FWD_INV配置为1(FFT)。进行的是256点的FFT,matlab和FPGA的计算结果如下(给出前8个数据):
matlab结果: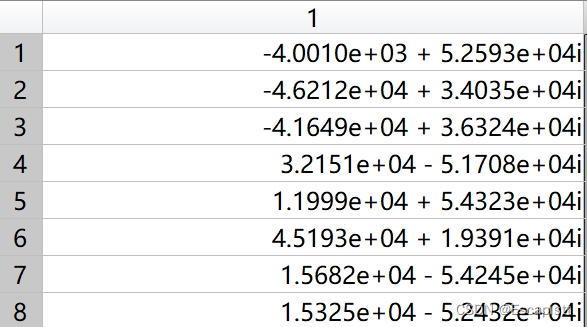
SCALE_SCH配置为0000_0010时,根据前文的描述,代表第一级缩放2位,因此数据应为实际的1/4。FPGA 计算结果(第一行实部第二行虚部),大约为matlab结果的1/4:
方便对照,把matlab结果缩小到1/4: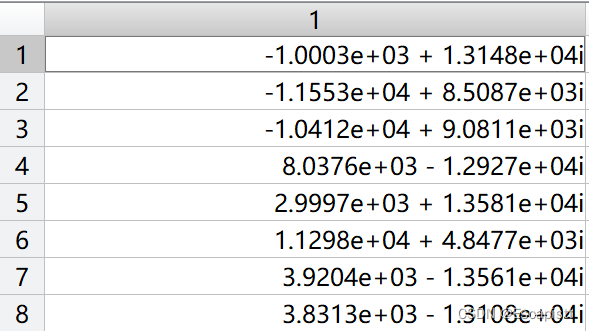
有一定误差,但是整体上和FPGA结果是一致的。
若SCALE_SCH配置为0000_0110,这样第一级缩放2位,第二级缩放一位,应该进一步变成上面计算结果的1/2,FPGA计算结果:
关于SCALE_SCH,最核心的点是不保证数据溢出的前提下,尽可能保持数据的精度,缩放不够数据溢出会发生错误,缩放过多,则数据过小,会降低精度。
在PG1091对数据位宽的增长有详细的描述,这里给出原文:Consider an unscaled Radix-2 DIT FFT: For example, a 1024-point transform with an input of 16 bits consisting of 1 integer bit and 15 fractional bits has an output of 27 bits with 12 integer bits and 15 fractional bits. Note that the core does not have a specific location for the binary point. The output maintains the same binary point location as the input. For the preceding example, a 16-bit input with 3 integer bits and 13 fractional bits would have an unscaled output of 27 bits with 14 integer bits and 13 fractional bits.
它以基-2架构时间抽取的FFT算法为例,FFT是1024点的,会带来12的位宽增长,若输入数据是16位(1位整数位,15位小数位),则输出的数据会增长到27位(12位整数位,15小数位)。小数位是保持不变的,如果输入是16位(3位整数位,13位小数位),则输出为27位(14位整数位,13位小数位)。
而缩放的本质,是小数位的移动。
如3.25的二进制表示为11.01,假定输出数据限定为6位,将该数乘6,结果为19.5,二进制为10011.10,就造成了数据的溢出。若缩小一半,则为9.75,二进制表示为1001.11。实质就是小数位左移一位,同时舍去小数位的最后一位。这样数据就不会溢出了。
因此SCALE_SCH的设定,个人认为可以着眼于不缩放的条件下,小数位不变,和缩放造成的小数位移动上。文章来源:https://uudwc.com/A/MxqRw
-
Product specification. Fast Fourier Transform v9.0, PG109.Xilinx Corp, 2017. ↩︎ ↩︎ ↩︎文章来源地址https://uudwc.com/A/MxqRw