在这篇文章中,我们将了解一个开发团队如何解决他们在应用程序中解析数据时遇到的问题。
为了测试 ONLYOFFICE 文档编辑器,我们用Ruby语言开发编写了个docx、xlsx、pptx文件解析器程序,它是免费开源的,被我们放在GitHub和RubyGems.org上面了,采用AGPL V3开源协议。
本文我们将告诉你这是如何开发的以及这是如何工作的。
没有现成的工具集
我们本可以从很多已有的工具中选择一个来用,但是有不少原因阻止了我们采用现有的工具集:
- 他们大多数都被自己的开发者抛弃了。
- 他们被分为三个独立的库来提供,也就是文档、表格、幻灯片演示这三大类办公文件,三个库的界面接口不同,这使得它们使用起来非常不方便。
- 他们只支持基本的功能。
译者注:很多软件如果被废弃就会因为久不升级而逐渐不支持不断更新升级的工作对象文件,过两三年就会彻底无用,GitHub上各个项目我最关注的就是the latest release的时间,死了好几年的项目一大把,每每看见都会扼腕叹息
给ONLYOFFICE质保QA团队开发的解析器
我们需要一个更强大的工具,测试我们的ONLYOFFICE编辑器,因为ONLYOFFICE编辑器:
- 一直处于活跃开发的状态中
- 允许文档、表格、幻灯片文件使用各种复杂的格式、风格、等功能
- 尽可能的最大化的支持开放文档格式OOXML,即docx、xlsx、pptx文件
解析复杂的功能
ONLYOFFICE编辑器对微软Office格式有最大的支持力度,所以这个测试用解析器也要有同样的支持力度。我们按照ECMA-376 standard标准来开发,该标准实际上分为上下四大册书,总共七千多页。

所以,你可能会理解,我们实际上无法实现该标准所有的细节,但为了测试ONLYOFFICE编辑器高级功能,我们必须涵盖这些功能点。
因此,除了解析基本的功能特征,比如段落、表格、形状等,我们的解析器还要支持:
- 配色主题
- 段落和表格的风格
- 图表
- 分列
- 自动图形的属性
- 列表
为什么我们需要一个解析器
开始启动对ONLYOFFICE的自动测试之后,我们采取了一个功能测试的简单概念。
比如:
- 创建一个新文档
- 随意输入文字并加粗它
- 检查文字是否被加粗
ONLYOFFICE编辑器是由HTML5 Canvas来开发实现的,因此文档里面的文字被作为图像显示出来。从图像里面确认文字的字体是否加粗了,这种事并不容易。比如下图所示,Arial Black字体,你能辨识出这个字体是否加粗了呢?


这就是在这个软件测试的场景下,为什么我们要添加一套额外的确认步骤的原因了:
4. 下载为docx文件,检查确认这个文字就是被赋予了Bold加粗的属性配置。
细节上有数百个类似的属性参数,然而现有的解析器工具没有一个能够支持所有这些参数,有的不过是解析文字、表格以及其它一些简单内容,这就是为什么我们开发自己的测试库的原因了。
这个解析器是如何工作的
如果你曾经把.docx作为zip文件来解压缩,你就会注意到压缩率非常高,那是因为一个OOXML开放文档格式文件实际上就是一套压缩的XML文件。
例如,我们在ONLYOFFICE编辑器中创建一个文件简单输入一些自负然后保存下载为docx文件:

现在我们把它当作一个zip文件来解压缩,就会看到类似如下的文件夹结构:
#tree
.
├── [Content_Types].xml
├── docProps
│ ├── app.xml
│ └── core.xml
├── _rels
└── word
├── document.xml
├── fontTable.xml
├── _rels
│ └── document.xml.rels
├── settings.xml
├── styles.xml
├── theme
│ ├── _rels
│ │ └── theme1.xml.rels
│ └── theme1.xml
└── webSettings.xml
仔细看看这些文件:
[Content_Types].xml —— 文档的MIME类型列表
app.xml —— 文档元数据、应用程序元数据以及统计数据
core.xml —— 最新修改的元数据
document.xml —— 这就是我们要重点查看的文档内容的文件
fontTable.xml —— 文档的字体列表,可能有用
document.xml.rels —— 压缩包中的所有文件的列表,对于复杂文档例如包含有插图、绘图的来说会有用
settings.xml —— 顾名思义,包含文档各种设置,例如默认缩放、数字的分隔符等等
styles.xml、theme1.xml、theme1.xml.rels —— 非常详细的文件,设置风格和主题等信息,识别这些设置的能力就是Office类软件的关键优势之一了
webSettings.xml —— 文档的web版式版本设置,对于docx类文件并不常用的功能 |
译者注:docx类文件在文档编辑器软件中切换为web版式显示画面,可以让文档编辑器软件不去自动计算分页,这对于长达数百页上千页的超大docx文档来说,是在编写过程和只读阅览过程中防止死机提高效率的非常实用的技巧,当然,在排版过程中还是需要切换回常用的页面视图,这个时候就需要办公电脑拥有具备顶级游戏电脑的硬件配置。
所以,如果我们处理上面这个举例的非常简单的文档,我们只需要解析document.xml文件。

这是非常简单的一个XML。幸运的是,这可以用Ruby来轻松解析,我们使用了Nokogiri这个工具,获取DOM树,然后查看OOXML标准,或者是反向工程技术,来看我们所需的参数在哪里。
这个解析器是如何编写出来的
我们开始开发这个工具的时候遇上了两个错误,好在后来我们发现了并改正了。希望我们的经验能够对后来的你们有用,避免发生同样的问题。
大文件
所以,我们需要测试三种不同的编辑器,编辑文档、表格和幻灯片文件,我们如何为此目的而组织代码呢?这就很有趣了,但是,最初我们有四个文件,第四个是为了测试三种编辑器共有的那些通用特性而准备的,这四个文件每个都长达4000多行。调试这些文件花费了很多时间,我们就精心地重新架构了这些代码,结果是分解成为200多个文件,代替先前的四个大文件,这样,现在就很容易定位bug解决bug了。
没有测试
我们:对这个解析器没有测试!因为我们编写这个解析器是用来测试编辑器的,而不是再多开发一个东西来测试这个解析器。
所有事情:我们纠正一处拼写错误来解决一个bug,结果却全部崩溃
所以,我们不得不创建一个特别的文件夹,把这两百多个文件放进来,检查一堆参数,确保知道我们下班之前所做的commit不会crash第三层菜单中某个选项的确认操作,开发团队没有人会详细记得所写代码的所有细节。
我们也有些好主意,例如
使用RuboCop
RuboCop是一个Ruby静态代码分析器和格式化工具,基于Ruby社区风格指南的。我们喜欢这个工具,它帮助我们避免了很多错误,让代码保持干净,确保我们最后的提交没有让代码变坏,感谢经过overcommit进行集成。
例如,如果,在经历了艰难的一天开发滞后,你不小心忘记了Ruby中的变量是小写的,然后就尝试提交类似如下这样的代码:
— path_to_zip_file = copy_file_and_rename_to_zip(path_to_file)
+ ZIP_file = copy_file_and_rename_to_zip(path_to_file)就会报错:
Analyze with RuboCop........................................[RuboCop] FAILED
Errors on modified lines:
ooxml_parser/lib/ooxml_parser/common_parser/parser.rb:8:7: E: dynamic constant assignment如果没有额外的操作,您将无法提交代码。 这是一个极好措施来预防傻瓜式错误的出现。
使用我们的文档库
实际上到我们开发出来这个解析器的时候,我们就已经收集了很多的,实际上,各种奇奇怪怪的docx、xlsx、pptx文件了。我们在ONLYOFFICE编辑器开发的早期阶段,收集了这些文件,用它们来检查复杂文档的渲染功能,几年之后,我们用它们来测试我们的解析器。我们检测到了不少的错误,然后花费了数周的时间来修复它们,但这些工作物有所值。
现在我们就有了解析OOXML文件的强大的工具OOXML Parser,我们用它来测试:
- ONLYOFFICE文档社区版:开源版本由开源社区维护支持;
- ONLYOFFICE文档企业版:2B面向企业端用户的商业销售版本;
- ONLYOFFICE文档开发者版:面向开发商的可以进行开发的版本。
希望这一篇文章可以对你的项目有所帮助,就如ONLYOFFICE一样。

另:解析器怎么用
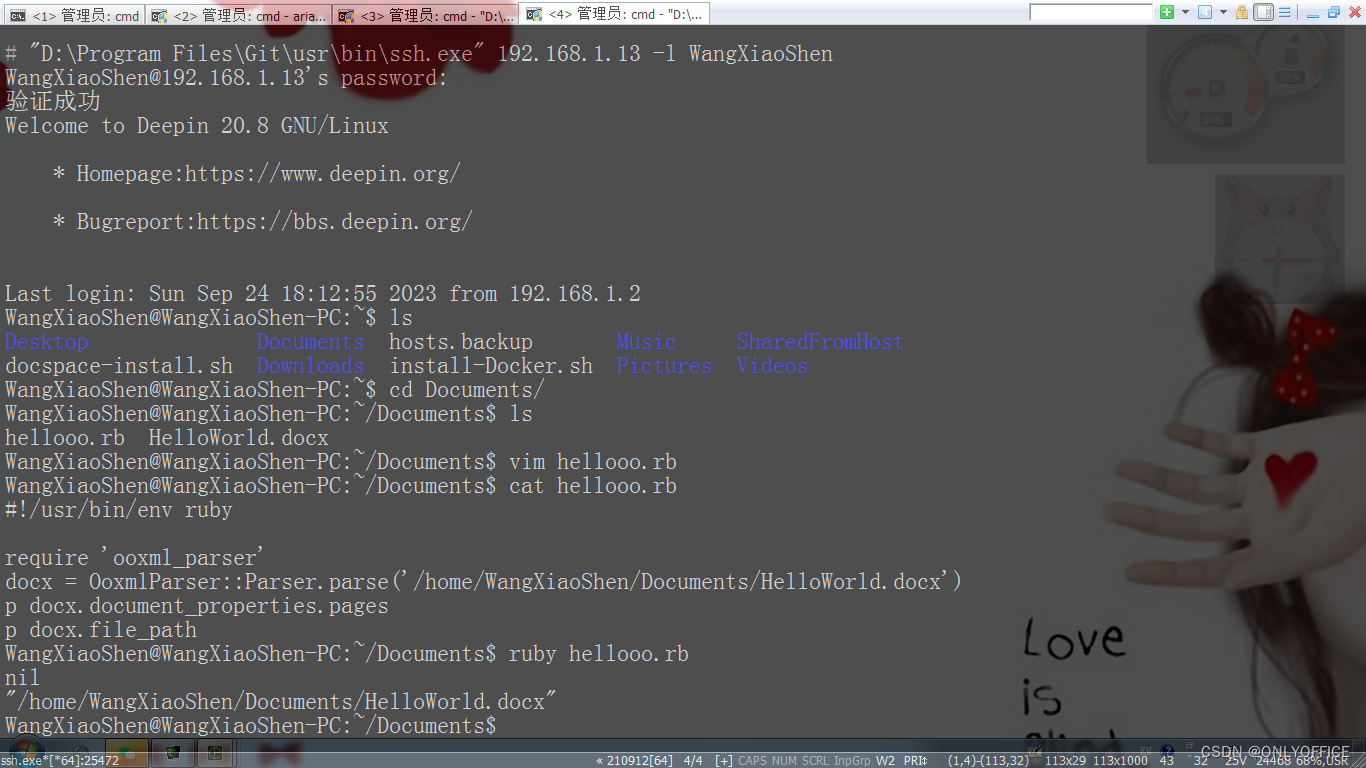
按照OOXML Parser的说明,安装后,编写测试脚本:
#!/usr/bin/env ruby
require 'ooxml_parser'
docx = OoxmlParser::Parser.parse('/home/WangXiaoShen/Documents/HelloWorld.docx')
p docx.document_properties.pages
p docx.file_path执行,可以看到解析结果:
英文原文:Parsing OOXML Files With Ruby - DZone文章来源:https://uudwc.com/A/Mxqqd
译者:天哥文章来源地址https://uudwc.com/A/Mxqqd

