文章目录
- 决策树
- 1 创建数据
- 2 定义香农信息熵
- 3 条件熵
- 4 信息增益
- 5 计算所有特征的信息增益,选择最优最大信息增益的特征返回
- 6 利用ID3算法生成决策树
- 7 利用数据构造一颗决策树
- Scikit-learn实例
- 决策树分类
- 决策树回归
- Scikit-learn 的决策树参数
- 决策树调参
- 实验1 通过sklearn来做breast_cancer数据集的决策树分类器训练
- 准备数据
- 训练模型
- 测试模型
- 实验2 构造下面的数据,并调用前面手写代码实现决策树分类器
- 采用下面的样本进行测试
决策树
1.分类决策树模型是表示基于特征对实例进行分类的树形结构。决策树可以转换成一个if-then规则的集合,也可以看作是定义在特征空间划分上的类的条件概率分布。
2.决策树学习旨在构建一个与训练数据拟合很好,并且复杂度小的决策树。因为从可能的决策树中直接选取最优决策树是NP完全问题。现实中采用启发式方法学习次优的决策树。
决策树学习算法包括3部分:特征选择、树的生成和树的剪枝。常用的算法有ID3、C4.5和CART。
3.特征选择的目的在于选取对训练数据能够分类的特征。特征选择的关键是其准则。常用的准则如下:
(1)样本集合 D D D对特征 A A A的信息增益(ID3)
g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D, A)=H(D)-H(D|A) g(D,A)=H(D)−H(D∣A)
H ( D ) = − ∑ k = 1 K ∣ C k ∣ ∣ D ∣ log 2 ∣ C k ∣ ∣ D ∣ H(D)=-\sum_{k=1}^{K} \frac{\left|C_{k}\right|}{|D|} \log _{2} \frac{\left|C_{k}\right|}{|D|} H(D)=−k=1∑K∣D∣∣Ck∣log2∣D∣∣Ck∣
H ( D ∣ A ) = ∑ i = 1 n ∣ D i ∣ ∣ D ∣ H ( D i ) H(D | A)=\sum_{i=1}^{n} \frac{\left|D_{i}\right|}{|D|} H\left(D_{i}\right) H(D∣A)=i=1∑n∣D∣∣Di∣H(Di)
其中, H ( D ) H(D) H(D)是数据集 D D D的熵, H ( D i ) H(D_i) H(Di)是数据集 D i D_i Di的熵, H ( D ∣ A ) H(D|A) H(D∣A)是数据集 D D D对特征 A A A的条件熵。 D i D_i Di是 D D D中特征 A A A取第 i i i个值的样本子集, C k C_k Ck是 D D D中属于第 k k k类的样本子集。 n n n是特征 A A A取 值的个数, K K K是类的个数。
(2)样本集合 D D D对特征 A A A的信息增益比(C4.5)
g R ( D , A ) = g ( D , A ) H ( D ) g_{R}(D, A)=\frac{g(D, A)}{H(D)} gR(D,A)=H(D)g(D,A)
其中, g ( D , A ) g(D,A) g(D,A)是信息增益, H ( D ) H(D) H(D)是数据集 D D D的熵。
(3)样本集合 D D D的基尼指数(CART)
Gini ( D ) = 1 − ∑ k = 1 K ( ∣ C k ∣ ∣ D ∣ ) 2 \operatorname{Gini}(D)=1-\sum_{k=1}^{K}\left(\frac{\left|C_{k}\right|}{|D|}\right)^{2} Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2
特征 A A A条件下集合 D D D的基尼指数:
Gini ( D , A ) = ∣ D 1 ∣ ∣ D ∣ Gini ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ Gini ( D 2 ) \operatorname{Gini}(D, A)=\frac{\left|D_{1}\right|}{|D|} \operatorname{Gini}\left(D_{1}\right)+\frac{\left|D_{2}\right|}{|D|} \operatorname{Gini}\left(D_{2}\right) Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
4.决策树的生成。通常使用信息增益最大、信息增益比最大或基尼指数最小作为特征选择的准则。决策树的生成往往通过计算信息增益或其他指标,从根结点开始,递归地产生决策树。这相当于用信息增益或其他准则不断地选取局部最优的特征,或将训练集分割为能够基本正确分类的子集。
5.决策树的剪枝。由于生成的决策树存在过拟合问题,需要对它进行剪枝,以简化学到的决策树。决策树的剪枝,往往从已生成的树上剪掉一些叶结点或叶结点以上的子树,并将其父结点或根结点作为新的叶结点,从而简化生成的决策树。
import numpy as np
import pandas as pd
import math
from math import log
1 创建数据
def create_data():
datasets = [['青年', '否', '否', '一般', '否'],
['青年', '否', '否', '好', '否'],
['青年', '是', '否', '好', '是'],
['青年', '是', '是', '一般', '是'],
['青年', '否', '否', '一般', '否'],
['中年', '否', '否', '一般', '否'],
['中年', '否', '否', '好', '否'],
['中年', '是', '是', '好', '是'],
['中年', '否', '是', '非常好', '是'],
['中年', '否', '是', '非常好', '是'],
['老年', '否', '是', '非常好', '是'],
['老年', '否', '是', '好', '是'],
['老年', '是', '否', '好', '是'],
['老年', '是', '否', '非常好', '是'],
['老年', '否', '否', '一般', '否'],
]
labels = [u'年龄', u'有工作', u'有自己的房子', u'信贷情况', u'类别']
# 返回数据集和每个维度的名称
return datasets, labels
datasets, labels = create_data()
train_data = pd.DataFrame(datasets, columns=labels)
train_data
| 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 | |
|---|---|---|---|---|---|
| 0 | 青年 | 否 | 否 | 一般 | 否 |
| 1 | 青年 | 否 | 否 | 好 | 否 |
| 2 | 青年 | 是 | 否 | 好 | 是 |
| 3 | 青年 | 是 | 是 | 一般 | 是 |
| 4 | 青年 | 否 | 否 | 一般 | 否 |
| 5 | 中年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 好 | 否 |
| 7 | 中年 | 是 | 是 | 好 | 是 |
| 8 | 中年 | 否 | 是 | 非常好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 老年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 好 | 是 |
| 12 | 老年 | 是 | 否 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 非常好 | 是 |
| 14 | 老年 | 否 | 否 | 一般 | 否 |
2 定义香农信息熵
def calc_ent(datasets):
data_length = len(datasets)
label_count = {}
for i in range(data_length):
label = datasets[i][-1]
if label not in label_count:
label_count[label] = 0
label_count[label] += 1
ent = -sum([(p / data_length) * log(p / data_length, 2)
for p in label_count.values()])
return ent
3 条件熵
def cond_ent(datasets, axis=0):
data_length = len(datasets)
feature_sets = {}
for i in range(data_length):
feature = datasets[i][axis]
if feature not in feature_sets:
feature_sets[feature] = []
feature_sets[feature].append(datasets[i])
cond_ent = sum([(len(p) / data_length) * calc_ent(p)
for p in feature_sets.values()])
return cond_ent
calc_ent(datasets)
0.9709505944546686
4 信息增益
def info_gain(ent, cond_ent):
return ent - cond_ent
5 计算所有特征的信息增益,选择最优最大信息增益的特征返回
def info_gain_train(datasets):
count = len(datasets[0]) - 1
ent = calc_ent(datasets)
best_feature = []
for c in range(count):
c_info_gain = info_gain(ent, cond_ent(datasets, axis=c))
best_feature.append((c, c_info_gain))
print('特征({}) 的信息增益为: {:.3f}'.format(labels[c], c_info_gain))
# 比较大小
best_ = max(best_feature, key=lambda x: x[-1])
return '特征({})的信息增益最大,选择为根节点特征'.format(labels[best_[0]])
info_gain_train(np.array(datasets))
特征(年龄) 的信息增益为: 0.083
特征(有工作) 的信息增益为: 0.324
特征(有自己的房子) 的信息增益为: 0.420
特征(信贷情况) 的信息增益为: 0.363
'特征(有自己的房子)的信息增益最大,选择为根节点特征'
6 利用ID3算法生成决策树
# 定义节点类 二叉树
class Node:
def __init__(self, root=True, label=None, feature_name=None, feature=None):
self.root = root
self.label = label
self.feature_name = feature_name
self.feature = feature
self.tree = {}
self.result = {
'label:': self.label,
'feature': self.feature,
'tree': self.tree
}
def __repr__(self):
return '{}'.format(self.result)
def add_node(self, val, node):
self.tree[val] = node
def predict(self, features):
if self.root is True:
return self.label
current_tree=self.tree[features[self.feature]]
features.pop(self.feature)
return current_tree.predict(features)
class DTree:
def __init__(self, epsilon=0.1):
self.epsilon = epsilon
self._tree = {}
# 熵
@staticmethod
def calc_ent(datasets):
data_length = len(datasets)
label_count = {}
for i in range(data_length):
label = datasets[i][-1]
if label not in label_count:
label_count[label] = 0
label_count[label] += 1
ent = -sum([(p / data_length) * log(p / data_length, 2) for p in label_count.values()])
return ent
# 经验条件熵
def cond_ent(self, datasets, axis=0):
data_length = len(datasets)
feature_sets = {}
for i in range(data_length):
feature = datasets[i][axis]
if feature not in feature_sets:
feature_sets[feature] = []
feature_sets[feature].append(datasets[i])
cond_ent = sum([(len(p) / data_length) * self.calc_ent(p) for p in feature_sets.values()])
return cond_ent
# 信息增益
@staticmethod
def info_gain(ent, cond_ent):
return ent - cond_ent
def info_gain_train(self, datasets):
count = len(datasets[0]) - 1
ent = self.calc_ent(datasets)
best_feature = []
for c in range(count):
c_info_gain = self.info_gain(ent, self.cond_ent(datasets, axis=c))
best_feature.append((c, c_info_gain))
# 比较大小
best_ = max(best_feature, key=lambda x: x[-1])
return best_
def train(self, train_data):
"""
input:数据集D(DataFrame格式),特征集A,阈值eta
output:决策树T
"""
_, y_train, features = train_data.iloc[:,:-1], train_data.iloc[:,-1], train_data.columns[:-1]
# 1,若D中实例属于同一类Ck,则T为单节点树,并将类Ck作为结点的类标记,返回T
if len(y_train.value_counts()) == 1:
return Node(root=True, label=y_train.iloc[0])
# 2, 若A为空,则T为单节点树,将D中实例树最大的类Ck作为该节点的类标记,返回T
if len(features) == 0:
return Node(root=True,label=y_train.value_counts().sort_values(ascending=False).index[0])
# 3,计算最大信息增益 同5.1,Ag为信息增益最大的特征
max_feature, max_info_gain = self.info_gain_train(np.array(train_data))
max_feature_name = features[max_feature]
# 4,Ag的信息增益小于阈值eta,则置T为单节点树,并将D中是实例数最大的类Ck作为该节点的类标记,返回T
if max_info_gain < self.epsilon:
return Node(root=True,label=y_train.value_counts().sort_values(ascending=False).index[0])
# 5,构建Ag子集
node_tree = Node(root=False, feature_name=max_feature_name, feature=max_feature)
feature_list = train_data[max_feature_name].value_counts().index
for f in feature_list:
sub_train_df = train_data.loc[train_data[max_feature_name] == f].drop([max_feature_name], axis=1)
# 6, 递归生成树
sub_tree = self.train(sub_train_df)
node_tree.add_node(f, sub_tree)
return node_tree
def fit(self, train_data):
self._tree = self.train(train_data)
return self._tree
def predict(self, X_test):
return self._tree.predict(X_test)
7 利用数据构造一颗决策树
datasets, labels = create_data()
data_df = pd.DataFrame(datasets, columns=labels)
dt = DTree()
tree = dt.fit(data_df)
data_df
| 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 | |
|---|---|---|---|---|---|
| 0 | 青年 | 否 | 否 | 一般 | 否 |
| 1 | 青年 | 否 | 否 | 好 | 否 |
| 2 | 青年 | 是 | 否 | 好 | 是 |
| 3 | 青年 | 是 | 是 | 一般 | 是 |
| 4 | 青年 | 否 | 否 | 一般 | 否 |
| 5 | 中年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 好 | 否 |
| 7 | 中年 | 是 | 是 | 好 | 是 |
| 8 | 中年 | 否 | 是 | 非常好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 老年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 好 | 是 |
| 12 | 老年 | 是 | 否 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 非常好 | 是 |
| 14 | 老年 | 否 | 否 | 一般 | 否 |
tree
{'label:': None, 'feature': 2, 'tree': {'否': {'label:': None, 'feature': 1, 'tree': {'否': {'label:': '否', 'feature': None, 'tree': {}}, '是': {'label:': '是', 'feature': None, 'tree': {}}}}, '是': {'label:': '是', 'feature': None, 'tree': {}}}}
有无房子
否 是
↓ ↓
有无工作 是
否 是
↓ ↓
否 是
tree.predict(['老年', '否', '否', '一般'])
'否'
datasets
[['青年', '否', '否', '一般', '否'],
['青年', '否', '否', '好', '否'],
['青年', '是', '否', '好', '是'],
['青年', '是', '是', '一般', '是'],
['青年', '否', '否', '一般', '否'],
['中年', '否', '否', '一般', '否'],
['中年', '否', '否', '好', '否'],
['中年', '是', '是', '好', '是'],
['中年', '否', '是', '非常好', '是'],
['中年', '否', '是', '非常好', '是'],
['老年', '否', '是', '非常好', '是'],
['老年', '否', '是', '好', '是'],
['老年', '是', '否', '好', '是'],
['老年', '是', '否', '非常好', '是'],
['老年', '否', '否', '一般', '否']]
labels
['年龄', '有工作', '有自己的房子', '信贷情况', '类别']
dt.predict(['老年', '否', '否', '一般'])
'否'
Scikit-learn实例
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
使用Iris数据集,我们可以构建如下树:
# data
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = [
'sepal length', 'sepal width', 'petal length', 'petal width', 'label'
]
data = np.array(df.iloc[:100, [0, 1, -1]])
# print(data)
return data[:, :2], data[:, -1],iris.feature_names[0:2]
X, y,feature_name= create_data()
X, y,feature_name
(array([[5.1, 3.5],
[4.9, 3. ],
[4.7, 3.2],
[4.6, 3.1],
[5. , 3.6],
[5.4, 3.9],
[4.6, 3.4],
[5. , 3.4],
[4.4, 2.9],
[4.9, 3.1],
[5.4, 3.7],
[4.8, 3.4],
[4.8, 3. ],
[4.3, 3. ],
[5.8, 4. ],
[5.7, 4.4],
[5.4, 3.9],
[5.1, 3.5],
[5.7, 3.8],
[5.1, 3.8],
[5.4, 3.4],
[5.1, 3.7],
[4.6, 3.6],
[5.1, 3.3],
[4.8, 3.4],
[5. , 3. ],
[5. , 3.4],
[5.2, 3.5],
[5.2, 3.4],
[4.7, 3.2],
[4.8, 3.1],
[5.4, 3.4],
[5.2, 4.1],
[5.5, 4.2],
[4.9, 3.1],
[5. , 3.2],
[5.5, 3.5],
[4.9, 3.6],
[4.4, 3. ],
[5.1, 3.4],
[5. , 3.5],
[4.5, 2.3],
[4.4, 3.2],
[5. , 3.5],
[5.1, 3.8],
[4.8, 3. ],
[5.1, 3.8],
[4.6, 3.2],
[5.3, 3.7],
[5. , 3.3],
[7. , 3.2],
[6.4, 3.2],
[6.9, 3.1],
[5.5, 2.3],
[6.5, 2.8],
[5.7, 2.8],
[6.3, 3.3],
[4.9, 2.4],
[6.6, 2.9],
[5.2, 2.7],
[5. , 2. ],
[5.9, 3. ],
[6. , 2.2],
[6.1, 2.9],
[5.6, 2.9],
[6.7, 3.1],
[5.6, 3. ],
[5.8, 2.7],
[6.2, 2.2],
[5.6, 2.5],
[5.9, 3.2],
[6.1, 2.8],
[6.3, 2.5],
[6.1, 2.8],
[6.4, 2.9],
[6.6, 3. ],
[6.8, 2.8],
[6.7, 3. ],
[6. , 2.9],
[5.7, 2.6],
[5.5, 2.4],
[5.5, 2.4],
[5.8, 2.7],
[6. , 2.7],
[5.4, 3. ],
[6. , 3.4],
[6.7, 3.1],
[6.3, 2.3],
[5.6, 3. ],
[5.5, 2.5],
[5.5, 2.6],
[6.1, 3. ],
[5.8, 2.6],
[5. , 2.3],
[5.6, 2.7],
[5.7, 3. ],
[5.7, 2.9],
[6.2, 2.9],
[5.1, 2.5],
[5.7, 2.8]]),
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]),
['sepal length (cm)', 'sepal width (cm)'])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
((70, 2), (30, 2), (70,), (30,))
决策树分类
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
import graphviz
#1 导入相关包
from sklearn import tree
#2 构建一个决策树分类器模型
clf = DecisionTreeClassifier(criterion="entropy")
#3 采用数据来构建决策树
clf.fit(X_train, y_train)
#4 对决策树模型进行测试
clf.score(X_test, y_test)
0.9
一旦经过训练,就可以用 plot_tree函数绘制树:
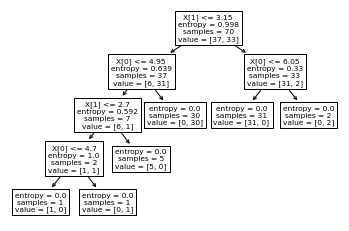
tree.plot_tree(clf)
[Text(0.6, 0.9, 'X[1] <= 3.15\nentropy = 0.998\nsamples = 70\nvalue = [37, 33]'),
Text(0.4, 0.7, 'X[0] <= 4.95\nentropy = 0.639\nsamples = 37\nvalue = [6, 31]'),
Text(0.3, 0.5, 'X[1] <= 2.7\nentropy = 0.592\nsamples = 7\nvalue = [6, 1]'),
Text(0.2, 0.3, 'X[0] <= 4.7\nentropy = 1.0\nsamples = 2\nvalue = [1, 1]'),
Text(0.1, 0.1, 'entropy = 0.0\nsamples = 1\nvalue = [1, 0]'),
Text(0.3, 0.1, 'entropy = 0.0\nsamples = 1\nvalue = [0, 1]'),
Text(0.4, 0.3, 'entropy = 0.0\nsamples = 5\nvalue = [5, 0]'),
Text(0.5, 0.5, 'entropy = 0.0\nsamples = 30\nvalue = [0, 30]'),
Text(0.8, 0.7, 'X[0] <= 6.05\nentropy = 0.33\nsamples = 33\nvalue = [31, 2]'),
Text(0.7, 0.5, 'entropy = 0.0\nsamples = 31\nvalue = [31, 0]'),
Text(0.9, 0.5, 'entropy = 0.0\nsamples = 2\nvalue = [0, 2]')]
也可以导出树
tree_pic = export_graphviz(clf, out_file="mytree.pdf")
with open('mytree.pdf') as f:
dot_graph = f.read()
或者,还可以使用函数 export_text以文本格式导出树。此方法不需要安装外部库,而且更紧凑:
from sklearn.tree import export_text
r = export_text(clf)
print(r)
|--- feature_1 <= 3.15
| |--- feature_0 <= 4.95
| | |--- feature_1 <= 2.70
| | | |--- feature_0 <= 4.70
| | | | |--- class: 0.0
| | | |--- feature_0 > 4.70
| | | | |--- class: 1.0
| | |--- feature_1 > 2.70
| | | |--- class: 0.0
| |--- feature_0 > 4.95
| | |--- class: 1.0
|--- feature_1 > 3.15
| |--- feature_0 <= 6.05
| | |--- class: 0.0
| |--- feature_0 > 6.05
| | |--- class: 1.0
决策树回归
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
rng = np.random.RandomState(1)
rng
RandomState(MT19937) at 0x1AD2E576840
X = np.sort(5 * rng.rand(80, 1), axis=0)
# Create a random dataset
rng = np.random.RandomState(1)
X = np.sort(5 * rng.rand(80, 1), axis=0)
y = np.sin(X).ravel()
y[::5] += 3 * (0.5 - rng.rand(16))
X.shape,y.shape
((80, 1), (80,))
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
X_test.shape
(500, 1)
# Fit regression model
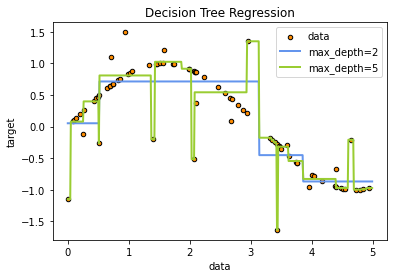
regr_1 = DecisionTreeRegressor(max_depth=2)
regr_2 = DecisionTreeRegressor(max_depth=5)
regr_1.fit(X, y)
regr_2.fit(X, y)
# Predict
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_1 = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test)
# Plot the results
plt.figure()
plt.scatter(X, y, s=20, edgecolor="black", c="darkorange", label="data")
plt.plot(X_test, y_1, color="cornflowerblue", label="max_depth=2", linewidth=2)
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()
Scikit-learn 的决策树参数
DecisionTreeClassifier(criterion=“gini”,
splitter=“best”,
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.,
min_impurity_split=None,
class_weight=None,
presort=False)
参数含义:
- criterion:string, optional (default=“gini”)
(1).criterion=‘gini’,分裂节点时评价准则是Gini指数。
(2).criterion=‘entropy’,分裂节点时的评价指标是信息增益。 - max_depth:int or None, optional (default=None)。指定树的最大深度。
如果为None,表示树的深度不限。直到所有的叶子节点都是纯净的,即叶子节点
中所有的样本点都属于同一个类别。或者每个叶子节点包含的样本数小于min_samples_split。 - splitter:string, optional (default=“best”)。指定分裂节点时的策略。
(1).splitter=‘best’,表示选择最优的分裂策略。
(2).splitter=‘random’,表示选择最好的随机切分策略。 - min_samples_split:int, float, optional (default=2)。表示分裂一个内部节点需要的做少样本数。
(1).如果为整数,则min_samples_split就是最少样本数。
(2).如果为浮点数(0到1之间),则每次分裂最少样本数为ceil(min_samples_split * n_samples) - min_samples_leaf: int, float, optional (default=1)。指定每个叶子节点需要的最少样本数。
(1).如果为整数,则min_samples_split就是最少样本数。
(2).如果为浮点数(0到1之间),则每个叶子节点最少样本数为ceil(min_samples_leaf * n_samples) - min_weight_fraction_leaf:float, optional (default=0.)
指定叶子节点中样本的最小权重。 - max_features:int, float, string or None, optional (default=None).
搜寻最佳划分的时候考虑的特征数量。
(1).如果为整数,每次分裂只考虑max_features个特征。
(2).如果为浮点数(0到1之间),每次切分只考虑int(max_features * n_features)个特征。
(3).如果为’auto’或者’sqrt’,则每次切分只考虑sqrt(n_features)个特征
(4).如果为’log2’,则每次切分只考虑log2(n_features)个特征。
(5).如果为None,则每次切分考虑n_features个特征。
(6).如果已经考虑了max_features个特征,但还是没有找到一个有效的切分,那么还会继续寻找
下一个特征,直到找到一个有效的切分为止。 - random_state:int, RandomState instance or None, optional (default=None)
(1).如果为整数,则它指定了随机数生成器的种子。
(2).如果为RandomState实例,则指定了随机数生成器。
(3).如果为None,则使用默认的随机数生成器。 - max_leaf_nodes: int or None, optional (default=None)。指定了叶子节点的最大数量。
(1).如果为None,叶子节点数量不限。
(2).如果为整数,则max_depth被忽略。 - min_impurity_decrease:float, optional (default=0.)
如果节点的分裂导致不纯度的减少(分裂后样本比分裂前更加纯净)大于或等于min_impurity_decrease,则分裂该节点。
加权不纯度的减少量计算公式为:
min_impurity_decrease=N_t / N * (impurity - N_t_R / N_t * right_impurity
- N_t_L / N_t * left_impurity)
其中N是样本的总数,N_t是当前节点的样本数,N_t_L是分裂后左子节点的样本数,
N_t_R是分裂后右子节点的样本数。impurity指当前节点的基尼指数,right_impurity指
分裂后右子节点的基尼指数。left_impurity指分裂后左子节点的基尼指数。 - min_impurity_split:float
树生长过程中早停止的阈值。如果当前节点的不纯度高于阈值,节点将分裂,否则它是叶子节点。
这个参数已经被弃用。用min_impurity_decrease代替了min_impurity_split。 - class_weight:dict, list of dicts, “balanced” or None, default=None
类别权重的形式为{class_label: weight}
(1).如果没有给出每个类别的权重,则每个类别的权重都为1。
(2).如果class_weight=‘balanced’,则分类的权重与样本中每个类别出现的频率成反比。
计算公式为:n_samples / (n_classes * np.bincount(y))
(3).如果sample_weight提供了样本权重(由fit方法提供),则这些权重都会乘以sample_weight。 - presort:bool, optional (default=False)
指定是否需要提前排序数据从而加速训练中寻找最优切分的过程。设置为True时,对于大数据集
会减慢总体的训练过程;但是对于一个小数据集或者设定了最大深度的情况下,会加速训练过程。
决策树调参
# 导入库
from sklearn.tree import DecisionTreeClassifier
from sklearn import datasets
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeRegressor
from sklearn import metrics
# 导入数据集
X = datasets.load_iris() # 以全部字典形式返回,有data,target,target_names三个键
data = X.data
target = X.target
name = X.target_names
x, y = datasets.load_iris(return_X_y=True) # 能一次性取前2个
print(x.shape, y.shape)
(150, 4) (150,)
# 数据分为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2,random_state=100)
# 用GridSearchCV寻找最优参数(字典)
param = {
'criterion': ['gini'],
'max_depth': [30, 50, 60, 100],
'min_samples_leaf': [2, 3, 5, 10],
'min_impurity_decrease': [0.1, 0.2, 0.5]
}
grid = GridSearchCV(DecisionTreeClassifier(), param_grid=param, cv=6)
grid.fit(x_train, y_train)
print('最优分类器:', grid.best_params_, '最优分数:', grid.best_score_) # 得到最优的参数和分值
最优分类器: {'criterion': 'gini', 'max_depth': 50, 'min_impurity_decrease': 0.2, 'min_samples_leaf': 10} 最优分数: 0.9416666666666665
param = {
'criterion': ['gini',"entropy"],
'max_depth': [30, 50, 60, 100,80],
'min_samples_leaf': [2, 3, 5, 10],
'min_impurity_decrease': [0.1, 0.2, 0.5,0.8],
"splitter":["random","best"]
}
grid=GridSearchCV(DecisionTreeClassifier(),param_grid=param,cv=5)
grid.fit(x_train,y_train)
print(grid.best_params_,grid.best_score_,grid.n_splits_)
{'criterion': 'entropy', 'max_depth': 50, 'min_impurity_decrease': 0.1, 'min_samples_leaf': 10, 'splitter': 'random'} 0.95 5
实验1 通过sklearn来做breast_cancer数据集的决策树分类器训练
准备数据
from sklearn.datasets import load_breast_cancer
bst = load_breast_cancer()
data=bst.data
bst.feature_names
array(['mean radius', 'mean texture', 'mean perimeter', 'mean area',
'mean smoothness', 'mean compactness', 'mean concavity',
'mean concave points', 'mean symmetry', 'mean fractal dimension',
'radius error', 'texture error', 'perimeter error', 'area error',
'smoothness error', 'compactness error', 'concavity error',
'concave points error', 'symmetry error',
'fractal dimension error', 'worst radius', 'worst texture',
'worst perimeter', 'worst area', 'worst smoothness',
'worst compactness', 'worst concavity', 'worst concave points',
'worst symmetry', 'worst fractal dimension'], dtype='<U23')
data.shape
(569, 30)
x=data[:,:2]
labels=bst.feature_names[:2]
labels
array(['mean radius', 'mean texture'], dtype='<U23')
y=bst.target
datasets=np.insert(x,x.shape[1],y,axis=1)
datasets.shape
(569, 3)
data_df = pd.DataFrame(datasets,columns=['mean radius', 'mean texture',"结果"])
data_df
| mean radius | mean texture | 结果 | |
|---|---|---|---|
| 0 | 17.99 | 10.38 | 0.0 |
| 1 | 20.57 | 17.77 | 0.0 |
| 2 | 19.69 | 21.25 | 0.0 |
| 3 | 11.42 | 20.38 | 0.0 |
| 4 | 20.29 | 14.34 | 0.0 |
| ... | ... | ... | ... |
| 564 | 21.56 | 22.39 | 0.0 |
| 565 | 20.13 | 28.25 | 0.0 |
| 566 | 16.60 | 28.08 | 0.0 |
| 567 | 20.60 | 29.33 | 0.0 |
| 568 | 7.76 | 24.54 | 1.0 |
569 rows × 3 columns文章来源:https://uudwc.com/A/NZ8Mk
# 数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
X_train.shape,X_test.shape,y_train.shape,y_test.shape
((398, 2), (171, 2), (398,), (171,))
训练模型
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
import graphviz
clf = DecisionTreeClassifier(criterion="entropy")
clf.fit(X_train, y_train)
DecisionTreeClassifier(criterion='entropy')
测试模型
#4 对决策树模型进行测试
clf.score(X_test, y_test)
0.8713450292397661
实验2 构造下面的数据,并调用前面手写代码实现决策树分类器
 文章来源地址https://uudwc.com/A/NZ8Mk
文章来源地址https://uudwc.com/A/NZ8Mk
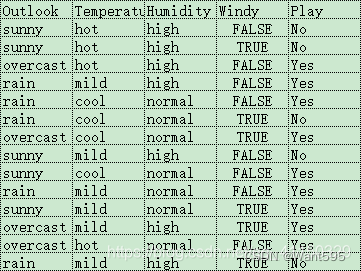
def create_demo():
datasets=[['sunny','hot','high','False','No'],
['sunny','hot','high','True','No'],
['overcast','hot','high','False','Yes'],
['rain','mild','high','False','Yes'],
['rain','cool','normal','False','Yes'],
['rain','cool','normal','True','No'],
['overcast','cool','normal','True','Yes'],
['sunny','mild','high','False','No'],
['sunny','cool','normal','False','Yes'],
['rain','mild','normal','True','Yes'],
['sunny','mild','normal','False','Yes'],
['overcast','mild','high','True','Yes'],
['overcast','hot','normal','False','Yes'],
['rain','mild','high','True','No']]
labels=['Outlook','Temperature','Humidity','Windy','Play']
return datasets,labels
datasets,labels=create_demo()
data_df = pd.DataFrame(datasets,columns=labels)
data_df
| Outlook | Temperature | Humidity | Windy | Play | |
|---|---|---|---|---|---|
| 0 | sunny | hot | high | False | No |
| 1 | sunny | hot | high | True | No |
| 2 | overcast | hot | high | False | Yes |
| 3 | rain | mild | high | False | Yes |
| 4 | rain | cool | normal | False | Yes |
| 5 | rain | cool | normal | True | No |
| 6 | overcast | cool | normal | True | Yes |
| 7 | sunny | mild | high | False | No |
| 8 | sunny | cool | normal | False | Yes |
| 9 | rain | mild | normal | True | Yes |
| 10 | sunny | mild | normal | False | Yes |
| 11 | overcast | mild | high | True | Yes |
| 12 | overcast | hot | normal | False | Yes |
| 13 | rain | mild | high | True | No |
train_data=pd.DataFrame(datasets,columns=labels)
dt = DTree()
tree = dt.fit(data_df)
tree
{'label:': None, 'feature': 0, 'tree': {'sunny': {'label:': None, 'feature': 1, 'tree': {'high': {'label:': 'No', 'feature': None, 'tree': {}}, 'normal': {'label:': 'Yes', 'feature': None, 'tree': {}}}}, 'rain': {'label:': None, 'feature': 2, 'tree': {'True': {'label:': None, 'feature': 0, 'tree': {'mild': {'label:': None, 'feature': 0, 'tree': {'normal': {'label:': 'Yes', 'feature': None, 'tree': {}}, 'high': {'label:': 'No', 'feature': None, 'tree': {}}}}, 'cool': {'label:': 'No', 'feature': None, 'tree': {}}}}, 'False': {'label:': 'Yes', 'feature': None, 'tree': {}}}}, 'overcast': {'label:': 'Yes', 'feature': None, 'tree': {}}}}
Outlook
sunny rain overcast
↓ ↓ ↓
Humidity Windy Yes
high normal True False
↓ ↓ ↓ ↓
No Yes Temperature Yes
mild cool
↓ ↓
Humidity No
normal high
↓ ↓
Yes No
采用下面的样本进行测试
test=["sunny","hot","normal","True"]
tree.predict(test)
'Yes'
