在MySQL数据库中,偶尔会遇到需要查找表中出现的重复数据的情况。这种情况下,我们可以通过编写一些SQL查询语句轻松地找到并处理这些重复行。本文将介绍一些常见的方法和技巧,帮助你有效地查询MySQL表中的重复数据。
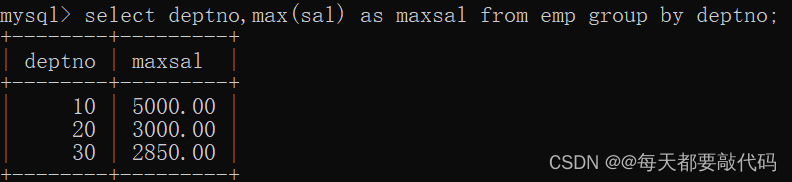
方法一:使用COUNT()函数查询重复行
COUNT()函数是MySQL中常用的聚合函数之一,它可以用于计算表中某个字段值的数量。利用这个函数,我们可以找到表中的重复值和它们的数量。以下是具体的步骤:
编写SQL查询语句来选择你想要查找重复数据所在的数据表,同时选择你想要鉴定的字段。
例如:
SELECT field1, field2, COUNT(field2) FROM table_name GROUP BY field2 HAVING COUNT(field2)>1;
以上语句将查询 table_name 表中 field2 字段的值,并找出出现次数大于1的记录。同时,该查询还会显示 field1 字段的值和该字段对应的 field2 记录中的重复次数。
执行以上查询语句,你将会得到表中所有的重复数据以及对应的出现次数。你可以在查询结果中看到所有出现次数大于1的字段值,这意味着它出现了至少两次。
方法二:使用DISTINCT关键字查询重复行
DISTINCT 关键字可以帮助我们去除表中的重复数据。我们可以编写一条 SQL 查询语句来查找一列中的重复数据。
以下是具体的步骤:
编写SQL查询语句来选择你所需的表,同时选择需要查找的字段。
例如:
SELECT DISTINCT field1 FROM table_name WHERE field2=‘duplicate_value’;
以上语句将查询 table_name 表中所有的 field1 字段,并且只选择其中一个重复值。通过将查询结果与表中所有的唯一值进行比较,我们可以得到这个字段中的重复值。
执行以上的查询语句,你将会得到表中所有的重复数据,同时还会得到所有唯一的 field1 字段值。
方法三:使用自连接查询
使用自连接查询是一种比较复杂的方法,但也是一种非常强大的方法,可以用于查找表中重复的行。
以下是具体的步骤:
编写SQL查询语句,将数据表自连接,使得查询结果中的数据表和原始表是同一个。我们需要选择所需的字段并指定必须相同的字段作为连接条件。
例如,
SELECT A. FROM table_name A INNER JOIN (SELECT field1, field2, COUNT() FROM table_name GROUP BY field1, field2 HAVING COUNT(*)>1) B ON A.field1=B.field1 AND A.field2=B.field2;
以上语句将查询 table_name 表中两列数据:field1 和 field2。它们的值必须与表中的其他记录匹配,以帮助我们找出重复的行。在这个查询中,我们将表名设置为 A,将 inner join 自连接的副本称为 B。
执行以上查询语句,你将会得到表中所有的重复数据。
结论文章来源:https://uudwc.com/A/O4GG
在MySQL中,查找表中重复的数据是一项常见的任务。本文介绍了三种常见的方法来查找表中的重复数据:使用 COUNT() 函数,使用 DISTINCT 关键字以及使用自连接查询。这些技巧都非常有效,你可以根据实际情况选择最合适的方法。无论哪种方法,都可以帮助你在数据库中有效地查找重复的数据。文章来源地址https://uudwc.com/A/O4GG