目录
一、 调参核心问题
二、 随机森林调参方向
三、随机森林调参方法
1、绘制学习曲线
2、网格搜索
四、 详细代码
对于调参,首先需要明白调参的核心问题是什么,然后理清思路,再进行调参。调参并非是一件容易的事情,很多大牛靠的是多年积累的经验和清晰的处理思路,那对于我们而言,也应对调参思路和方向有一个认识,然后就是不断地尝试。
一、调参核心问题
1、调参的目的是什么?
2、模型在未知数据上的准确率受什么因素影响?
泛化误差:衡量模型在未知数据上的准确率(准确率越高,泛化误差越小),受模型复杂度的影响。
模型复杂度与准确率的关系,就像压力值与考试成绩的关系,压力越大或者没有压力成绩往往越低,只有压力适当时,成绩才会更高。同理,模型越复杂或越简单往往结果也会不尽人意,那我们的目标就清楚了,就是将模型不至于太复杂也不至于太简单。比如,当为模型增加复杂度时,准确率提升,泛化误差降低,那说明此时模型有些简单,反之,如果降低模型复杂度,反而准确率提升,那说明此时模型较为复杂,适当调整简单即可。
对于树模型或者树的集成模型,树的深度越深,枝叶越多,模型越复杂。往往树模型或者树的集成模型普遍较为复杂,我们需要做的就是降低复杂度,进而提升准确率。
二、 随机森林调参方向
降低复杂度,对复杂度影响巨大的参数挑选出来,研究他们的单调性,然后专注调整那些最大限度能让复杂度降低的参数,对于那些不单调的参数或者反而让复杂度升高的参数,视情况而定,大多时候甚至可以退避。(表中从上往下,建议调参的程度逐渐减小)

三、随机森林调参方法
1、绘制学习曲线
有些参数没有参照,很难说清楚范围,这种情况用学习曲线看趋势,从曲线跑出的结果中选取一个更小的区间,再跑曲线,以此类推(建议打印输出最大值及其取的值)。
#调参第一步:n_estimators
cross = []
for i in range(0,200,10):
rf = RandomForestClassifier(n_estimators=i+1, n_jobs=-1,random_state=42)
cross_score = cross_val_score(rf, xtest, ytest, cv=5).mean()
cross.append(cross_score)
plt.plot(range(1,201,10),cross)
plt.xlabel('n_estimators')
plt.ylabel('acc')
plt.show()
print((cross.index(max(cross))*10)+1,max(cross))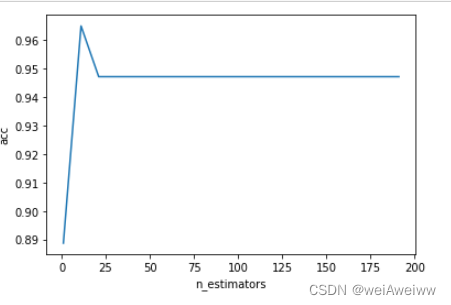
2、网格搜索
有一些参数有一定范围,或者我们知道他们的取值和随着他们的取值模型的准确率会如何变化。在这里值得说明的一点是,网格搜索,如果一次性在参数列表中写出多个参数及对应值,它不会抛弃任何一个我们设置的参数值,会尽力组合,而有时候效果可能不太好,且费时。那建议的操作是,可以一次设定一到两个参数及其值。
from sklearn.model_selection import GridSearchCV
#调整max_depth
param_grid = {'max_depth' : np.arange(1,20,1)}
#一般根据数据大小进行尝试,像该数据集 可从1-10 或1-20开始
rf = RandomForestClassifier(n_estimators=11,random_state=42)
GS = GridSearchCV(rf,param_grid,cv=5)
GS.fit(data.data,data.target)
GS.best_params_ #最佳参数组合
GS.best_score_ #最佳得分四、详细代码
代码建议在jupyter notebook分段运行,因为最起码能保证划分的测试集和训练集不会变化,这样调参才有意义。文章来源:https://uudwc.com/A/OVJ5
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
data = load_breast_cancer() #乳腺癌案例
print(data.data.shape)
xtrain,xtest,ytrain,ytest = train_test_split(data.data,data.target,test_size=0.3)
# GridSearchCV
rf = RandomForestClassifier(n_estimators=100,random_state=42)
rf.fit(xtrain,ytrain)
score = rf.score(xtest,ytest)
cross_s = cross_val_score(rf,xtest,ytest,cv=5).mean()
print('rf:',score)
print('cv:',cross_s)
#调参第一步:n_estimators
cross = []
for i in range(0,200,10):
rf = RandomForestClassifier(n_estimators=i+1, n_jobs=-1,random_state=42)
cross_score = cross_val_score(rf, xtest, ytest, cv=5).mean()
cross.append(cross_score)
plt.plot(range(1,201,10),cross)
plt.xlabel('n_estimators')
plt.ylabel('acc')
plt.show()
print((cross.index(max(cross))*10)+1,max(cross))
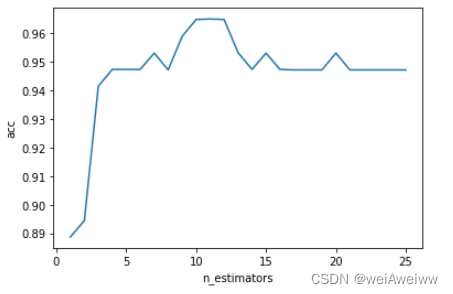
# n_estimators缩小范围
cross = []
for i in range(0,25):
rf = RandomForestClassifier(n_estimators=i+1, n_jobs=-1,random_state=42)
cross_score = cross_val_score(rf, xtest, ytest, cv=5).mean()
cross.append(cross_score)
plt.plot(range(1,26),cross)
plt.xlabel('n_estimators')
plt.ylabel('acc')
plt.show()
print(cross.index(max(cross))+1,max(cross))
#调整max_depth
param_grid = {'max_depth' : np.arange(1,20,1)}
#一般根据数据大小进行尝试,像该数据集 可从1-10 或1-20开始
rf = RandomForestClassifier(n_estimators=11,random_state=42)
GS = GridSearchCV(rf,param_grid,cv=5)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_
#调整max_features
param_grid = {'max_features' : np.arange(5,30,1)}
rf = RandomForestClassifier(n_estimators=11,random_state=42)
GS = GridSearchCV(rf,param_grid,cv=5)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_
#调整min_samples_leaf
param_grid = {'min_samples_leaf' : np.arange(1,1+10,1)}
#一般是从其最小值开始向上增加10或者20
# 面对高维度高样本数据,如果不放心,也可以直接+50,对于大型数据可能需要增加200-300
# 如果调整的时候发现准确率怎么都上不来,那可以放心大胆调一个很大的数据,大力限制模型的复杂度
rf = RandomForestClassifier(n_estimators=11,random_state=42)
GS = GridSearchCV(rf,param_grid,cv=5)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_
#调整min_samples_split
param_grid = {'min_samples_split' : np.arange(2,2+20,1)}
#一般是从其最小值开始向上增加10或者20
# 面对高维度高样本数据,如果不放心,也可以直接+50,对于大型数据可能需要增加200-300
# 如果调整的时候发现准确率怎么都上不来,那可以放心大胆调一个很大的数据,大力限制模型的复杂度
rf = RandomForestClassifier(n_estimators=11,random_state=42)
GS = GridSearchCV(rf,param_grid,cv=5)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_
#调整criterion
param_grid = {'criterion' :['gini','entropy']}
#一般是从其最小值开始向上增加10或者20
# 面对高维度高样本数据,如果不放心,也可以直接+50,对于大型数据可能需要增加200-300
# 如果调整的时候发现准确率怎么都上不来,那可以放心大胆调一个很大的数据,大力限制模型的复杂度
rf = RandomForestClassifier(n_estimators=11,random_state=42)
GS = GridSearchCV(rf,param_grid,cv=5)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_希望大家有所收获,欢迎留言~文章来源地址https://uudwc.com/A/OVJ5