在实际的业务开发中,比如针对一个业务流程,调用三方,然后存储数据,从oss上获取数据。其实都是进行的同步调用,说白了就是A完成之后,B在继续完成。如果整个过程中A、B、C 分别耗时100、300、200毫秒。那么整体的耗时就是600毫秒。
但是如果使用异步方式,而整体A、B、C又没有数据依赖,就可以将整体的耗时提升到300毫秒。但是虽然异步的方式可以提升整体的速度。但是在业务中嵌套太多非阻塞API其实对于整体的来说,BUG、开发效率也不高。并且业务中需要嵌套很多多线程、异步的代码。
其实可以看出,本质上为了提升性能,从多进程、多线程、到异步、协程都是通过不同的技术去解决问题。
如何通过切换请求实现高并发
多进程是利用将CPU执行权,按照时间段进行分片,比如1S中 分为100个10毫秒,那么每个程序都可以根据一定的调度算法获取执行权。虽然从宏观上看是并发执行,但是微观上确实串行执行。进程也因为管理成本高,无法通过内存同步数据。于是出现了多线程,多线程虽然可以通过共享虚拟内存来实现数据的共享,但是因为其本身消耗内存过多,并且当出现多个线程调用的时候,上下文切换也会导致资源的消耗。
如图是通过同步阻塞方式读取。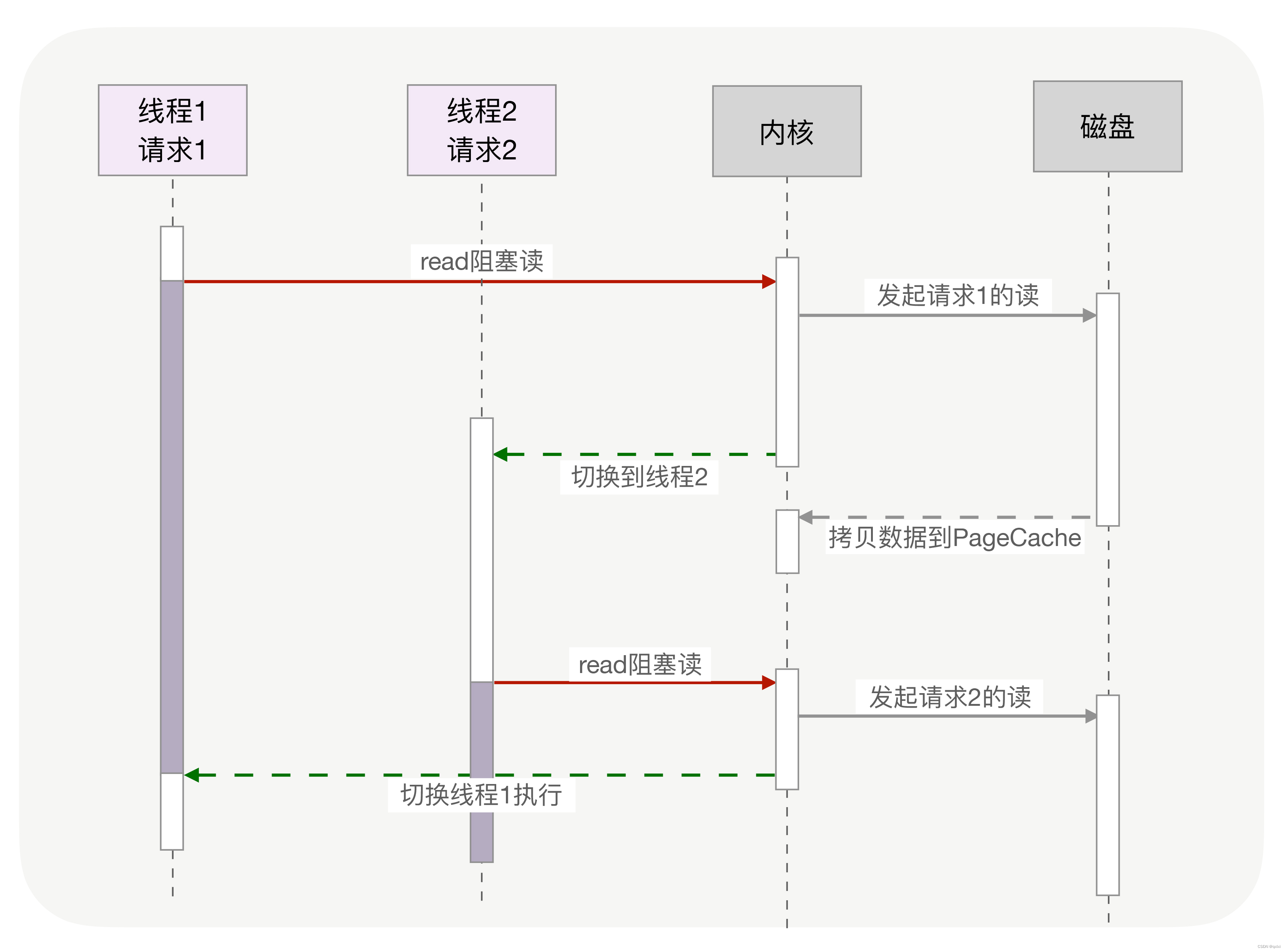
而目前主流的IO多路复用,采用非阻塞IO其实就是将内核态的请求切换工作,转移到用户态中来做处理,异步化编程通过应用层实现请求切换,降低内存成本和切换成本。异步化其实依赖于IO多路复用机制,比如linux中的epoll。

可以发现使用异步化,请求发起IO读取之后会进行注册回调函数,而通过异步回调函数可以进行避免线程切换。
协程如何实现高并发的
协程与异步编程的相似点在于通过使用非阻塞的系统调用与内核交互,切换请求在用户态中完成。协程是通过封装称一个函数来完成。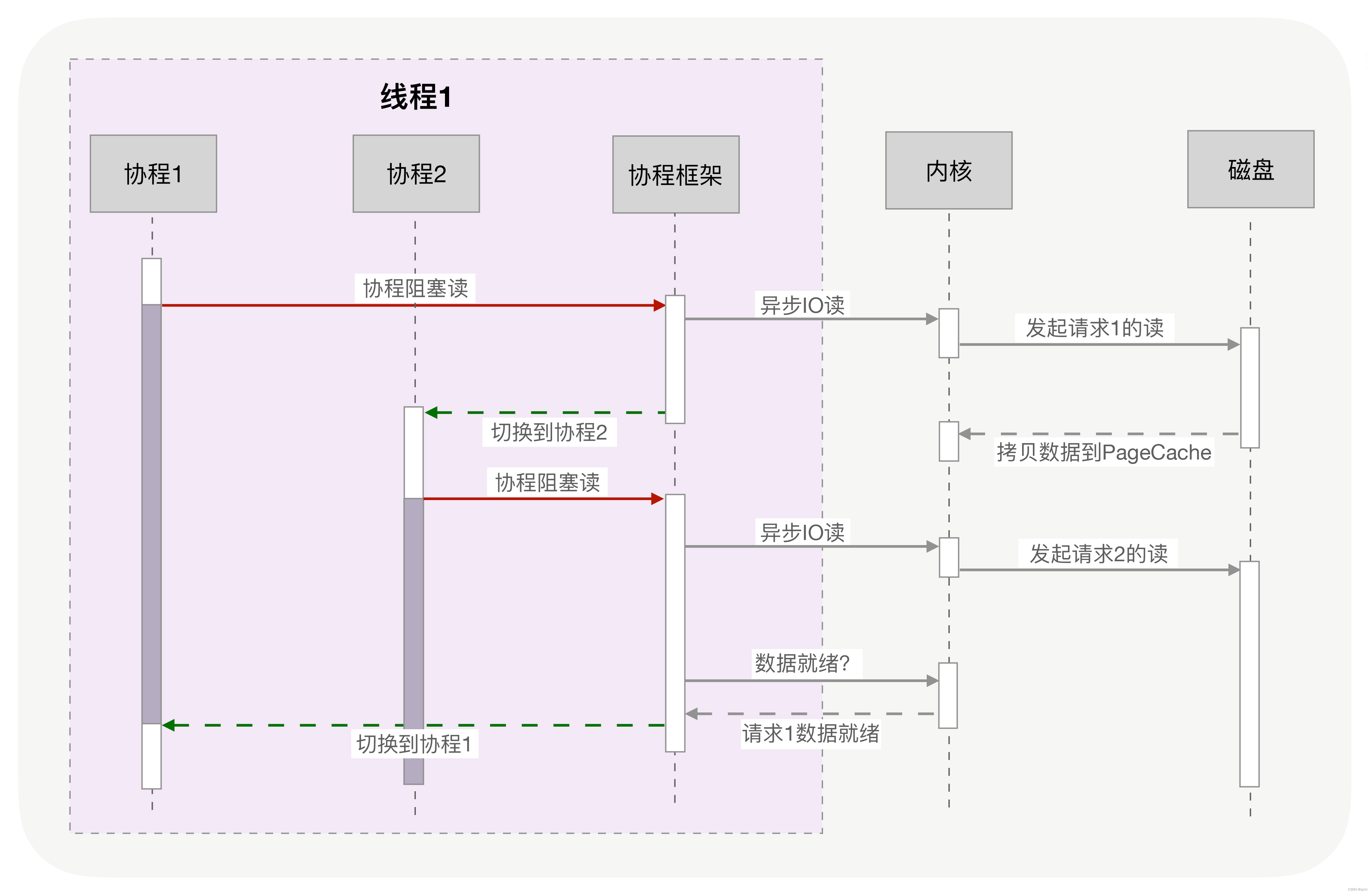
协程的切换其实和内核态的切换线程是一样的。因为内核态的线程切换是通过CPU的寄存器来完成的。
每个线程都有自己的栈和下一条要执行的指令代码寄存器,首先需要先保存A线程的当前栈和下一条要执行的指令,然后将B线程的当前栈设置为它的下一条要执行的指令。就可以完成线程切换。同理协程也是这样的。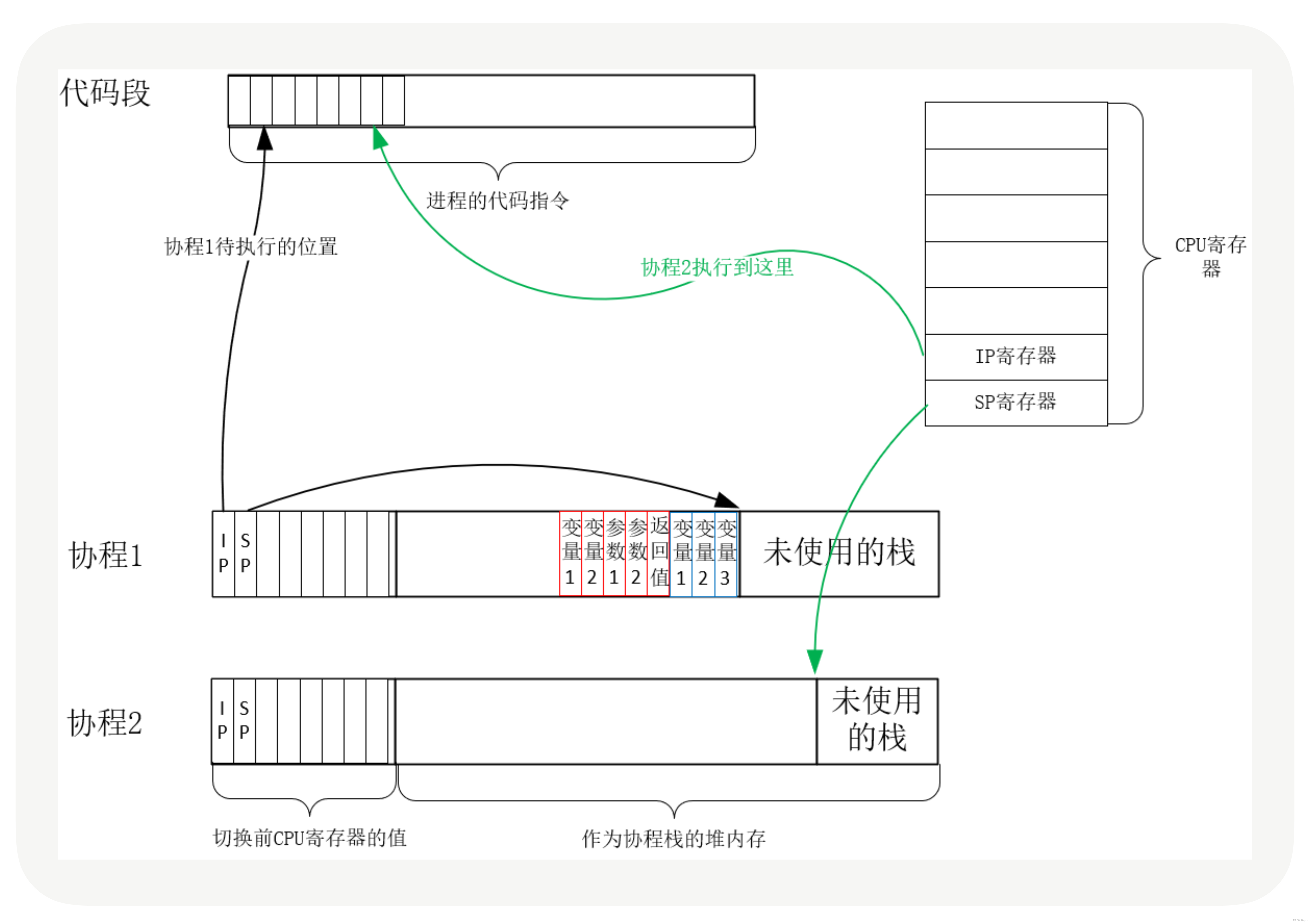
线程的栈有8MB,而协程通过只有几十KB。可以占用更低的内存支持高并发。
因而协程是用户态的线程,如果线程进行切换,那么这个线程内的协程都将丢失执行信息,所以这个必须有协程框架来进行调度。
协程的高性能,建立在切换必须由用户内核态代码完成。文章来源:https://uudwc.com/A/OqA9N
小结
本篇主要介绍了为了提升运行效率,从进程、线程、异步编程、协程,每种方式都有自己的优缺点,但是归根结底都是为了实现更好的业务开发,而通过减少内存占用和内核中上下文切换(线程),将协程搬到了用户态进行上下文切换。但是从设计角度违反了内聚性。
这里简单解释以下 并发是一段时间内执行多个任务。并行是同一时刻执行多个任务。串行是一个执行完另一个执行。文章来源地址https://uudwc.com/A/OqA9N