更好的阅读体验 \huge{\color{red}{更好的阅读体验}} 更好的阅读体验
简介
Neo4j 是用 Java 实现的开源 NoSQL 图数据库。从2003年开始开发,2007年正式发布第一版,其源码托管于 GitHub。
与常见的关系型数据库不同,Neo4j 基于图图结构来表示和存储数据,并提供了申明式的查询语言 Cypher 来处理图数据。Neo4j 实现了专业数据库级别的图数据模型的存储,提供了完整的数据库特性,包括 ACID 事务的支持、集群的支持、备份和故障转移等。
Neo4j 作为图数据库中的代表产品,已经在众多的行业项目中进行了应用,如:网络管理、软件分析、组织和项目管理、社交项目等方面。
安装
Docker 部署
这里为了便于练习,我将其使用 Docker 部署到了我滴云服务器上,参考 Docker部署,其他部署方式参考。
首先拉取镜像(可以指定版本):
docker pull neo4j:4.4.5
然后编写一个简单的运行脚本 run.sh:
#!/bin/bash
docker run \
-d \
--restart=always \
--name neo4j \
-p 7474:7474 \
-p 7687:7687 \
-v $HOME/docker/neo4j/data:/data \
neo4j:4.4.5
然后运行脚本部署即可,browser 管理端口为 7474。
Browser
Browser 端是 Neo4j 提供的一个图形用户界面(GUI)工具,用于管理和操作 Neo4j 图数据库。
浏览器打开:http://服务器地址:7474 即可访问。
如果没有在启动容器时指定密码,登录的默认密码为 neo4j,首次登录后需要重设密码。
不出意外的,便能看到如下界面,建议想要快速入门的话直接跟着官方教程走一遍:
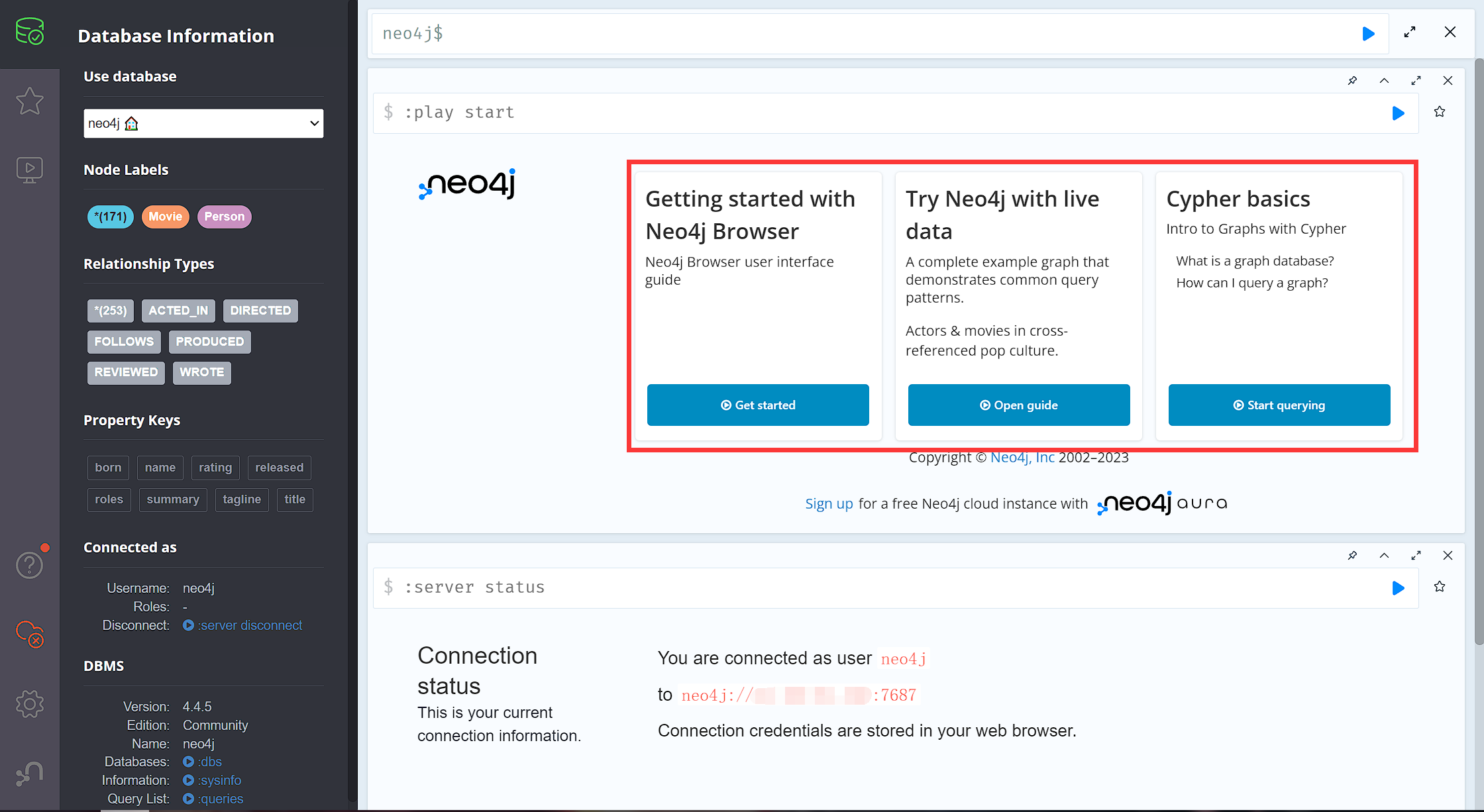
Browser 端支持:
-
Cypher语言支持:允许用户编写和执行Cypher语句,支持对数据库中的节点和关系进行查询或编辑操作。 - 图形可视化:支持节点和关系的可视化布局,能够更直观地体现和反映图数据库中的数据模型和关系。
- 图形分析:提供了一些图形分析功能,如路径查找、社区检测和聚类分析等。
- 用户管理:管理
Neo4j数据库的用户和权限,创建和管理用户账号,分配不同的角色和权限,以控制对数据库的访问和操作。
Cypher-shell
Cypher-shell 是 Neo4j 提供的官方命令行工具,用于执行 Cypher 语言。
使用如下命令进行连接:
cypher-shell -u <用户名> -p <密码> -a <数据库地址>
如果是 Docker 部署,进入容器操作即可:
docker exec -it <容器名> cypher-shell -u <用户名> -p <密码>
退出 Cypher-shell :
:exit
Cypher 基础语法
Cypher 是用于图形数据库 Neo4j 的查询语言,它用于在图形数据库中进行数据检索和操作。Cypher 的语法简洁而直观,旨在提供一种易于理解和使用的方式来查询和操作图形数据。
注意:
-
CQL与关系型数据库中的SQL,一些关键词来源于SQL,比如:CREATE、WHERE、RETURN等。 -
CQL关键字大小写不敏感,也使用;分割多条查询语句。
数据结构
在学习 Cypher 语法前,首先需要了解 Neo4j 数据库的数据结构。
如果你在 Browser 端尝试运行了 Try Neo4j with live data 教程中的第一段代码,你会看到如下界面:
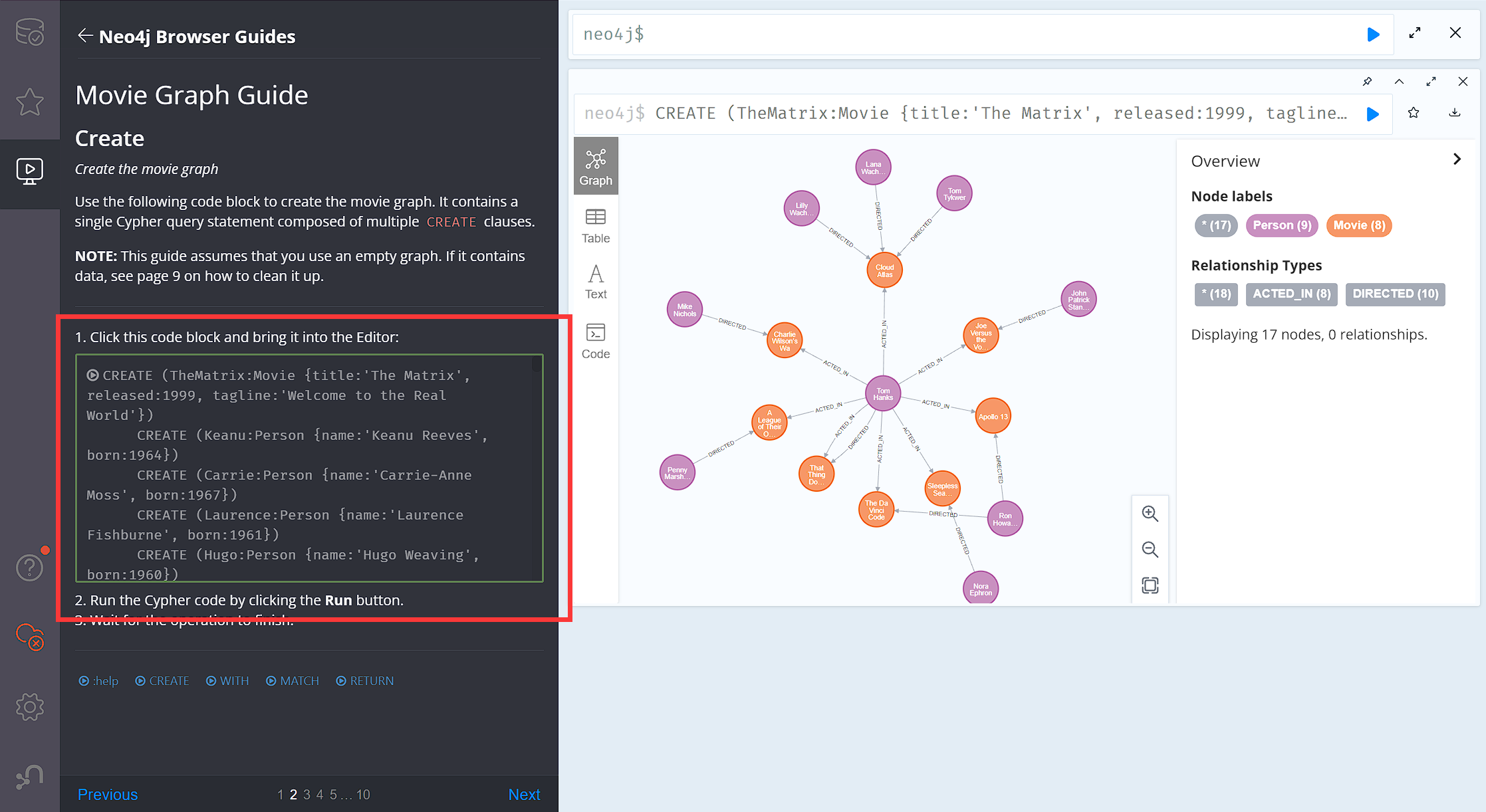
如图所示,Neo4j 中采用节点、属性、关系、标签来存储数据,即右半部分出现的图谱。
- 节点:
- 节点是图数据模型的基本单元,用于存储实体数据。
- 例如,在上图中,演员、电影都是节点,其中每个节点都有对应的属性。
- 可以将一个节点理解为关系型数据库表中的一条数据,其字段对应节点的属性。
- 关系:
- 关系用于表示节点之间的连接或关联,具有一个类型(Type),用于描述节点之间的关系。
- 关系有且只有一个类型,且必须声明其开始节点和结束节点以及指向。
- 关系可以自我循环引用,但是两头永远不能为空。
- 属性:
- 节点和关系都可以有属性,它是由键值对组成的。
- 属性可以是基本数据类型(例如字符串、整数、浮点数等)或复杂数据类型(例如数组、日期等)。
- 节点的属性可以理解为关系型数据库中的字段。关系中的属性进一步的明确了关系。
- 标签:
- 标签是对节点的分类,这样使得构建
Neo4j数据模型更加简单。 - 在上面的电影案例中,
Movie、Person就是标签。
- 标签是对节点的分类,这样使得构建
数据库操作
创建数据库:
CREATE DATABASE name;
删除数据库:
DROP DATABASE name;
修改数据库:
ALTER DATABASE name;
Neo4j 社区版不支持创建、删除和修改数据库,即上面的三个命令社区版用不鸟?,只能使用默认的 neo4j 和 system 数据库。
查看所有数据库:
SHOW DATABASES;
打开数据库:
START DATABASE name;
关闭数据库:
STOP DATABASE name;
社区版只能同时运行一个数据库实例,如果存在正在运行的实例则启动失败?,想同时管理多个还是用企业版吧(
CREATE
创建节点
使用 CREATE 命令来创建节点:
CREATE (n); // 创建一个节点,没有任何标签和属性
创建一个标签为 DOG 的节点:
CREATE (n:DOG);
支持存在多个标签:
CREATE (n:ANIMAL:DOG);
添加属性:
CREATE (n:DOG {name: "LYS", age: 14});
创建多个节点:
CREATE (n:DOG {name: "LYS", age: 14}), (m:CAT {name: "Hiiro", age: 17});
n 和 m 只是节点的变量名,在同一条创建语句中节点的变量名不能相同,节点的变量名不会影响后续的查询。
当然也可以不加变量名:
CREATE (:DOG {name: "LYS", age: 14}), (:CAT {name: "Hiiro", age: 17});
创建关系
创建两个节点的同时创建关系:
CREATE (n:DOG {name: "LYS", age: "14"}) -[r:IN_FAN]-> (m:CAT {name: "Hiiro", age: "17"});
也可以反向创建关系:
CREATE (n:DOG {name: "LYS", age: "14"}) <-[r:out_FAN]- (m:CAT {name: "Hiiro", age: "17"});
关系也可以设置属性:
CREATE (n:DOG {name: "LYS", age: "14"}) -[r:IN_FAN {action: "watch live any time"}]-> (m:CAT {name: "Hiiro", age: "17"});
可以一次性直接创建一条路径:
CREATE (n:DOG {name: "LYS"}) -[:IN_FAN] -> (i:CAT {name: "Hiiro"}) -[:WORK_FOR]-> (m:MOUSE {name: "ChenRay"});
注意:在 Cypher 中,节点之间的关系在创建后不能修改,想要修改只能删除原有关系再重新创建新的关系。
RETURN
RETURN 语句可以返回 Cypher 的执行结果。
比如,我们创建完节点后直接返回:
CREATE (n:DOG {name: "LYS", age: "14"}) RETURN n;
也可以返回我们创建好的关系:
CREATE (n:DOG {name: "LYS", age: "14"}) -[:IN_FAN]-> (m:CAT {name: "Hiiro", age: "17"}) RETURN n, m;
也可以给返回的结果取别名:
CREATE (n:DOG {name: "LYS", age: "14"})
RETURN n.name AS LYS_NAME;
更多关于 RETURN 的用法将在下文陆续提到。
MATCH
首先我们导入一些数据用于后面的示例:
MATCH(n) DETACH DELETE n;
CREATE(n:DOG {name: "LYS", age: 14}) -[:LOVER]-> (:BIRD {name: "Astesia", age: 13}) -[:FRIEND]-> (m:CAT {name: "Hiiro", age: 17}), (n) -[:FAN_OF]-> (m), (c:MOUSE {name: "ChenRay", age: 114}) -[:LOVER]-> (:DOG {name: "LexBurner", age: 514}), (c) -[:FAN_OF]-> (m), (n) -[:WORK_FOR]-> (p:PLANTFROM {name: "BILIBILI"}) -[:HAVE]-> (:DOG {name: "UPs", age: 1919}), (p) -[:BELONGS_to]-> (c);
CREATE(:WORKER:DOG {name: "打工人", age: 60}) -[:WORK_FOR]-> (:BOSS:DOG {name: "老板", age: 20}), (:DOG {name: "黑心老板", age: 0}), (:DOG {name: "黑心老板", age: 1}), (:DOG {name: "伤心打工人", age: 520}), (:DOG {name: "快乐打工人", age: 520}) -[:WORK_FOR]-> (:DOG {name: "良心老板", age: 1314});
条件查询
查询所有的节点及其关系:
MATCH(n)
RETURN n;
根据标签查询节点,例如查询所有标签包含 DOG 的节点::
MATCH(n: DOG)
RETURN n;
我们在上面提到过关系的创建,现在我们可以通过 MATCH 和 CREATE 查询节点并创建关系了:
MATCH(n:CAT) , (m:PLANTFROM)
CREATE (n) -[:WORK_FOR]-> (m)
RETURN n, m;
使用上述语句创建关系时,必须注意查询结果集的大小,若存在多个符合条件的节点,则会对结果集中所有的节点创建对应关系。
查询所有与某节点有关系的节点:
MATCH (n:CAT {name: "Hiiro"})--(m)
RETURN n, m;
根据关系查询,例如查询关系为 WORK_FOR 的节点:
MATCH (n)--(WORK_FOR)
RETURN n;
-- 并没有指定方向,如需指定使用 --> 或 <--:
MATCH (n)-->(WORK_FOR)
RETURN n;
MATCH (n)<--(WORK_FOR)
RETURN n;
查询两个节点的关系:
MATCH(n:DOG {name:"打工人"}) -[r]-> (m:DOG {name: "老板"})
RETURN type(r);
关系深度查询
六度分隔(Six Degrees of Separation)理论。
1967年,哈佛大学的心理学教授Stanley Milgram(1933~1984)想要描绘一个连结人与社区的人际连系网。做过一次连锁信实验,结果发现了“六度分隔”现象。简单地说:“你和任何一个陌生人之间所间隔的人不会超过六个,也就是说,最多通过六个人你就能够认识任何一个陌生人。”
由于一个节点可能存在多个关系,如果想要查询一条关系路径,未免包含太多的可行路径,因此需要在指定的深度内进行查询,这个查询的过程类似于迭代加深搜索的过程。
在图数据库中进行关系深度查询时,可以使用 * 运算符来指定关系的深度:
MATCH (startNode)-[*<minDepth>..<maxDepth>]-(endNode)
RETURN startNode, endNode;
其中:
-
(startNode)和(endNode)是节点模式,用于指定起始节点和结束节点。 -
[*<minDepth>..<maxDepth>]是关系模式,用于指定关系的深度范围。<minDepth>表示最小深度,<maxDepth>表示最大深度。可以根据需要省略其中一个值,或者两个值都省略。- 如果只指定
<minDepth>,则表示最小深度为该值,而没有最大深度限制。 - 如果只指定
<maxDepth>,则表示最大深度为该值,而没有最小深度限制。 - 如果同时指定
<minDepth>和<maxDepth>,则表示深度范围在最小深度和最大深度之间(包括最小深度和最大深度)。
- 如果只指定
例如,查询从某个节点出发,关系深度为 1 ∼ 2 1 \sim 2 1∼2 的节点:
MATCH (n:CAT {name:"Hiiro"}) -[*1..2]->(m)
RETURN *;
也可以写成:
MATCH (n:CAT {name:"Hiiro"}) -[*..2]->(m)
RETURN *;
查询两个节点之间的所有路径,指定深度最大为 4 4 4 :
MATCH path = (n:DOG) -[*..4]->(m:MOUSE)
WHERE n.name = "LYS" AND m.name = "ChenRay"
RETURN path;
查询两个节点之间的最短路径,指定深度最大为 6 6 6 :
MATCH path = shortestPath((n:DOG) -[*..6]->(m:MOUSE))
WHERE n.name = "LYS" AND m.name = "ChenRay"
RETURN path;
分页查询
使用 SKIP 和 LIMIT 子句来指定要跳过的结果数量和要返回的结果数量:
MATCH (nodes)
RETURN nodes
SKIP <skipCount>
LIMIT <pageSize>;
其中:
-
(nodes)是节点模式或关系模式,用于指定要返回的节点或关系。 -
SKIP <skipCount>是用于指定要跳过的结果数量的子句。<skipCount>是要跳过的结果数量。 -
LIMIT <pageSize>是用于指定要返回的结果数量的子句。<pageSize>是要返回的结果数量。
通过适当设置 <skipCount> 和 <pageSize> 的值,可以实现分页查询。
例如分页查询标签为 DOG 的节点信息,按照年龄从小到大排序,每页
2
2
2 条数据:
获取第 1 1 1 页:
MATCH (n:DOG)
RETURN n
ORDER BY n.age ASC
SKIP 0 LIMIT 2;
获取第 2 2 2 页:
MATCH (n:DOG)
RETURN n
ORDER BY n.age ASC
SKIP 2 LIMIT 2;
SET & REMOVE
使用 SET 和 REMOVE 对节点进行标签、属性的更新。
更新节点的属性和标签,例如将标签为 DOG 且年龄小于
60
60
60 节点的标签更改为 BOSS 且年龄增加
10
10
10:
MATCH(n:DOG)
WHERE n.age <= 60
SET n:BOSS
SET n.age = n.age + 10
RETURN n;
添加多个标签:
MATCH(n:DOG)
WHERE n.name = "LYS"
SET n:DOG:JOKER:STUDENT
RETURN n;
添加新的属性:
MATCH(n:DOG)
WHERE n.name = "LYS"
SET n.school = "HAUE"
RETURN n;
一次性添加多个属性:
MATCH(n:DOG)
WHERE n.name = "LYS"
SET n += {status: "Learning", money: 0, emo: "?"}
RETURN n;
移除某个属性或标签:
MATCH(n:DOG)
WHERE n.name = "LYS"
REMOVE n.emo, n:JOKER
RETURN n;
移除多个属性或标签:
MATCH(n:DOG)
WHERE n.name = "LYS"
REMOVE n.status, n.money, n:BOSS:STUDENT
RETURN n;
DELETE
删除节点:
MATCH(n)
WHERE n.name = "伤心打工人" OR n.name = "黑心老板"
DELETE n;
MATCH(n)
WHERE n.name = "打工人"
DELETE n;
如果删除的节点具有关系,则无法删除,需要先删除对应关系后才能删除节点:
MATCH(n) -[r:WORK_FOR]-> (m)
WHERE n.name = "打工人"
DELETE r, m;
或者添加 DETACH 强制删除该节点及其对应关系:
MATCH (n:DOG {name: "快乐打工人"})
DETACH DELETE n;
删除所有节点及其关系:
MATCH(n)
DETACH DELETE n;
索引
Neo4j 中同样支持索引,创建索引,以提高在大型数据集上对节点和关系进行查找和匹配的速度。
Neo4j 索引的底层实现原理主要依赖于两个核心组件:标签扫描器(Label Scanner)和属性索引(Property Index):
- 标签扫描器(Label Scanner):
- 使用标签扫描器来快速定位具有特定标签的节点。
- 标签扫描器维护了一个映射表,其中的每个条目都包含一个标签和指向具有该标签的节点的指针列表。当执行针对特定标签的查询时,标签扫描器可以快速定位到相关节点的位置。
- 标签扫描器允许在节点创建和删除时进行高效的更新,以保持索引的实时性。
- 属性索引(Property Index):
- 属性索引是基于节点和关系属性的值构建的数据结构,用于快速查找具有特定属性值的节点或关系。
- 使用
B+树作为属性索引的底层数据结构。树中的每个节点都包含多个键值对,其中键是属性的值,值是指向具有该属性值的节点或关系的指针。 - 在执行带有属性条件的查询时,属性索引可以通过在
B+树上进行范围搜索或精确查找来快速定位到满足条件的节点或关系。
此外,Neo4j 还提供了全文索引(Full-Text Index)和空间索引(Spatial Index)等特定类型的索引,用于支持全文搜索和地理空间查询。这些特定类型的索引也有其特定的底层实现,这里不再做深究。
创建索引
对节点属性创建索引:
CREATE INDEX ON :Label(property)
这将在具有特定标签(Label)的节点上创建一个属性(property)的索引。
对关系属性创建索引:
CREATE INDEX ON :RELATIONSHIP_TYPE(property)
这将在具有特定关系类型(RELATIONSHIP_TYPE)的关系上创建一个属性(property)的索引。
索引查询
对节点属性使用索引:
MATCH (n:Label)
WHERE n.property = value
RETURN n
这将使用节点属性的索引来查找具有特定属性值的节点。
对关系属性使用索引:
MATCH ()-[r:RELATIONSHIP_TYPE]-()
WHERE r.property = value
RETURN r
这将使用关系属性的索引来查找具有特定属性值的关系。
删除索引
使用 DROP INDEX 删除索引,例如:文章来源:https://uudwc.com/A/R62wp
DROP INDEX ON :Label(property)
这将删除特定标签(Label)上的属性(property)索引。文章来源地址https://uudwc.com/A/R62wp
官方文档参考
- Neo4j 4.4 安装
- Cypher Manual 4.4