⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️
?作者:秋无之地?简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。
?欢迎小伙伴们点赞??、收藏⭐️、留言?、关注?,关注必回关
上一篇文章已经跟大家介绍过《Python爬虫:如何下载懂车帝的电动车数据(完整代码)》,相信大家对python爬虫都有一个基本的认识。下面我讲一下:数据清洗:数据挖掘的前期准备工作。
文章来源:https://uudwc.com/A/R6ek8
一、数据清洗重要性
上一节中讲了python爬虫采集数据,但做完数据采集就可以直接进行挖掘了吗?肯定不是的。
1、什么是数据清洗
就拿做饭打个比方吧,对于很多人来说,热油下锅、掌勺翻炒一定是做饭中最过瘾的环节,但实际上炒菜这个过程只占做饭时间的 20%,剩下 80% 的时间都是在做准备,比如买菜、择菜、洗菜等等。

在数据挖掘中,数据清洗就是这样的前期准备工作。对于数据科学家来说,我们会遇到各种各样的数据,在分析前,要投入大量的时间和精力把数据“整理裁剪”成自己想要或需要的样子。
说白了,数据清洗就是将源数据整理成自己想要或需要的样子。
2、为什么要数据清洗
继续用上面做饭的例子,我们买回来的菜,不是马上就下锅煮,是不是要清洗一下,菜叶可能残留农药是不是需要浸泡一下,葱花有些变黄干枯的是不是需要摘掉等等。我们采集回来的数据同样存在这些问题。
下面举个例子,假设老板给你以下的数据,让你做数据分析,你看到这个数据后有什么感觉呢?
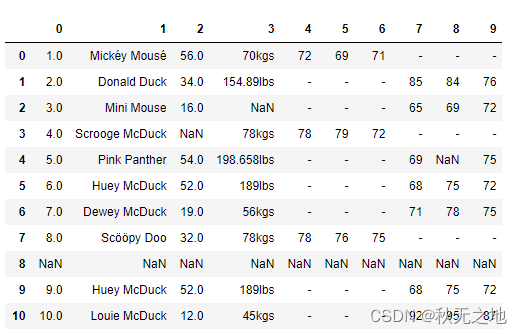
你刚看到这些数据可能会比较懵,因为这些数据缺少标注。
我们在收集整理数据的时候,一定要对数据做标注,数据表头很重要。比如这份数据表,就缺少列名的标注,这样一来我们就不知道每列数据所代表的含义,无法从业务中理解这些数值的作用,以及这些数值是否正确。但在实际工作中,也可能像这个案例一样,数据是缺少标注的。
我简单解释下这些数据代表的含义。
这是一家服装店统计的会员数据。最上面的一行是列坐标,最左侧一列是行坐标。
列坐标中,第 0 列代表的是序号,第 1 列代表的会员的姓名,第 2 列代表年龄,第 3 列代表体重,第 4~6 列代表男性会员的三围尺寸,第 7~9 列代表女性会员的三围尺寸。
了解含义以后,我们再看下中间部分具体的数据,你可能会想,这些数据怎么这么“脏乱差”啊,有很多值是空的(NaN),还有空行的情况。
是的,这还仅仅是一家商店的部分会员数据,我们一眼看过去就能发现一些问题。日常工作中的数据业务会复杂很多,通常我们要统计更多的数据维度,比如 100 个指标,数据量通常都是超过 TB、EB 级别的,所以整个数据分析的处理难度是呈指数级增加的。这个时候,仅仅通过肉眼就很难找到问题所在了。
我举了这样一个简单的例子,带你理解在数据分析之前为什么要有数据清洗这个重要的准备工作。有经验的数据分析师都知道,好的数据分析师必定是一名数据清洗高手,要知道在整个数据分析过程中,不论是在时间还是功夫上,数据清洗大概都占到了 80%。
二、数据质量的准则
在上面这个服装店会员数据的案例中,一看到这些数据,你肯定能发现几个问题。你是不是想知道,有没有一些准则来规范这些数据的质量呢?
准则肯定是有的。不过如果数据存在七八种甚至更多的问题,我们很难将这些规则都记住。有研究说一个人的短期记忆,最多可以记住 7 条内容或信息,超过 7 条就记不住了。而数据清洗要解决的问题,远不止 7 条,我们万一漏掉一项该怎么办呢?有没有一种方法,我们既可以很方便地记住,又能保证我们的数据得到很好的清洗,提升数据质量呢?
在这里,我将数据清洗规则总结为以下 4 个关键点,统一起来叫“完全合一”,下面我来解释下。
- 完整性:单条数据是否存在空值,统计的字段是否完善。
- 全面性:观察某一列的全部数值,比如在 Excel 表中,我们选中一列,可以看到该列的平均值、最大值、最小值。我们可以通过常识来判断该列是否有问题,比如:数据定义、单位标识、数值本身。
- 合法性:数据的类型、内容、大小的合法性。比如数据中存在非 ASCII 字符,性别存在了未知,年龄超过了 150 岁等。
- 唯一性:数据是否存在重复记录,因为数据通常来自不同渠道的汇总,重复的情况是常见的。行数据、列数据都需要是唯一的,比如一个人不能重复记录多次,且一个人的体重也不能在列指标中重复记录多次。
在很多数据挖掘的教学中,数据准则通常会列出来 7~8 项,在这里我们归类成了“完全合一”4 项准则,按照以上的原则,我们能解决数据清理中遇到的大部分问题,使得数据标准、干净、连续,为后续数据统计、数据挖掘做好准备。如果想要进一步优化数据质量,还需要在实际案例中灵活使用。
了解了数据质量准则之后,我们针对上面服装店会员数据案例中的问题进行一一击破。
1、完整性
问题 1:缺失值
在数据中有些年龄、体重数值是缺失的,这往往是因为数据量较大,在过程中,有些数值没有采集到。通常我们可以采用以下三种方法:
- 删除:删除数据缺失的记录;
- 均值:使用当前列的均值;
- 高频:使用当前列出现频率最高的数据。
比如我们想对 df[‘Age’]中缺失的数值用平均年龄进行填充,可以这样写:
df['Age'].fillna(df['Age'].mean(), inplace=True)如果我们用最高频的数据进行填充,可以先通过 value_counts 获取 Age 字段最高频次 age_maxf,然后再对 Age 字段中缺失的数据用 age_maxf 进行填充:
age_maxf = train_features['Age'].value_counts().index[0]
train_features['Age'].fillna(age_maxf, inplace=True)问题 2:空行
我们发现数据中有一个空行,除了 index 之外,全部的值都是 NaN。Pandas 的 read_csv() 并没有可选参数来忽略空行,这样,我们就需要在数据被读入之后再使用 dropna() 进行处理,删除空行。
# 删除全空的行
df.dropna(how='all',inplace=True) 2、全面性
问题:列数据的单位不统一
观察 weight 列的数值,我们能发现 weight 列的单位不统一。有的单位是千克(kgs),有的单位是磅(lbs)。
这里我使用千克作为统一的度量单位,将磅(lbs)转化为千克(kgs):
# 获取 weight 数据列中单位为 lbs 的数据
rows_with_lbs = df['weight'].str.contains('lbs').fillna(False)
# 将 lbs转换为 kgs, 2.2lbs=1kgs
for i,lbs_row in df[rows_with_lbs].iterrows():
# 截取从头开始到倒数第三个字符之前,即去掉lbs。
weight = int(float(lbs_row['weight'][:-3])/2.2)
df.at[i,'weight'] = '{}kgs'.format(weight) 3、合理性
问题:非 ASCII 字符
我们可以看到在数据集中 Firstname 和 Lastname 有一些非 ASCII 的字符。我们可以采用删除或者替换的方式来解决非 ASCII 问题,这里我们使用删除方法:
# 删除非 ASCII 字符
df['first_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
df['last_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)4、唯一性
问题 1:一列有多个参数
在数据中不难发现,姓名列(Name)包含了两个参数 Firstname 和 Lastname。为了达到数据整洁目的,我们将 Name 列拆分成 Firstname 和 Lastname 两个字段。我们使用 Python 的 split 方法,str.split(expand=True),将列表拆成新的列,再将原来的 Name 列删除。
# 切分名字,删除源数据列
df[['first_name','last_name']] = df['name'].str.split(expand=True)
df.drop('name', axis=1, inplace=True)问题 2:重复数据
我们校验一下数据中是否存在重复记录。如果存在重复记录,就使用 Pandas 提供的 drop_duplicates() 来删除重复数据。
# 删除重复数据行
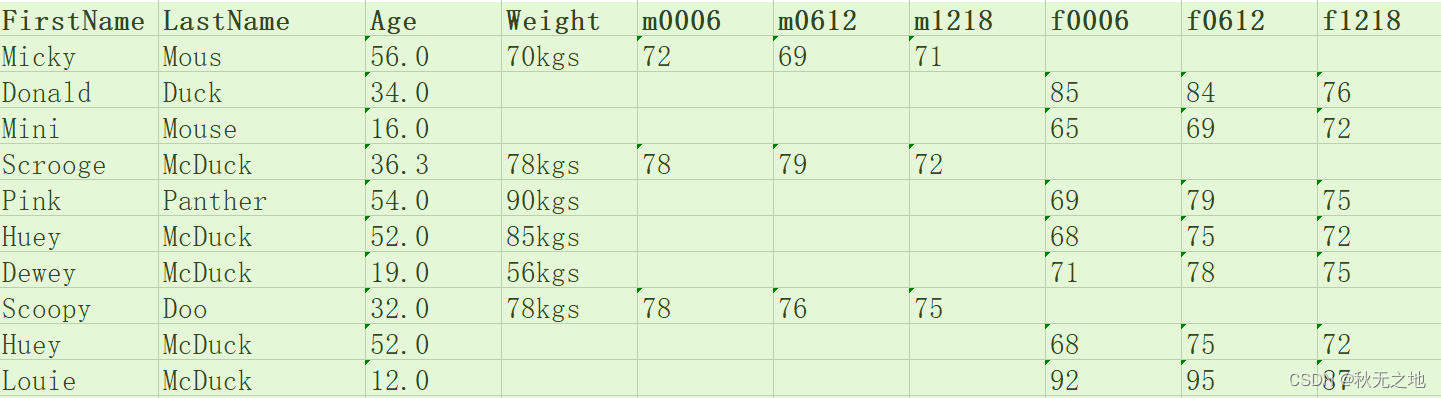
df.drop_duplicates(['first_name','last_name'],inplace=True)这样,我们就将上面案例中的会员数据进行了清理,来看看清理之后的数据结果。怎么样?是不是又干净又标准?
三、养成数据审核的习惯
现在,你是不是能感受到数据问题不是小事,上面这个简单的例子里都有 6 处错误。所以我们常说,现实世界的数据是“肮脏的”,需要清洗。
第三方的数据要清洗,自有产品的数据,也需要数据清洗。比如美团自身做数据挖掘的时候,也需要去除爬虫抓取,作弊数据等。可以说没有高质量的数据,就没有高质量的数据挖掘,而数据清洗是高质量数据的一道保障。
当你从事这方面工作的时候,你会发现养成数据审核的习惯非常重要。而且越是优秀的数据挖掘人员,越会有“数据审核”的“职业病”。这就好比编辑非常在意文章中的错别字、语法一样。
数据的规范性,就像是你的作品一样,通过清洗之后,会变得非常干净、标准。当然了,这也是一门需要不断修炼的功夫。终有一天,你会进入这样一种境界:看一眼数据,差不多 7 秒钟的时间,就能知道这个数据是否存在问题。为了这一眼的功力,我们要做很多练习。
刚开始接触数据科学工作的时候,一定会觉得数据挖掘是件很酷、很有价值的事。确实如此,不过今天我还要告诉你,再酷炫的事也离不开基础性的工作,就像我们今天讲的数据清洗工作。对于这些基础性的工作,我们需要耐下性子,一个坑一个坑地去解决。
四、总结
下面是数据清洗的总结:

版权声明
本文章版权归作者所有,未经作者允许禁止任何转载、采集,作者保留一切追究的权利。文章来源地址https://uudwc.com/A/R6ek8