kafka是一个分布式的,支持数据分区,多副本,基于zookeeper协调的分布式消息系统。
上个文章介绍了rabbitmq,他和kafaka的最大区别就是kafak是分布式的,并发处理能力强大。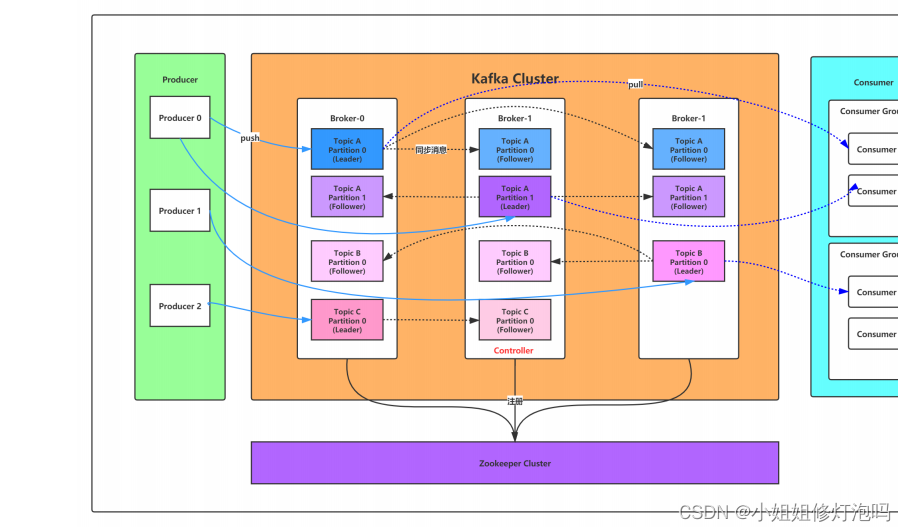
broker:消息中间处理节点,一个kafka节点就是一个broker,可以组成集群
produce:生产者,向broker发送消息的客户端
consumer:消费者,从broker读取消息
consumer group:消费组,每个consumer对应一个组,一条消息可以被多个消费组消费,但是每个消费组里面只能有一个消费者消费该消息(分区的话,每个分区只能被每个消费组里面的一个消费者消费)
topic:kafka根据消息进行分类,发布到kafka的每条消息都系要制定一个topic,可以理解为队列
partition:一个topic可以分为多个partition。分区的概念
一、kafak内部机制
1.消费者消息的offset记录机制:消费的消息不会立马删除默认保留一周(其他的产品会立刻清除)。每个consumer会定期将自己的消费分区的offset提交给kafka内部的topic记录自己消费的位置。
2.消费者rebalance机制:如果消费组里的消费者数量有变化或分区变化,kafak会重新分配消费者和分区的关系
线上问题及优化:
消息丢失: 文章来源:https://uudwc.com/A/Vern
文章来源:https://uudwc.com/A/Vern

2.消息重复发送
消费发送端:生产者幂等性,开启enable,idempoteence ,true.。每次发送消息会生成PID和sequence number,broker会检查是否存在,存在就不再接受
 文章来源地址https://uudwc.com/A/Vern
文章来源地址https://uudwc.com/A/Vern
