前言
本文主要用于记录我在使用python做图像识别语义分割训练集的过程,由于在这一过程中踩坑排除BUG过多,因此也希望想做这部分内容的同学们可以少走些弯路。
本文是python语义分割与街景识别第三篇,关于数据集准备的内容。
一、自己制作数据集
自己做数据集的方法其实非常简单,可以使用labelme软件,将每张图片手动框选并填色标记,这里不使用这种方法,因为在建筑或城市尺度下的训练集数量需要很大才可以达到不错的精度,一般不会自行准备数据集,故省略,可以自行寻找labelme教程
二、使用现有数据集训练
2.1 数据集选择
这里使用的是cityscapes已经标注好的训练集,训练集就是一堆精确到像素按分类人工填色标记的图片集
Cityscapes Dataset – Semantic Understanding of Urban Street Scenes
选择“download”注册账号(最好使用学校教务邮箱)并下载相应数据集,笔者下载了前三个数据集
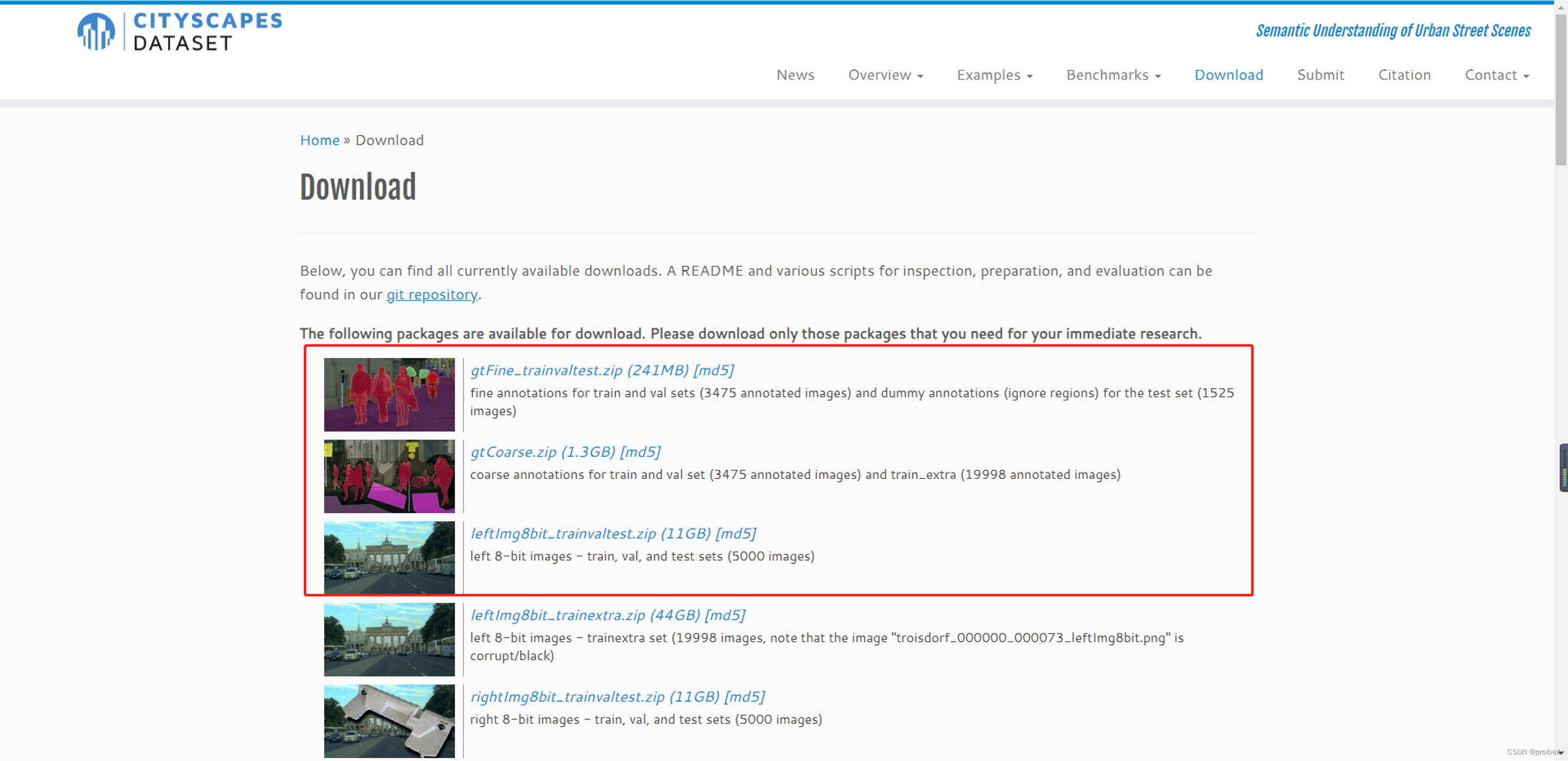
2.2 下载官方处理脚本
地址:https://github.com/mcordts/cityscapesScripts
将2.1中的图片集放在cityscapesScripts文件夹下待后续操作
这里对下载下来的数据集做简单说明:以gtCourse为例,里面有这三个文件夹(不同数据集有可能不太一样)

第一个文件夹中的图片用于训练,第二个文件夹用于额外训练(有些数据集这个文件夹是test),第三个文件夹中图片用于验证(validation)
打开第一个train文件夹,里面都是不同城市的名字文件夹,比如第一个是亚琛

里面是一堆这样的文件

填过色的图片和一个对应的json文件。json文件中有标记和像素信息,要训练的本质是这堆信息,填色图片只是最后呈现给人看的结果
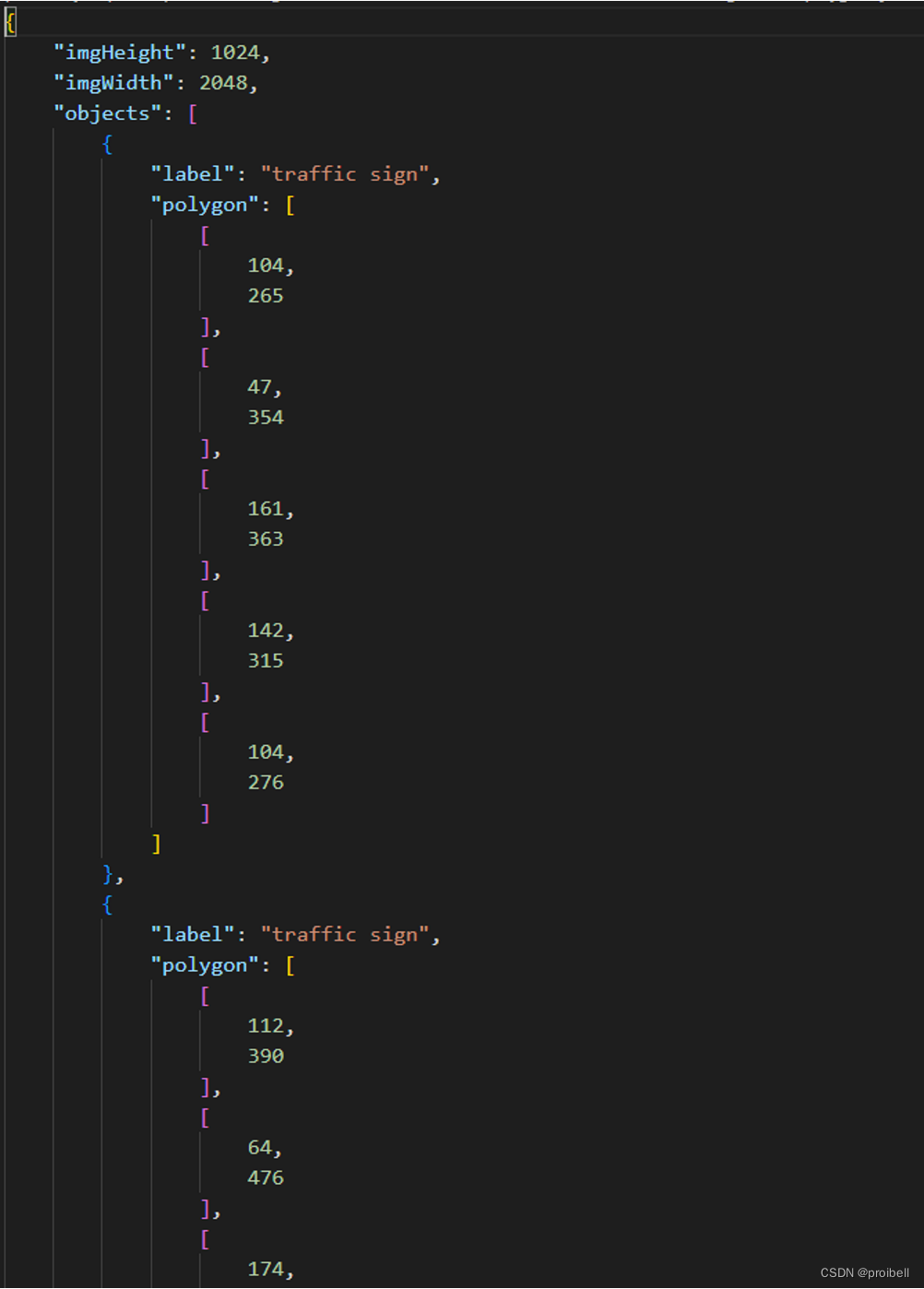
2.3 准备数据集
新建一个文件夹名为dataset,将其准备为下面的样子
 文章来源:https://uudwc.com/A/W1o0R
文章来源:https://uudwc.com/A/W1o0R
annotations中放入填好色的图片,images中放入对应的原图,perdict中放入需要测试的其他街道图片 文章来源地址https://uudwc.com/A/W1o0R