1、Zookeeper特性与节点数据类型详解
ZooKeeper 是一个开源的分布式协调框架,是Apache Hadoop 的一个子项目,主要用来解决分布式集群中应用系统的一致性问题。
Zookeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。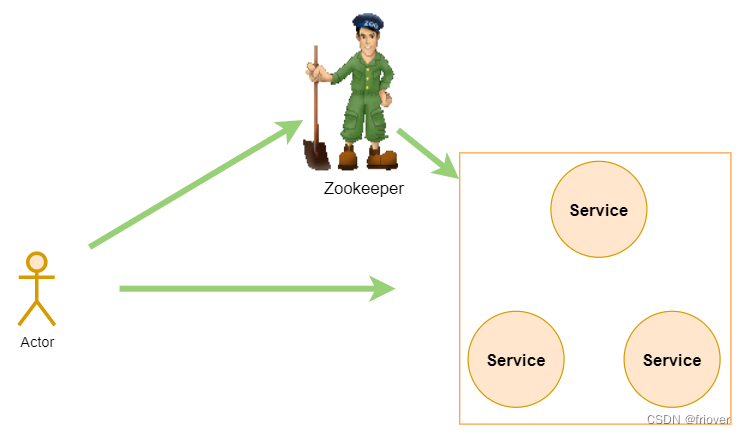
ZooKeeper本质上是一个分布式的小文件存储系统(Zookeeper=文件系统+监听机制)。提供基于类似于文件系统的目录树方式的数据存储,并且可以对树中的节点进行有效管理,从而用来维护和监控存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理、统一命名服务、分布式配置管理、分布式消息队列、分布式锁、分布式协调等功能。
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper 就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
2、. Zookeeper快速开始

1)修改配置文件
解压安装包后进入conf目录,复制zoo_sample.cfg,修改为zoo.cfg
zoo.cfg中参数含义:
2)启动zookeeper server
可以通过 bin/zkServer.sh 来查看都支持哪些参数 默认加载配置路径conf/zoo.cfg bin/zkServer.sh
start bin/zkServer.sh start conf/my_zoo.cfg
查看zookeeper状态 bin/zkServer.sh status
3)启动zookeeper client连接Zookeeper server
bin/zkCli.sh
连接远程的zookeeper server
bin/zkCli.sh -server ip:port
2.2 客户端命令行操作
Zookeeper图形化工具:开源的prettyZoo
https://github.com/vran-dev/PrettyZoo/releases
3. ZooKeeper数据结构
ZooKeeper 数据模型的结构与 Unix 文件系统很类似,整体上可以看作是一棵树,每个节点称做一个 ZNode。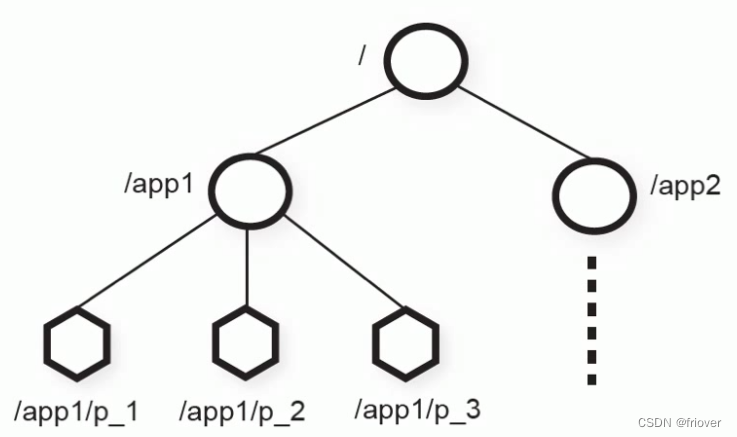
ZooKeeper的数据模型是层次模型,层次模型常见于文件系统。层次模型和key-value模型是两种主流的数据模型。ZooKeeper使用文件系统模型主要基于以下两点考虑:
文件系统的树形结构便于表达数据之间的层次关系
文件系统的树形结构便于为不同的应用分配独立的命名空间(namespace )
ZooKeeper的层次模型称作Data Tree,Data Tree的每个节点叫作Znode。不同于文件系统,每个节点都可以保存数据,每一个 ZNode 默认能够存储 1MB 的数据,每个 ZNode 都可以通过其路径唯一标识,每个节点都有一个版本(version),版本从0开始计数。
3.1 节点分类
zookeeper存在几种不同的节点类型,他们具有不同的生命周期:
类型 生命周期 创建示例
持久节点 (persistent node)
一直存在,一直存储在ZooKeeper 服务器上,即使创建该节点的客户端与服务端的会话关闭了,该节点依然不会被删除
create /locks
临时节点 (ephemeral node)
当创建该临时节点的客户端会话因超时或发生异常而关闭时,该节点也相应在 ZooKeeper 服务器上被删除。
create -e /locks/DBLock
有序节点 (sequential node)
并不算是一种单独种类的节点,而是在之前提到的持久节点和临时节点特性的基础上,增加了一个节点有序的性质。在我们创建有序节点的时候会自动使用一个单调递增的数字作为后缀
create -e -s /jobs/job (临时有序节点)
容器节点 (container node)
当一个容器节点的最后一个子节点被删除后,容器节点也会被删除
create -c /work
TTL节点 (ttl node)
当一个TTL节点在 TTL 内没有被修改并且没有子节点,会被删除。注意:默认此功能不开启,需要修改配置文件extendedTypesEnabled=true
create -t 3000 /ttl_node
一个znode可以使持久性的,也可以是临时性的:
- 持久节点(PERSISTENT): 这样的znode在创建之后即使发生ZooKeeper集群宕机或者client宕机也不会丢失。
- 临时节点(EPHEMERAL ): client宕机或者client在指定的timeout时间内没有给ZooKeeper集群发消息,这样的znode就会消失。
如果上面两种znode具备顺序性,又有以下两种znode : - 持久顺序节点(PERSISTENT_SEQUENTIAL): znode除了具备持久性znode的特点之外,znode的名字具备顺序性。
- 临时顺序节点(EPHEMERAL_SEQUENTIAL): znode除了具备临时性znode的特点之外,zorde的名字具备顺序性。
- Container节点 (3.5.3版本新增):Container容器节点,当容器中没有任何子节点,该容器节点会被zk定期删除(定时任务默认60s 检查一次)。 和持久节点的区别是 ZK 服务端启动后,会有一个单独的线程去扫描,所有的容器节点,当发现容器节点的子节点数量为 0 时,会自动删除该节点。可以用于 leader 或者锁的场景中。
- TTL节点: 带过期时间节点,默认禁用,需要在zoo.cfg中添加 extendedTypesEnabled=true 开启。 注意:TTL不能用于临时节点
示例:实现分布式锁
分布式锁要求如果锁的持有者宕了,锁可以被释放。ZooKeeper 的 ephemeral 节点恰好具备这样的特性。
节点状态信息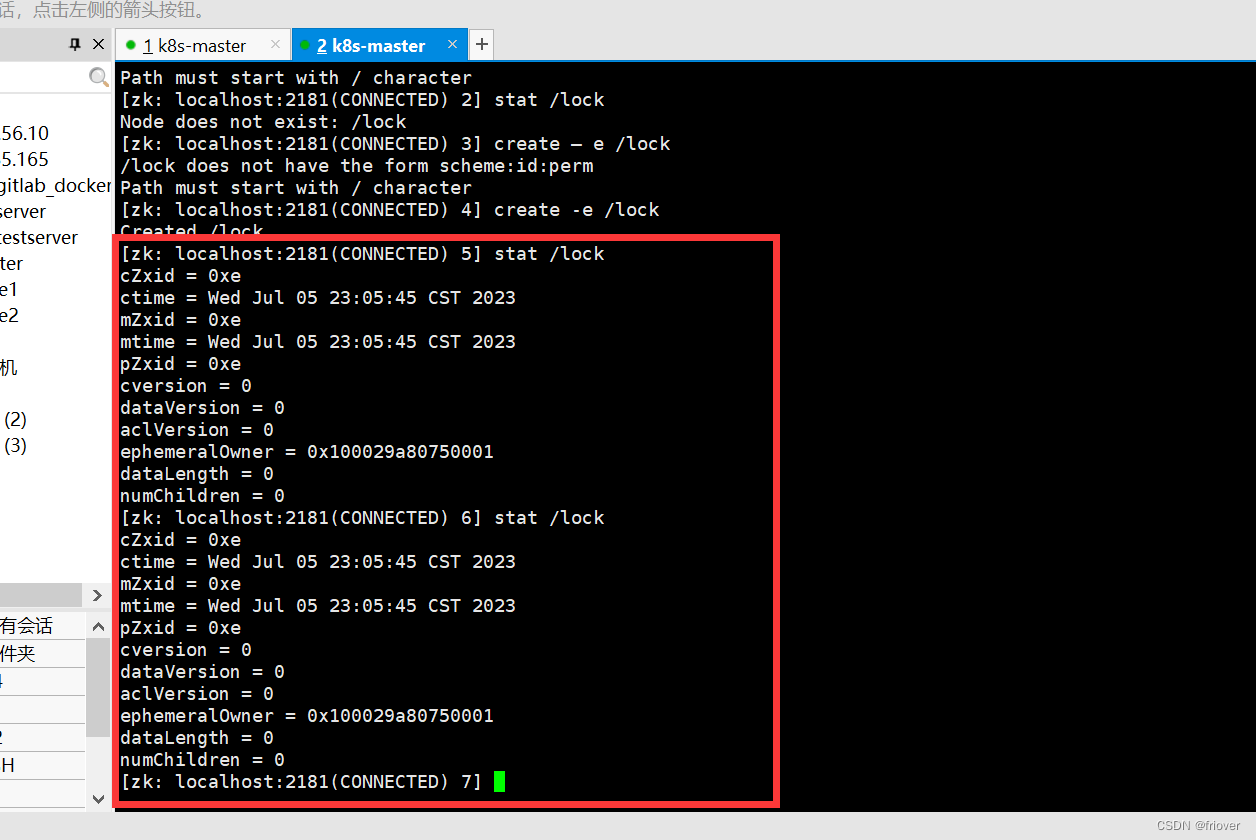
-
cZxid :Znode创建的事务id。
-
ctime:节点创建时的时间戳。
-
mZxid: Znode被修改的事务id,即每次对znode的修改都会更新mZxid。
对于zk来说,每次的变化都会产生一个唯一的事务id,zxid(ZooKeeper Transaction Id),通过zxid,可以确定更新操作的先后顺序。例如,如果zxid1小于zxid2,说明zxid1操作先于zxid2发生,zxid对于整个zk都是唯一的,即使操作的是不同的znode。 -
pZxid:
表示该节点的子节点列表最后一次修改的事务ID,添加子节点或删除子节点就会影响子节点列表,但是修改子节点的数据内容则不影响该ID(注意:
只有子节点列表变更了才会变更pzxid,子节点内容变更不会影响pzxid -
mtime:节点最新一次更新发生时的时间戳.
-
cversion :子节点的版本号。当znode的子节点有变化时,cversion 的值就会增加1。
-
dataVersion:数据版本号,每次对节点进行set操作,dataVersion的值都会增加1(即使设置的是相同的数据),可有效避免了数据更新时出现的先后顺序问题。
-
ephemeralOwner:如果该节点为临时节点, ephemeralOwner值表示与该节点绑定的session id。如果不是, ephemeralOwner值为0(持久节点)。
在client和server通信之前,首先需要建立连接,该连接称为session。连接建立后,如果发生连接超时、授权失败,或者显式关闭连接,连接便处于closed状态, 此时session结束。
3.2 监听机制详解
watch机制,顾名思义是一个监听机制。Zookeeper中的watch机制,必须客户端先去服务端注册监听,这样事件发送才会触发监听,通知给客户端。
监听的对象是事件,支持的事件类型如下:
None: 连接建立事件
NodeCreated: 节点创建
NodeDeleted: 节点删除
NodeDataChanged:节点数据变化
NodeChildrenChanged:子节点列表变化
DataWatchRemoved:节点监听被移除
ChildWatchRemoved:子节点监听被移除
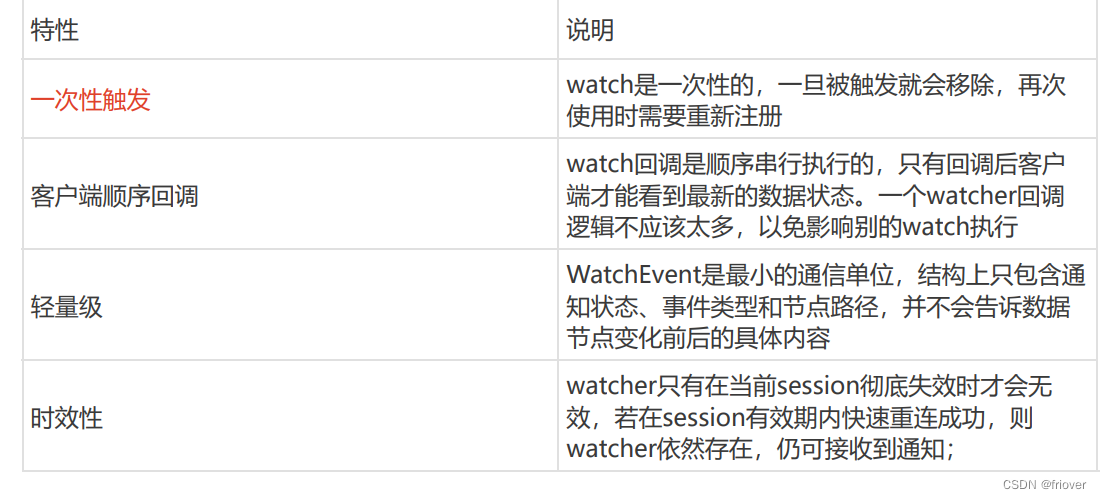
永久性Watch
在被触发之后,仍然保留,可以继续监听ZNode上的变更,是Zookeeper 3.6.0版本新增的功能
addWatch [-m mode] path
addWatch的作用是针对指定节点添加事件监听,支持两种模式
PERSISTENT,持久化订阅,针对当前节点的修改和删除事件,以及当前节点的子节点的删除和新增事件。
PERSISTENT_RECURSIVE,持久化递归订阅(默认),在PERSISTENT的基础上,增加了子节点修改的事件触发,以及子节点的子节点的数据变化都会触发相关事件(满足递归订阅特性)文章来源:https://uudwc.com/A/XNYRr
3.3 节点特性总结
- 同一级节点 key 名称是唯一的 已存在/lock节点,再次创建会提示已经存在
- 创建节点时,必须要带上全路径
- session 关闭,临时节点清除
- 自动创建顺序节点
- watch 机制,监听节点变化
事件监听机制类似于观察者模式,watch 流程是客户端向服务端某个节点路径上注册一个 watcher,同时客户端也会存储特定的 watcher,当节点数据或子节点发生变化时,服务端通知客户端,客户端进行回调处理。特别注意:监听事件被单次触发后,事件就失效了。 - delete 命令只能一层一层删除。提示:新版本可以通过 deleteall 命令递归删除。
3.4 应用场景详解
ZooKeeper适用于存储和协同相关的关键数据,不适合用于大数据量存储。
有了上述众多节点特性,使得 zookeeper 能开发不出不同的经典应用场景,比如:
注册中心
数据发布/订阅(常用于实现配置中心)
负载均衡
命名服务
分布式协调/通知
集群管理
Master选举
分布式锁
分布式队列文章来源地址https://uudwc.com/A/XNYRr