如果没有日志解析,搜索和可视化日志几乎是不可能的,一个被低估的技能记录器需要读取他们的数据。 解析结构化你的传入(非结构化)日志,以便用户可以在调查期间或设置仪表板时搜索清晰的字段和值。
最流行的日志解析语言是 Grok。 你可以使用 Grok 插件在各种日志管理和分析工具比如 Elastic Stack 中解析日志数据。 在这里查看我之前的的 Grok 教程。
但是用 Grok 解析日志可能会很棘手。 本博客将研究一些 Grok 模式示例,这些示例可以帮助您了解如何解析日志数据。
开始使用 Grok
让我们从一个示例非结构化日志消息开始,然后我们将使用 Grok 模式对其进行结构化:
128.39.24.23 - - [25/Dec/2021:12:16:50 +0000] "GET /category/electronics HTTP/1.1" 200 61 "/category/finance" "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)"
想象一下搜索数百万条看起来像这样的日志行! 看起来很可怕。 这就是为什么我们有像 Grok 这样的解析语言——让数据更易于阅读和搜索。
查看该数据并使用 Kibana 等分析工具进行搜索的一种更简单的方法是将其分解为具有值的字段,如下表所示:
1. ip:128.39.24.23
2. timestamp:25/Dec/2021:12:16:50 +0000
3. verb:GET
4. request:/category/electronics HTTP/1.1
5. status: 200
6. bytes: 61
7. referrer:/category/finance
8. os: Windows让我们使用一个示例 Grok 模式来生成这些字段。 以下部分将展示 Grok 模式语法以生成上述每个字段。
对于每个部分,我们的 Grok 模式都会扩展,因为它包含更多要解析的字段。 这些模式是 Grok 可以阅读的正则表达式——我们可以使用它们来表达我们的信息。
下面是一些有用的链接,可以帮助你开始使用一些 Grok 模式。 但我们将在博客的其余部分提供更多示例。
- Grok pattern
- Grok Debugger
在 Grok pattern 页面,我们可以找到我们需要的预定义好的 pattern:
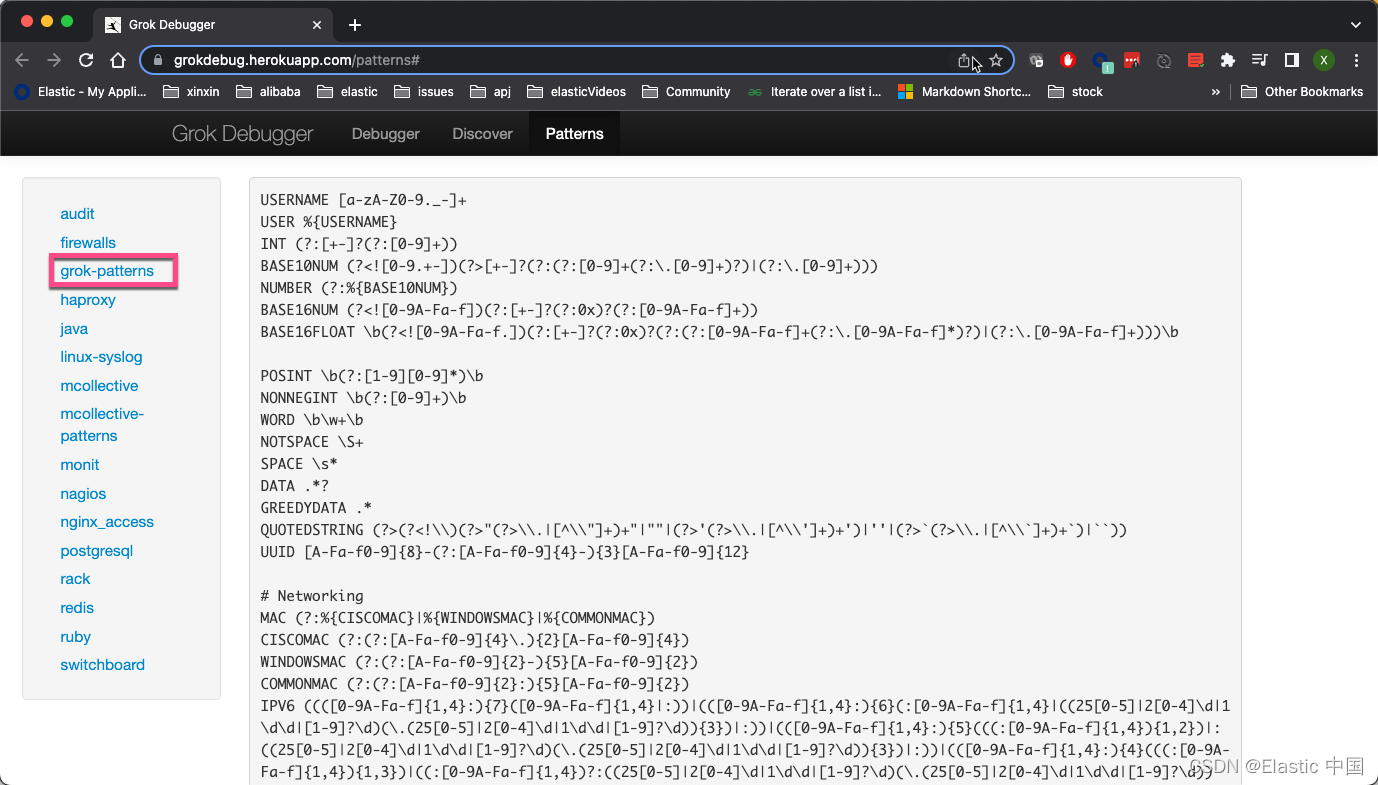
从某种意义上讲,这些 pattern 在本质上就是基于正则表达式的组合。你也可以创建自己定义的 pattern。这个在我的另外的文章有提到
- Logstash:如何使用 Logstash Grok 过滤器提取模式
-
Elastic:在 Grok 中运用 custom pattern 来定义 pattern
让我们开始构建 Grok 模式来结构化数据。
我们使用以下方式描述模式的开始: ^
语法如下: %{pattern:Name_of_the_field}
请注意:不建议使用空格来描述字段的名称。
提取 IP
假设我们要提取 IP,我们可以使用 IP 方法:
^%{IP:ip}然后我们有这些: – –
为了告诉 Grok 忽略它们,我们只需将它们添加到我们的模式中。
^%{IP:ip} - -这个模式给了我们这个字段:
ip:128.39.24.23为了测试方便,我们可以使用 Kibana 中所提供的 Grok debugger 来展示:
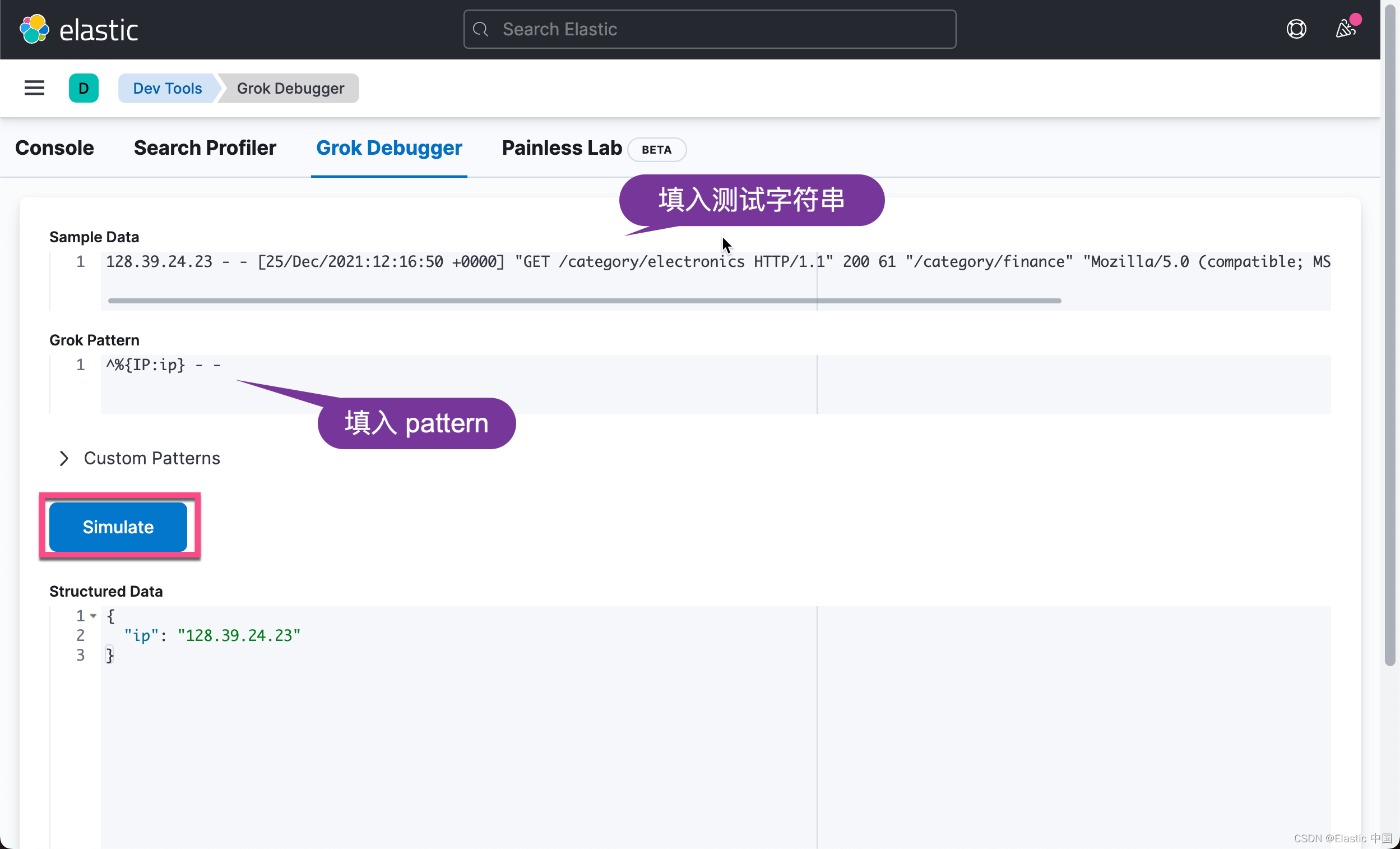
从上面的输出,我们可以看出来 ip 字段被解释。 上面所使用到的 IP pattern,你可以在地址进行查看:
提取 timestamps
在我们非结构化日志消息的下一部分中,我们将时间戳 “含” 在一个数组中:
[25/Dec/2021:12:16:50 +0000] 要提取它,我们需要使用正则表达式和 HTTPDATE 方法,同时在外面添加括号,以便 Grok 知道忽略它们:
\[%{HTTPDATE:timestamp}\]基于我们之前的模式,我们现在有:
^%{IP:ip} - - \[%{HTTPDATE:timestamp}\] 这给了我们:
"ip": "128.39.24.23",
"timestamp": "25/Dec/2021:12:16:50 +0000"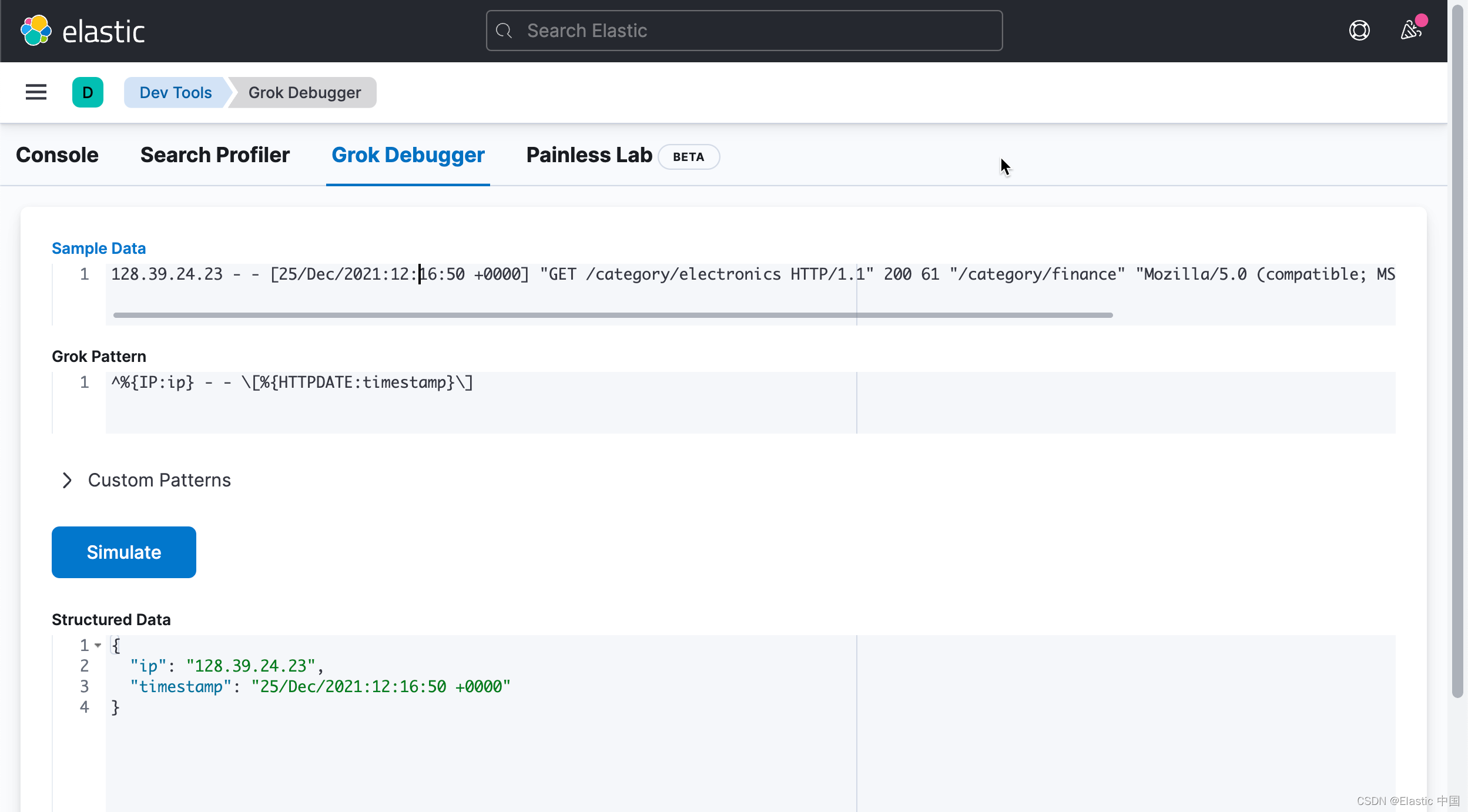
回到我们最初的非结构化消息,看起来我们有一个空间,时间戳结束,“GET 开始”。 我们还需要告诉 Grok 忽略空格。 为此,我们只需按键盘上的空格键,或者我们可以使用 %{SPACE} -> 直到 4 个空格。
提取 verbs
是时候提取 GET 字段了。 首先,我们需要告诉 Grok 忽略引号 - 然后使用 WORD 方法,我们将通过编写来做到这一点:
“%{WORD:verb}所以,现在我们的模式是:
^%{IP:ip} - - \[%{HTTPDATE:timestamp}\] "%{WORD:verb}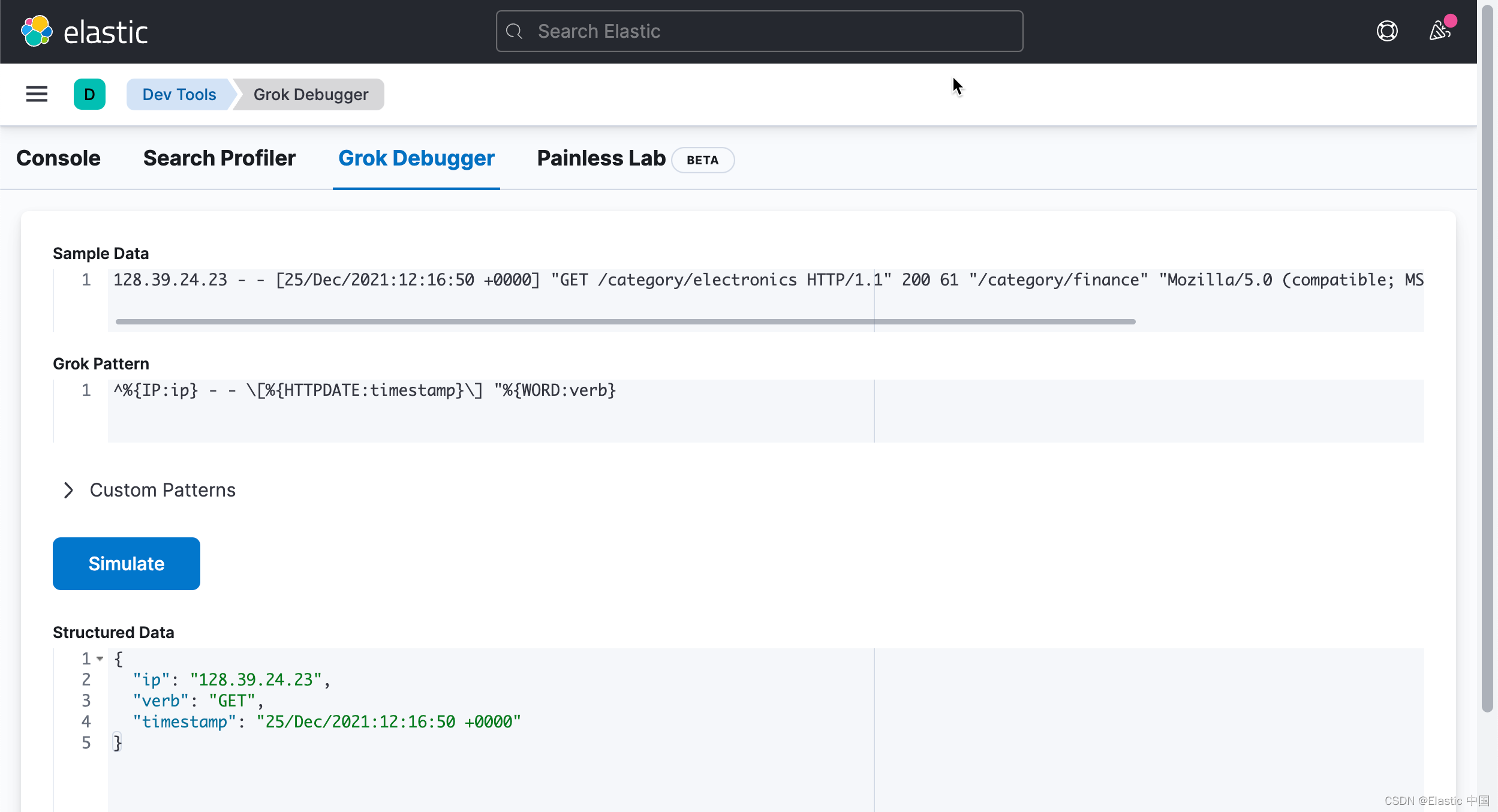
这给了我们这些字段:
"ip": "128.39.24.23",
"verb": "GET",
"timestamp": "25/Dec/2021:12:16:50 +0000"提取 request
为了提取请求 -> /category/electronics HTTP/1.1″,我们需要使用 DATA 方法,它本质上是正则表达式中的通配符。
这意味着我们需要添加一个句号来提取此信息,以告诉 DATA 方法在哪里停止——否则,它不会捕获任何数据。 我们可以使用引号作为停止标记:
%{DATA:request}"现在,我们有以下 Grok 模式:
^%{IP:ip} - - \[%{HTTPDATE:timestamp}\] "%{WORD:verb} %{DATA:request}"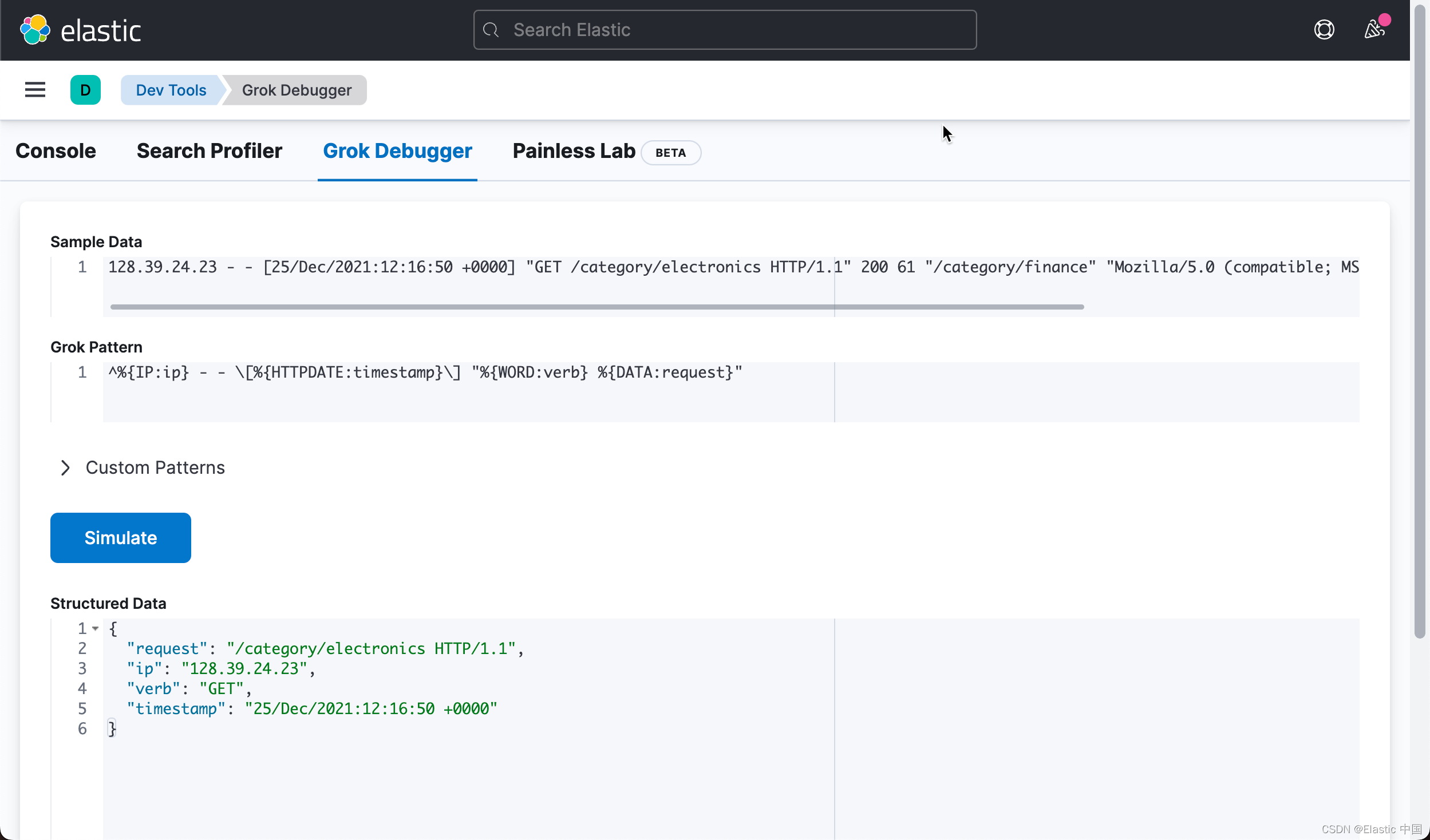
这给了我们这些字段:
"request": "/category/electronics HTTP/1.1",
"ip": "128.39.24.23",
"verb": "GET",
"timestamp": "25/Dec/2021:12:16:50 +0000"
提取 status
接下来是状态,但我们在请求结束和状态之间再次有一个空格,我们可以添加一个空格或 %{SPACE}。 为了提取数字,我们使用 NUMBER 方法。
%{NUMBER:status}现在我们的模式扩展到:
^%{IP:ip} - - \[%{HTTPDATE:timestamp}\] "%{WORD:verb} %{DATA:request}" %{NUMBER:status}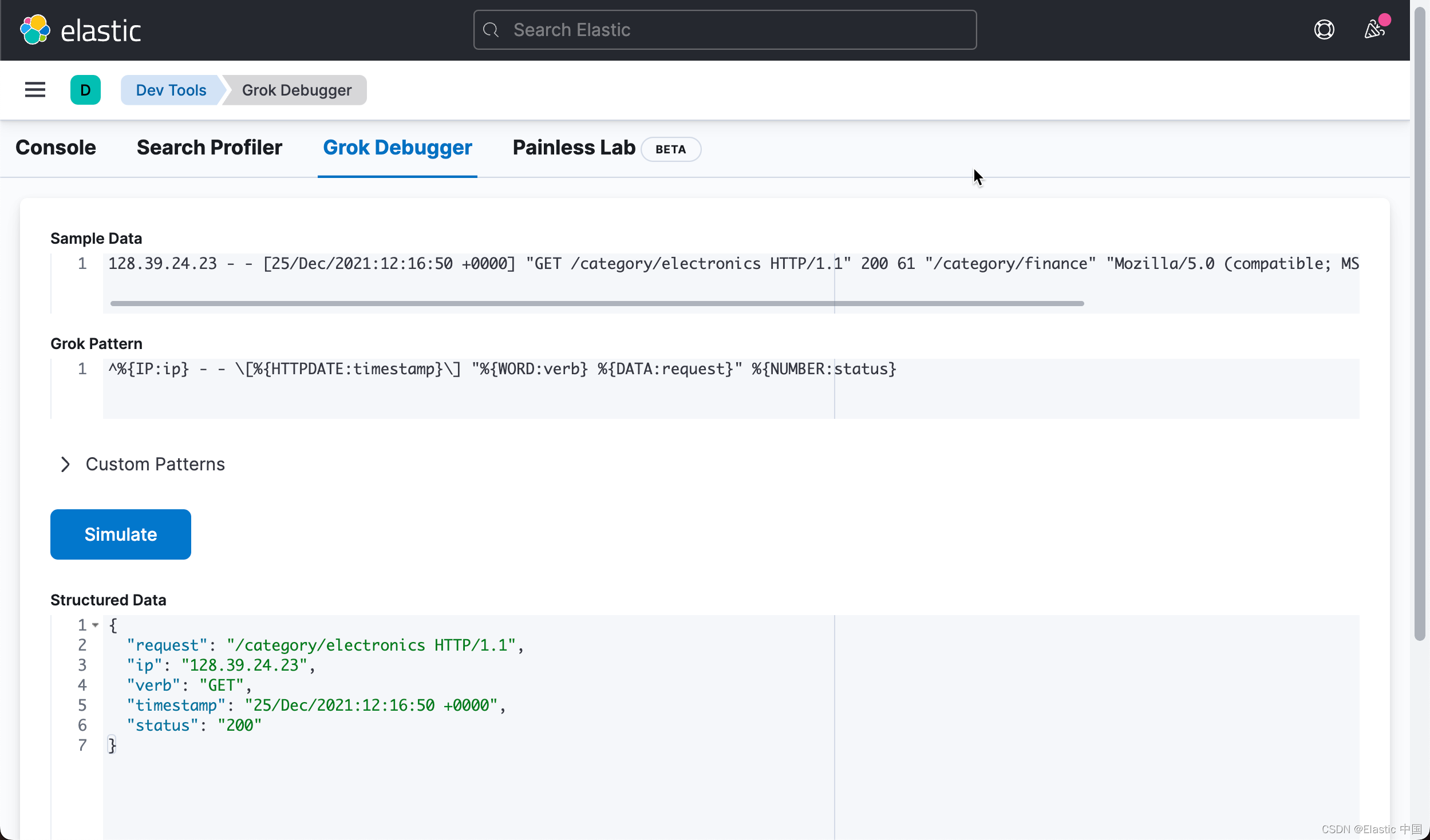
这给了我们如下的字段:
"request": "/category/electronics HTTP/1.1",
"ip": "128.39.24.23",
"verb": "GET",
"timestamp": "25/Dec/2021:12:16:50 +0000",
"status": "200"提取 Bytes
为了提取字节,我们需要再次使用 NUMBER 方法,但在此之前,我们需要使用常规空格或 %{SPACE}
^%{IP:ip} - - \[%{HTTPDATE:timestamp}\] "%{WORD:verb} %{DATA:request}" %{NUMBER:status} %{NUMBER:bytes}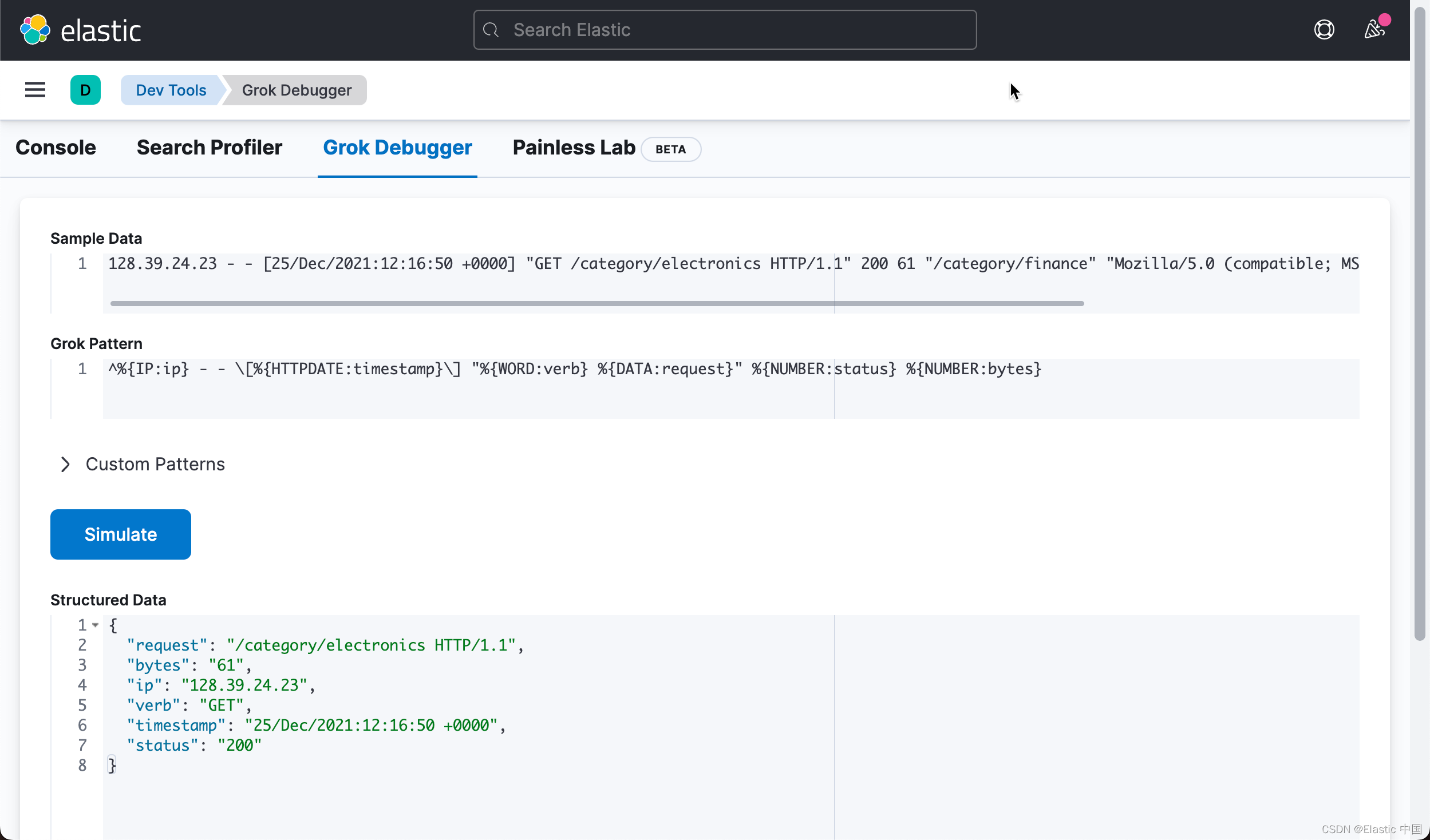
这给了我们如下的字段:
"request": "/category/electronics HTTP/1.1",
"bytes": "61",
"ip": "128.39.24.23",
"verb": "GET",
"timestamp": "25/Dec/2021:12:16:50 +0000",
"status": "200"提取 referrer
要提取 “referrer”,我们需要使用常规空格或 %{SPACE} -> “ 所以 Grok 会忽略它:
%{DATA:referrer}"如你所见,我们添加 DATA 直到它遇到 " 字符:
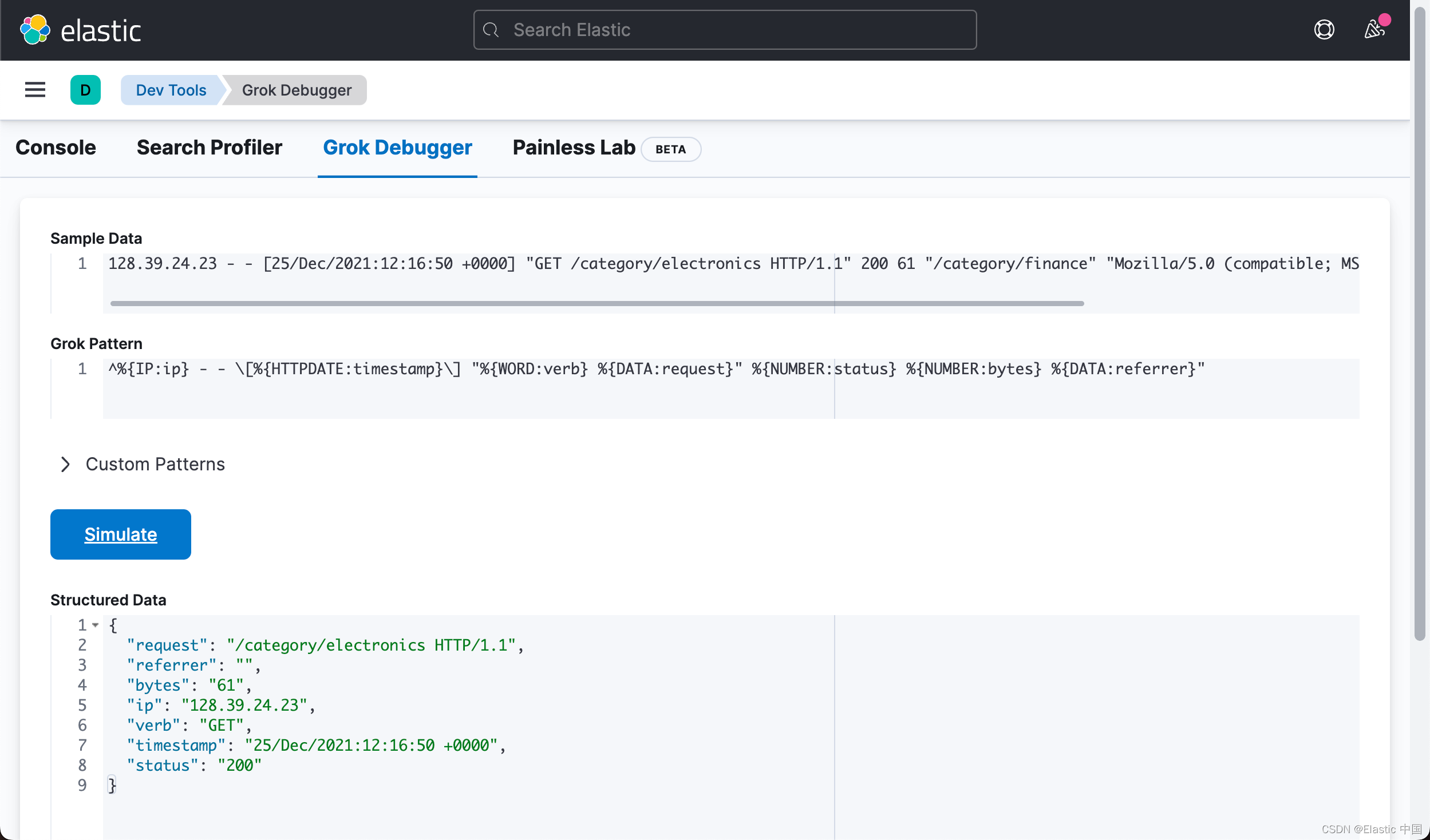
这给了我们如下的字段:
"request": "/category/electronics HTTP/1.1",
"referrer": "",
"bytes": "61",
"ip": "128.39.24.23",
"verb": "GET",
"timestamp": "25/Dec/2021:12:16:50 +0000",
"status": "200"忽略数据及提取 os
现在我们想忽略这个数据 ->” “Mozilla/5.0 (compatible; MSIE 9.0; 为此,我们将使用 “Mozilla/5.0” 的 DATA 方法,但不写入该字段将忽略它。
然后我们将使用不带冒号或字段名的 WORD 方法忽略 (compatible;
最后,我们将使用 DATA 忽略 MSIE 9.0;
这给我们留下了以下模式来忽略该数据
%{DATA}\(%{WORD};%{DATA};为了进一步解释这种模式......
\( -> 停止直到它到达 (
; -> 停止直到到达 ;请注意上面的模式中的 \( 字符。第一个 DATA 遇到 \( 即停止,也就是第一个数据。第二个 DATA 停止直到遇到 ; 符号。同样地,第三个 DATA 停止直到遇到 ;
现在我们可以使用 WORD 方法提取 os -> %{WORD:os}。就是这样! 现在我们剩下以下 Grok 模式来构建我们的数据。
^%{IP:ip} - - \[%{HTTPDATE:timestamp}\] "%{WORD:verb} %{DATA:request}" %{NUMBER:status} %{NUMBER:bytes} %{DATA:referrer}" %{DATA}\(%{WORD};%{DATA}; %{WORD:os}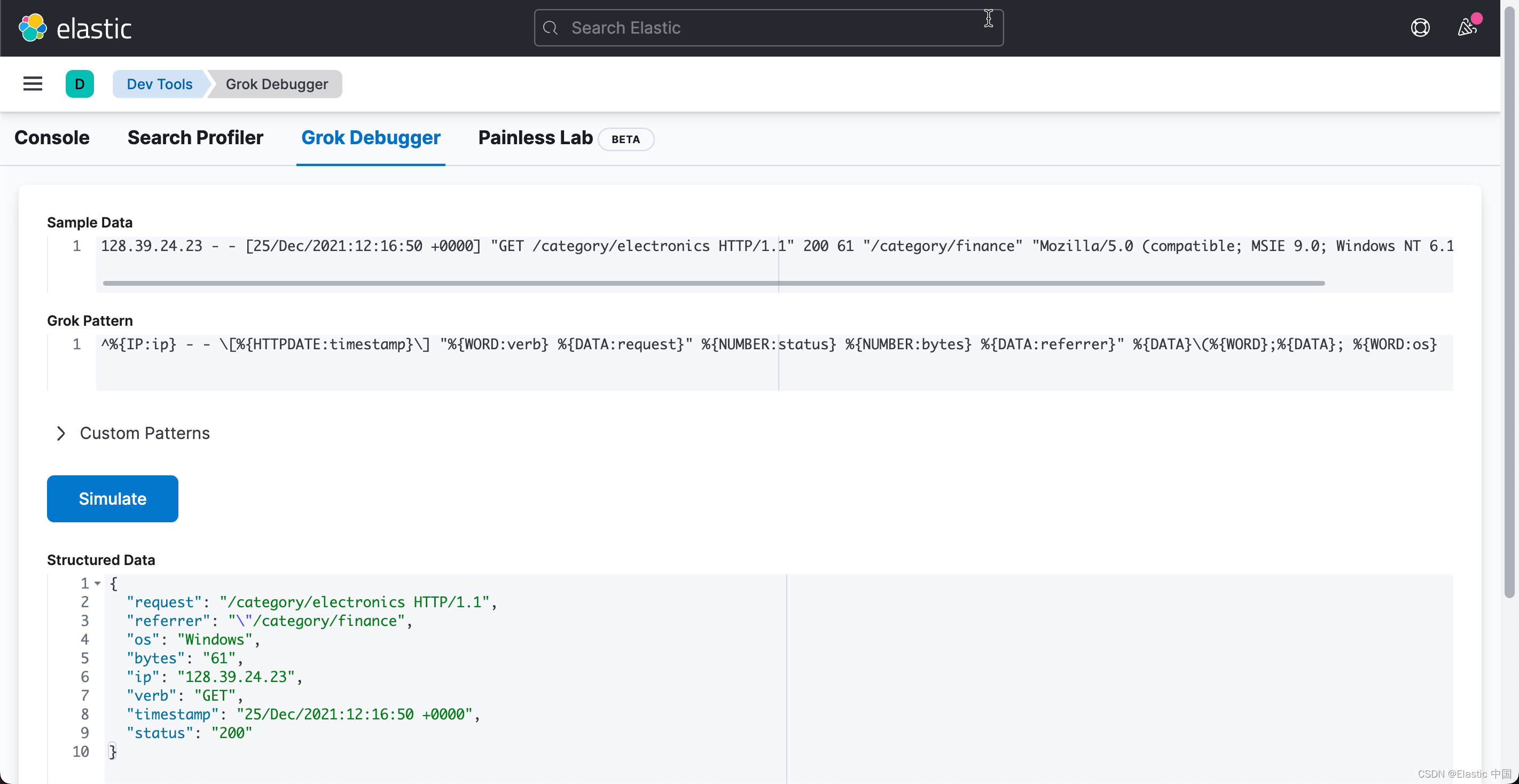
这为我们提供了这些整洁的字段,我们可以使用这些字段更轻松地搜索和可视化我们的日志数据:
"request": "/category/electronics HTTP/1.1",
"referrer": "\"/category/finance",
"os": "Windows",
"bytes": "61",
"ip": "128.39.24.23",
"verb": "GET",
"timestamp": "25/Dec/2021:12:16:50 +0000",
"status": "200"至此,我们已经完成了对整个日志信息的结构化分析。接下来,你可以参考视频:
Logstash 日志解析的 Grok 模式示例
Logstash 日志解析的 Grok 模式示例_哔哩哔哩_bilibili文章来源:https://uudwc.com/A/Xa4P
来了解如何在 Logstash 或者在 ingest pipeline 中进行使用这个 Grok pattern。文章来源地址https://uudwc.com/A/Xa4P