卷积层:
文章来源:https://uudwc.com/A/XkAGk
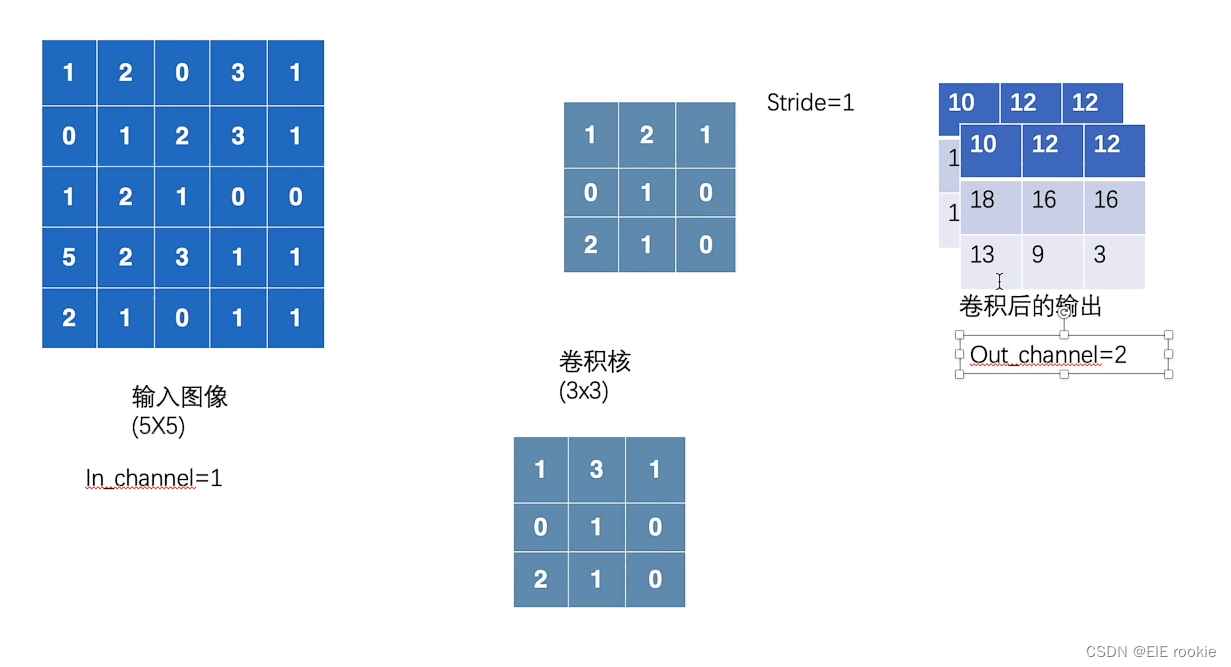 两个输出的情况 就会有两个通道 可以改变通道数的
两个输出的情况 就会有两个通道 可以改变通道数的
最简单的神经网络结构:
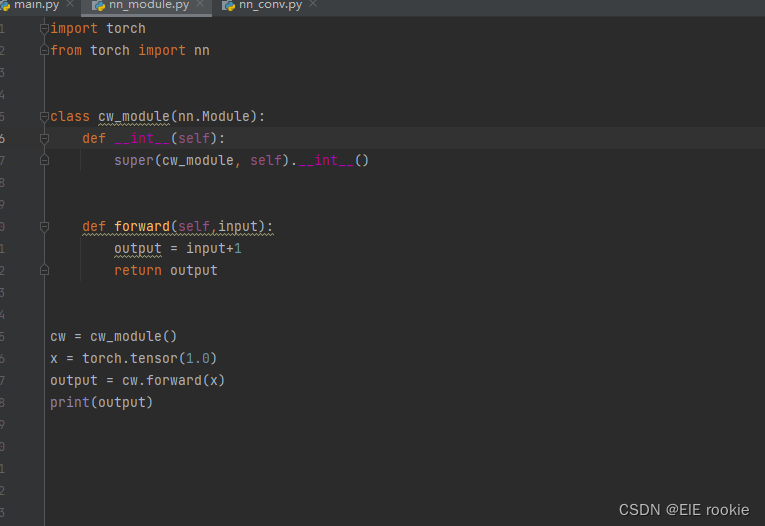 nn.Mudule就是继承父类
nn.Mudule就是继承父类
super执行的是 先执行父类函数里面的
forward执行的就是前向网络,就是往前推进的,当然也有反向转播,那就是用来就gradient dicent了,求导计算了。
![]()
卷积后的结果展示:
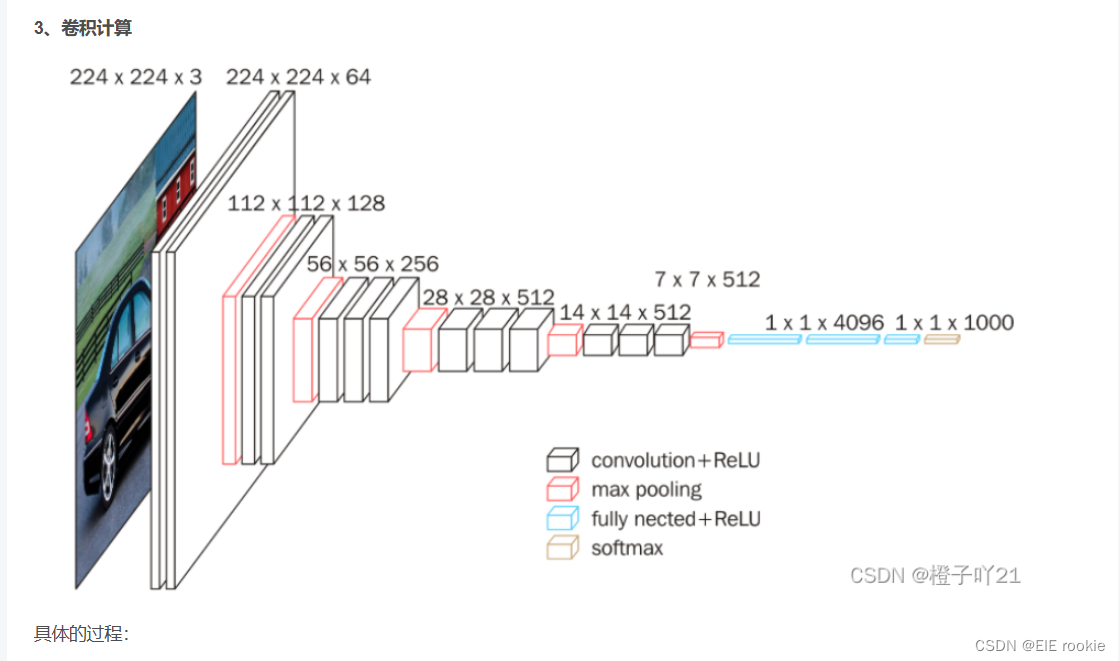 这里有个小细节
这里有个小细节
224 *244输出 224 *224 肯定是加了padding的,如何算出这个padding 官网给了公式
这个一般用不到,写论文科研可以再去官网查看
下面介绍池化层
mxpool是下采样,mxunpool是上采样,dilation是空洞卷积,ceil——mode来保留,用来对应下面情况
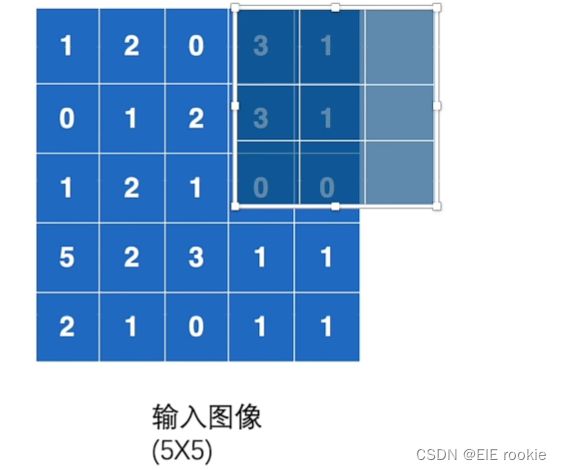

最大池化操作,这里有一点要注意,stride(每次核移动的步进)默认为卷积核一样大小
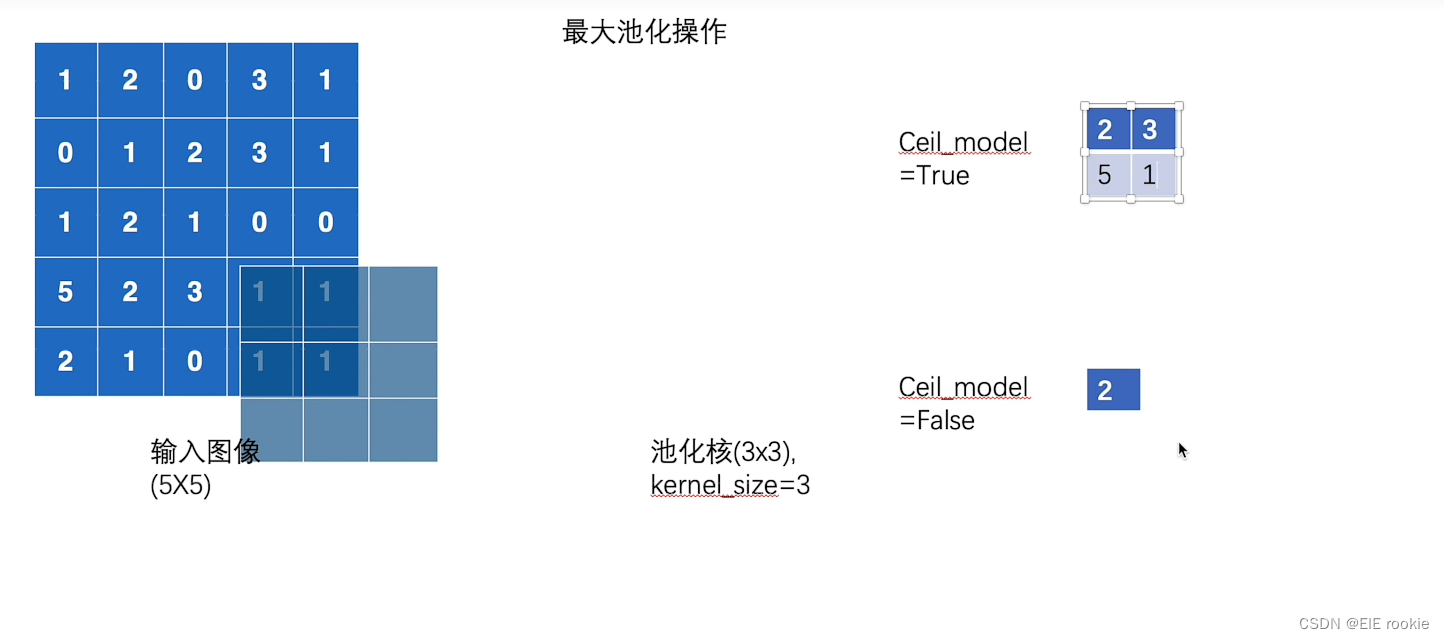
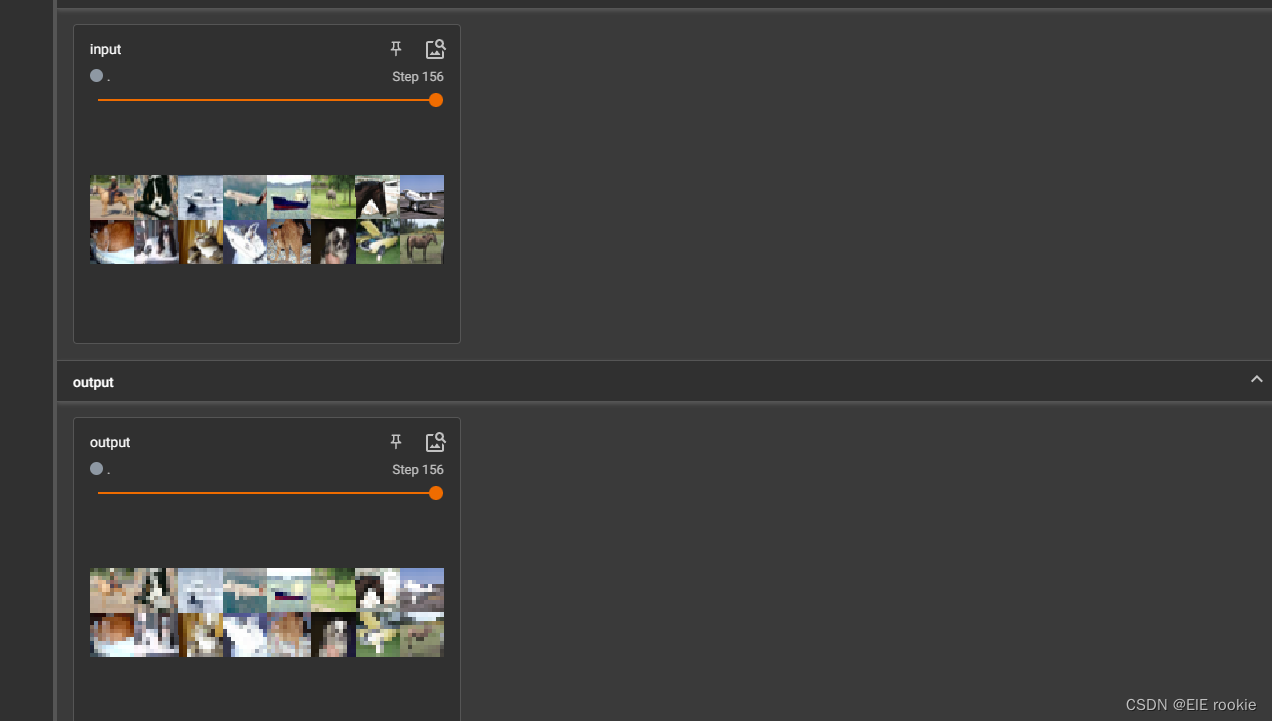 池化的直观感受就是变模糊了,保留了数据的主要特征,减小了数据量。
池化的直观感受就是变模糊了,保留了数据的主要特征,减小了数据量。
下面介绍非线性:
 inplace如果是1的话就是替换input,如果是flase的话,就是把输出用另一个变量来承接
inplace如果是1的话就是替换input,如果是flase的话,就是把输出用另一个变量来承接
一般来说是要false的,保留以前的数据嘛
下面是使用sigmoid函数进行的非线性处理
插播stm32学习的:
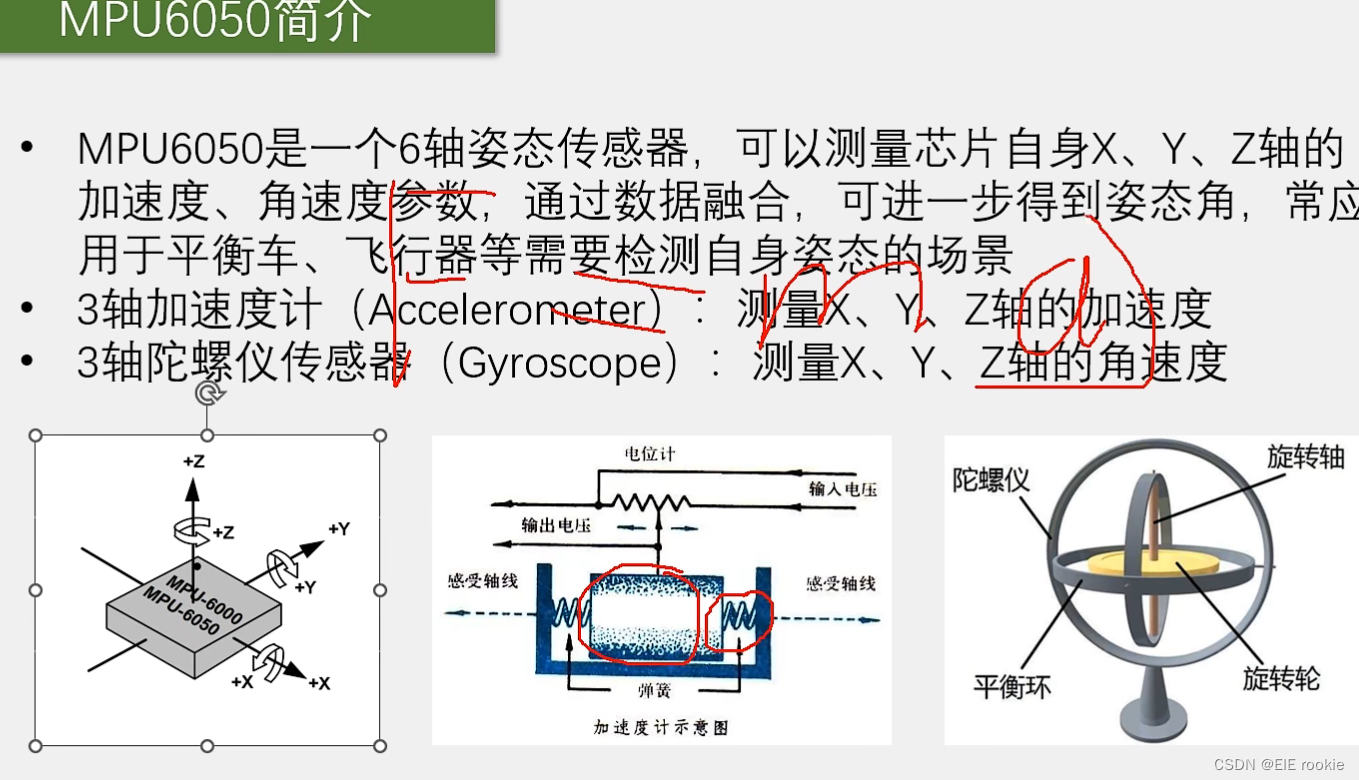
陀螺仪原理:
下面介绍机器学习线性回归的问题:

x就是各种已知道的特征,这就是回归任务的第一步,线性回归
 ,这是实际值
,这是实际值
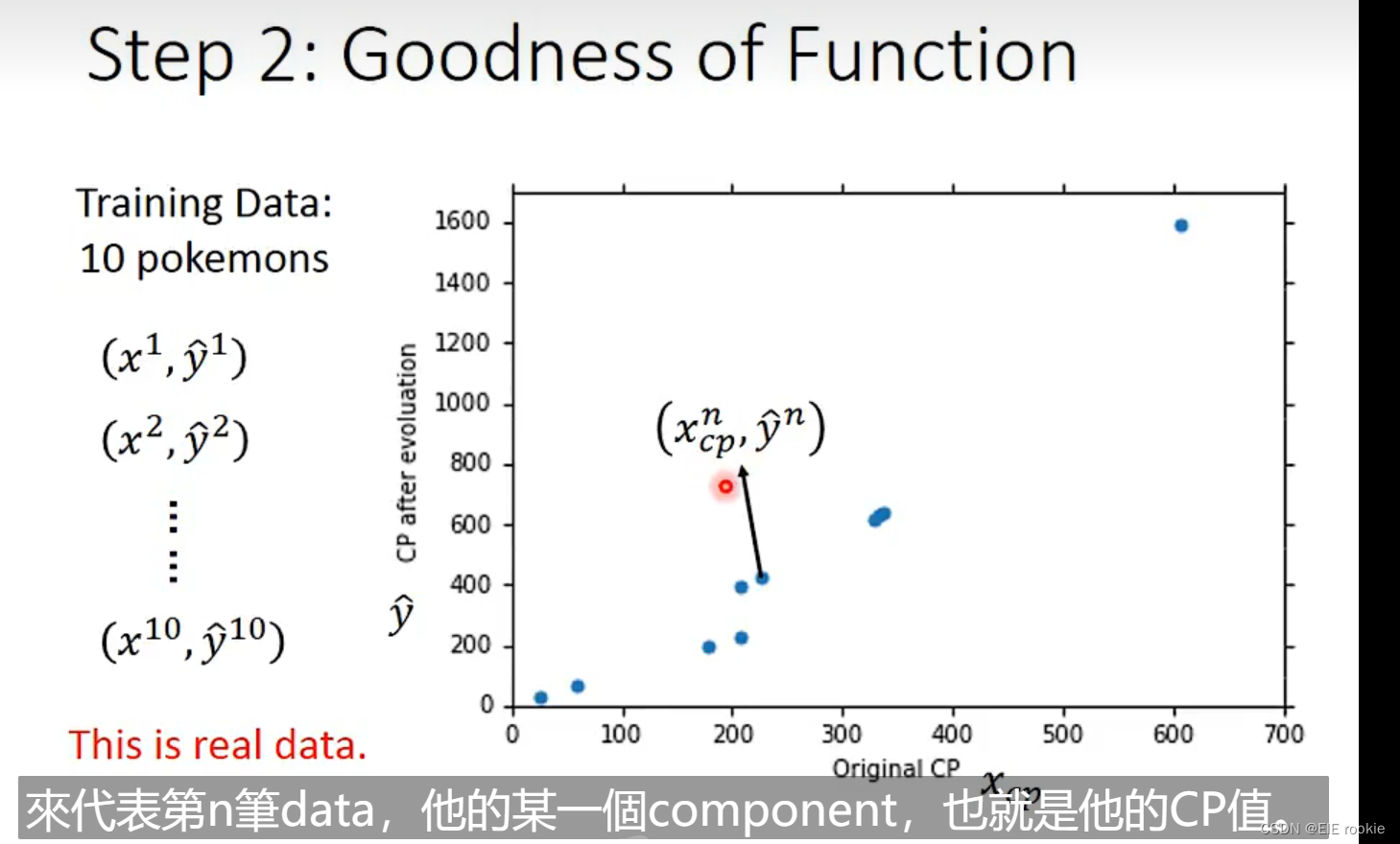
第二步 就是我有label 和feartures 用函数预测出预测label,比较好坏。选出比较规则。
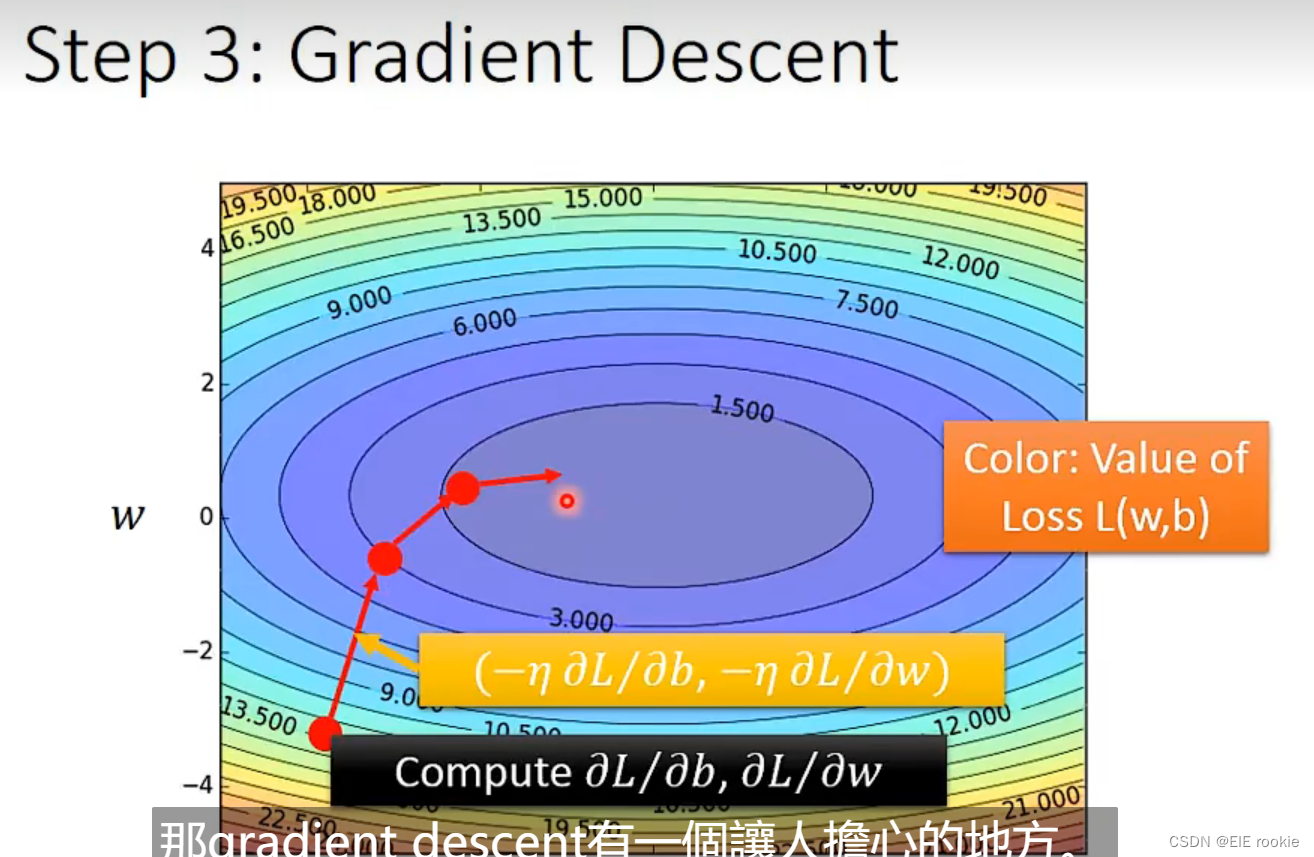
利用梯度下降,第三步找到最好loss
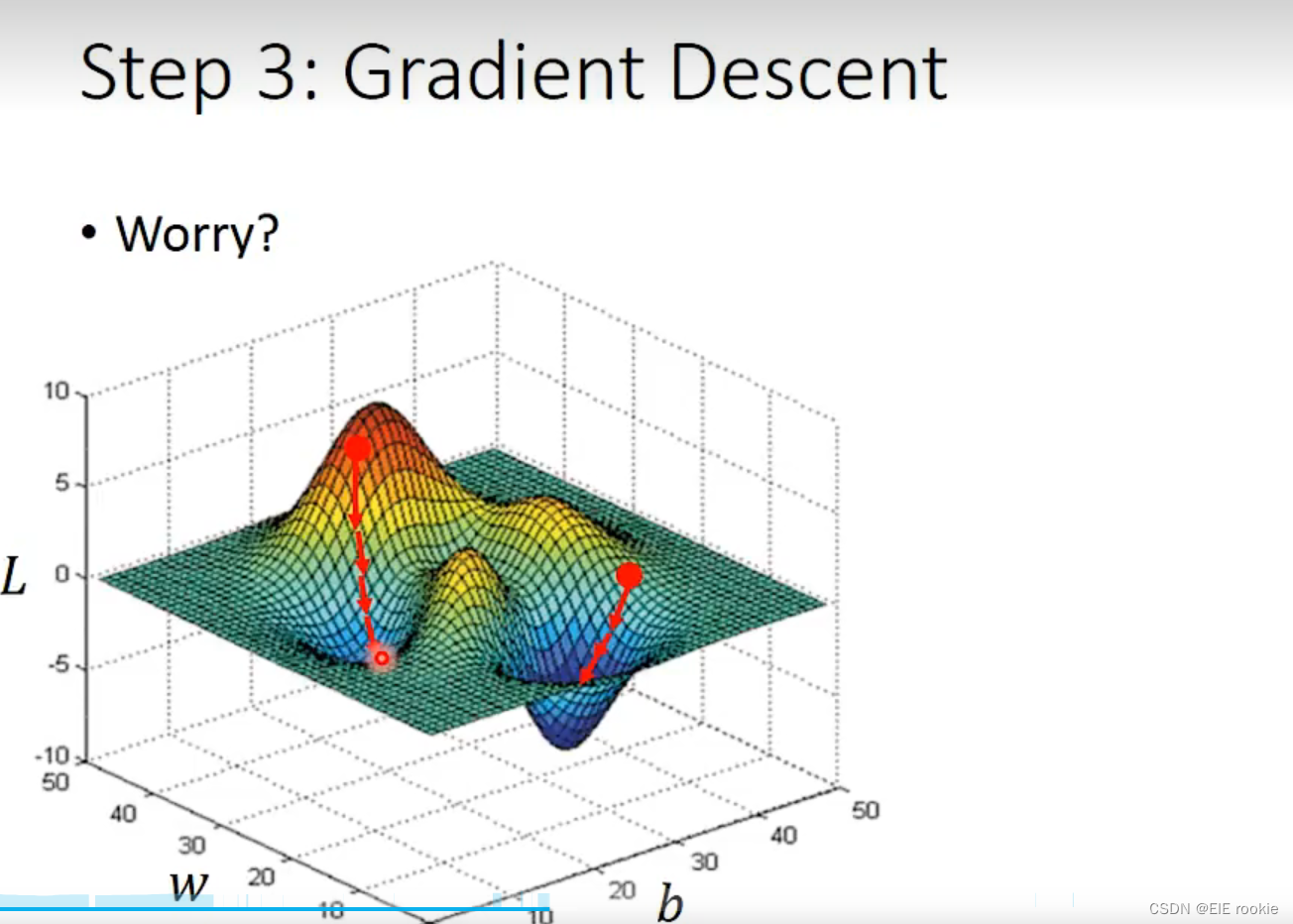
这种情况看人品?no 线性回归不需要担心,永远是第一种情况
梯度下降的算法:

用二次拟合更好的model:
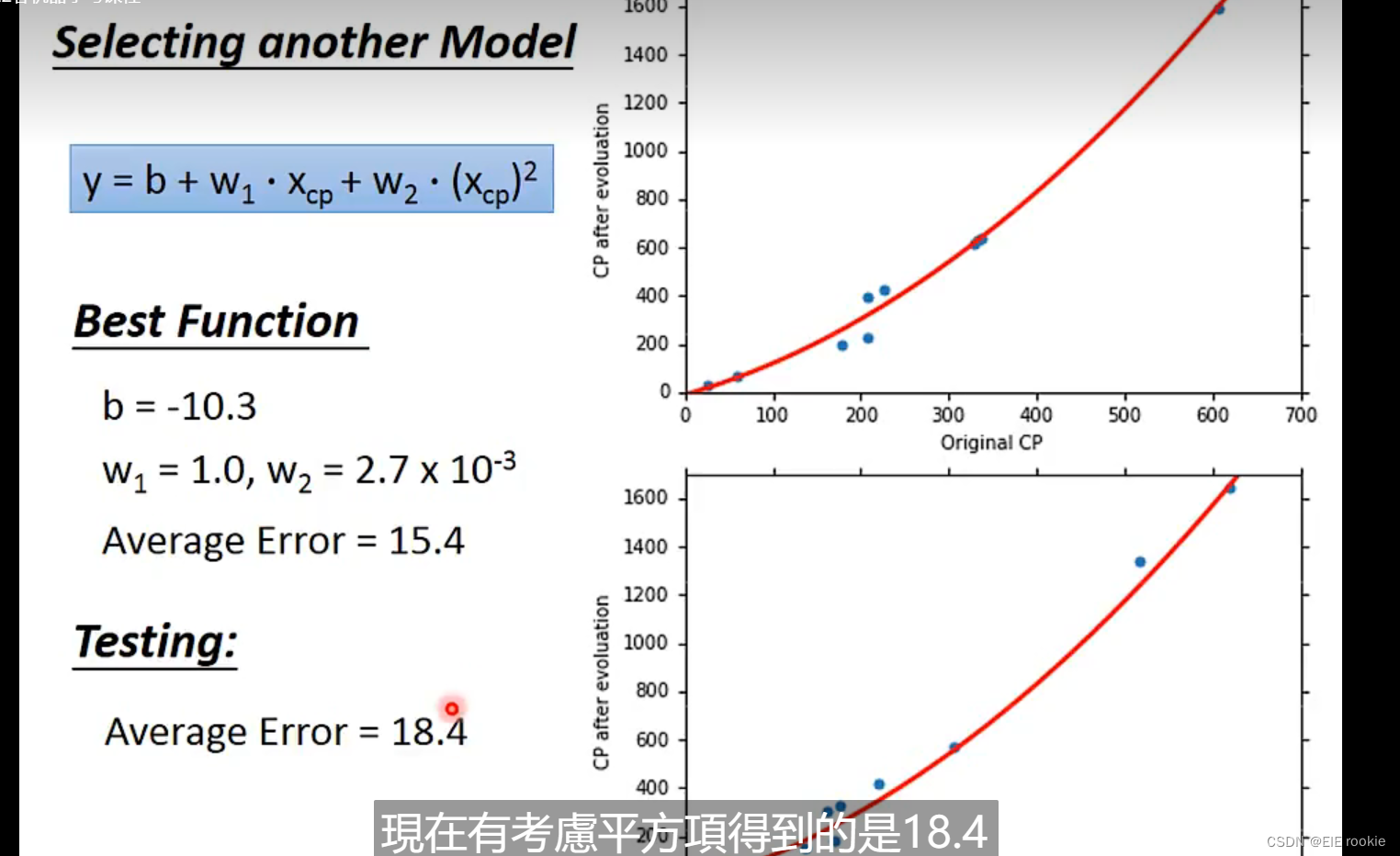
或者更高的次来拟合更好的model 和更低的loss:
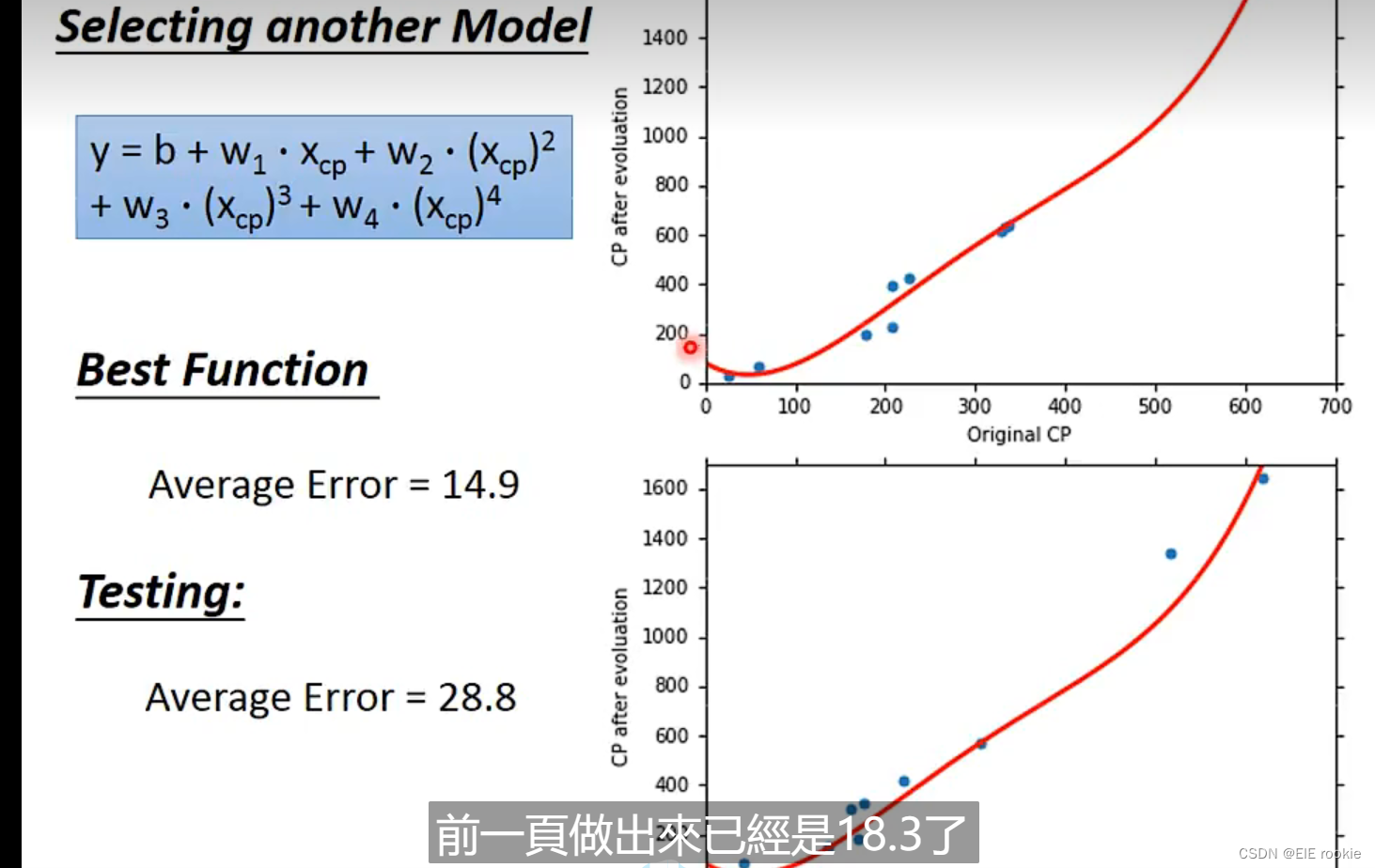
直到你用更高次的model来拟合,train 的结果更高了,但是test的结果更差了,这个就是过拟合了overfitting了
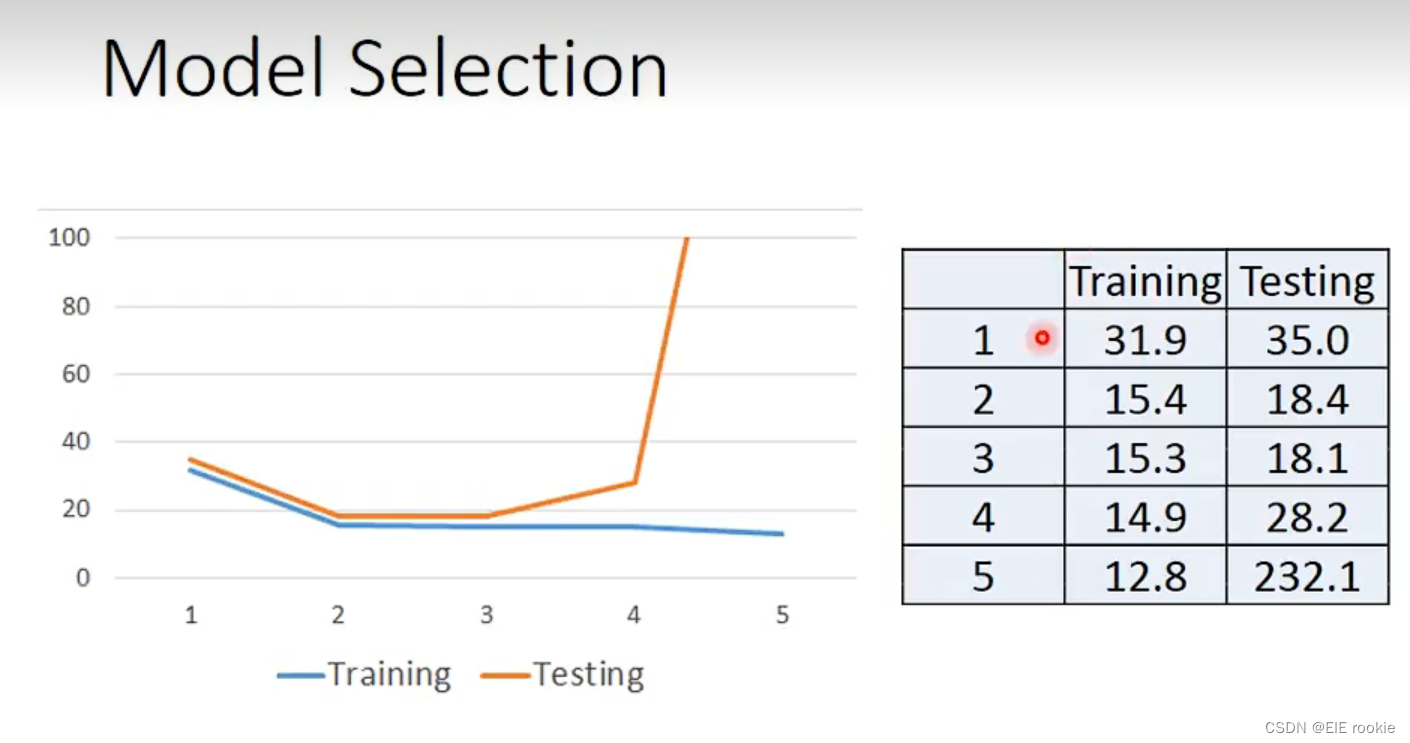
这个时候我们还要考虑:有时候只考虑一种feature肯定是不够的

用冲激函数来乘 来做选择,考虑多种feature


把全部能想象到的参数都加进去,因为我们不知道有哪些参数是影响的,这样做,我们在train上可以得到很低,但是又可能会过拟合!做到这里,还可以回到第二步,定义model的好坏。第二部只考虑的了预测值的error,regularization是加上额外的wi
 要求参数越小越好,降低敏感度,提高函数的平滑性!
要求参数越小越好,降低敏感度,提高函数的平滑性!
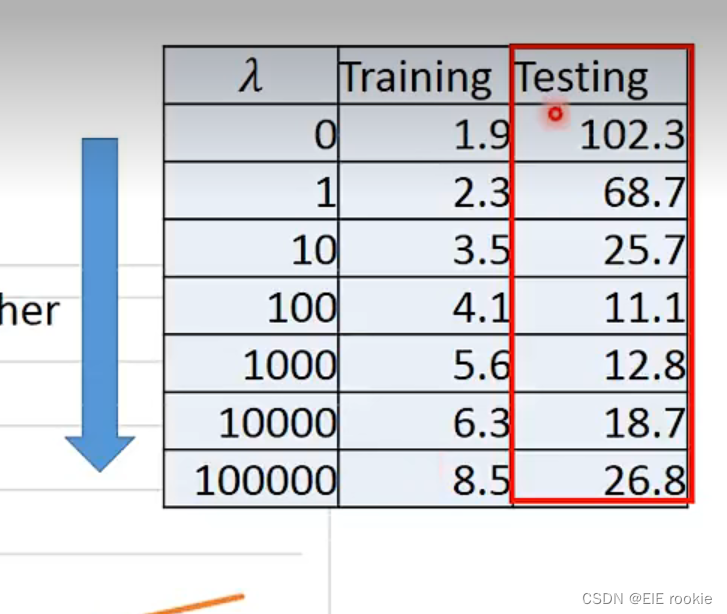 也不可以太平滑了,就相当于一个水平线,啥也干不成。调整朗木达来调整,为什么朗木达里面没有加上b?因为调整b的大小根本没用
也不可以太平滑了,就相当于一个水平线,啥也干不成。调整朗木达来调整,为什么朗木达里面没有加上b?因为调整b的大小根本没用
总结:一个输出和多个feature有关,不过我们不确定那些有影响,就会overfiting,可以用正则化来平滑函数文章来源地址https://uudwc.com/A/XkAGk