来源:投稿 作者:lsc
编辑:学姐
理论部分
01细粒度图片分类问题
1.1细粒度图片分类特点
可判别区域往往只是在图像中很小的一块区域内。

1.2细粒度图像分类数据集

1.3细粒度图像分类竞赛

1.4细粒度图像分类模型分类:
(1)强监督模型: 需要类别以外的标签进行监督
(2)弱监督模型: 不需要类别以外的标签
02强监督模型
Part-based R-CNN标签,引入bounding box和key point等额外的标注信息
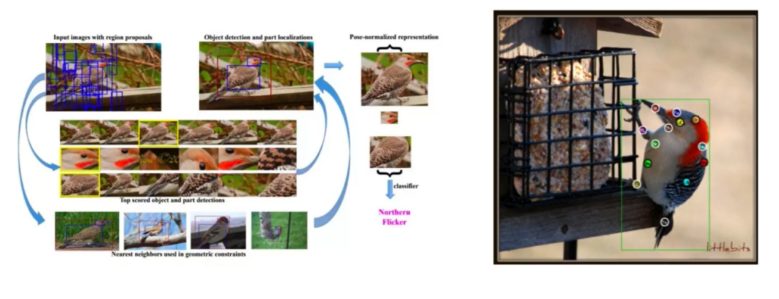
Part-based R-CNN的基本流程:

(1)基于R-CNN算法和空间的分布约束条件对局部区域进行检测,得到整体、头部和躯干部件。
(2)对不同区域使用对应的分类器提取卷积特征。
(3)将3个分类网络的全连接层特征进行连接,得到最后的特征表示。
(4)通过SVM分类器进行分类训练,该算法在CUB-200数据集上取得了73.9%的精度。
Part-based RCNN的缺陷:
(1)需要多个检测模型和多个分类网络,就算量大
(2)对不同数据集需要不同的部件划分,甚至难以划分(如植物),很难通用
03弱监督模型
3.1MA-CNN模型,不需要额外的标签

不显式地定义各个部件,不需要引入目标检测模型,而是对通道进行聚类(相加),得到不同部件的注意力图,将其看作 ’虚拟的部件’。

第2步: 聚类初始化,使用K-means等聚类方法对特征进行聚类,得到N个部件。
第3步: 得到初始的N个部件,为每一个部件引入全连接层,预测c维向量,对应每一个通道有多大的概率属于该部件,初始化标签为第1步聚类结果。
第4步: 得到N个c维向量,对特征图进行加权求和,得到N个部件的注意力。
MA-CNN模型特点:
(1)不需要多个网络,通过通道实现了注意力机制
(2)模型学习流程比较复杂
3.2双线性模型
3.2.1双线性卷积神经网络结构(Bilinear CNN)


B-CNN根据大脑工作时同认知类别和关注显著特征的方式,构建了两个线性网络,协调完成局部特征提取和分类的任务,该算法在CUB-200数据集上取得了84.1%的精度,不过该方法在合并阶段会产生较高的维度,使得整个计算开销非常大。
3.2.2双线性卷积神经网络结构(Bilinear CNN)特征外积计算

3.2.3双线性卷积神经网络结构(Bilinear CNN)

3.2.4 3钟双线性模型

(a)无共享

(b)部分共享

(c)完全共享(参数量最少,且没有明显的精度损失)
3.2.5双线性模型的输出维度太大
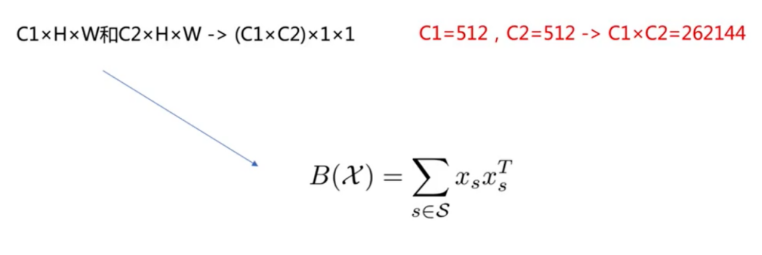
3.2.6 紧凑的双线性模型,通过使用低维的kernel近似来实现紧凑的双线性方法
近似方法: Random Maclaurin(RM), Tensor Sketch(TS)
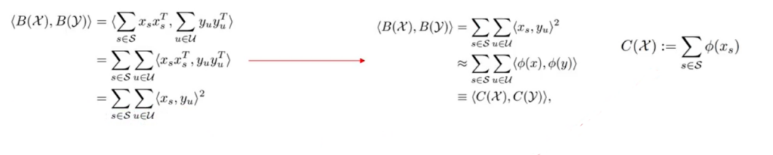
compact bilinear feature,维度可以指定,如将512 * 512 = 262144降维到2048
3.2.7投影降维

sketch表示单个空间位置的内积。
RM与TS投影方法与完整双线性模型对比

随着投影维度增加,逐步逼近完整双线性模型的性能
CUB鸟类识别数据集,VGG基准模型: 2000到800维度比较合适
3.2.8双线性模型的特点:
(1)模型结构比较简单,不需要特殊设计
(2)学习特征之间的注意力,有一定训练难度
代码部分
1、细粒度分类实战简介

数据集: CUB-200,共200种不同种类的鸟
使用网络: bilinear cnn
2、数据集读取
使用torch.utils.data里的data函数实现编写过程,分为__init__、__len__、__getitem__三个模块,
init: 完成某些参数的初始定义
len: 获取数据集的总数
getitem: 读取每幅图像和标签
class cub_dataset(Dataset):
def __init__(self, txt_path = "lists/lists/train.txt", file_path = "images/images/",
transforms = None):
self.txt_path = txt_path
self.file_path = file_path
fh = open(txt_path, 'r')
imgs = []
lals = []
for line in fh:
line = line.strip('\n')
line = line.strip()
words = line.split('.')
imgs.append(line)
lbls.append(int(words[0]) - 1)
self.imgs = imgs
self.lbls = lbls
self.transform = transform
def __getitem__(self, index):
img = self.imgs[index]
lbl = self.lbls[index]
img = cv.imread(self.file_path + img)
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
if self.transform is not None:
img = self.transform(img)
return torch.Tensor(img).float(), int(lbl)
def __len__(self):
return len(self.imgs)
3.模型搭建
(1)理解网络的设计思想
(2)利用torch.nn指令完成模型的基本搭建
(3)主要包括nn.Conv2d、nn.BatchNorm2d、nn.AvgPool2d等
class BCNN(nn.Module):
def __init__(self):
nn.Module.__init__(self)
self.features = torchvision.models.vgg16(pretrained = True).features
self.features = nn.Sequential(*list(self.features.children())[:-1])
self.fc = nn.Linear(512 ** 2, 200)
for param in self.feature.parameters():
param.requires_grad = True
nn.init.kaiming_normal_(self.fc.weight.data)
if self.fc.bias is not None:
nn.init.constant_(self.fc.bias.data, val = 0)
def forward(self, x):
N = x.size()[0]
assert x.size() == (N, 3, 448, 448)
x = self.features(x)
assert x.size() == (N, 512, 28, 28)
x = x.view(N, 512, 28 ** 2)
x = torch.bmm(x, torch.transpose(x, 1, 2)) / (28 ** 2)
assert x.size() ==(N, 512, 512)
x = x.view(N, 512 ** 2)
x = torch.sqrt(x + 1e-5)
x = nn.functional.normalize(x)
x = self.fc(x)
assert x.size() == (N, 200)
return x
图像分类论文已整理?点击卡片关注
回复“CVPR”领取
 文章来源:https://uudwc.com/A/Y62q8
文章来源:https://uudwc.com/A/Y62q8
文章来源地址https://uudwc.com/A/Y62q8