点击关注

文丨刘雨琦,编|王一粟
“互联网时代,我们是更危险,还是更安全?”
2016年,互联网正值高速发展之际,电梯广告经常出现这几个大字,两行标语,从病毒木马到网络诈骗,对于安全的思考、安全防范技术的建立一直在与科技发展赛跑。同样,大模型时代发展的早期,也引发了许多安全考量。
英特网被发明的十年后,互联网防护技术和产业链才开始补齐,而参考了过去几十年的经验,在大模型诞生后不到半年的时间里,围绕着模型安全、数据安全、内容安全的讨论,就已经不绝于耳。
最近一周,在上海外滩大会、浦江创新论坛、国家网安周等场合,产学研界针对于大模型应用落地所带来的数据安全问题(包括数据投毒、信息泄露、版权风险等)、模型安全问题(模型本身的安全漏洞、恶意利用等)、内容安全问题(生成内容包含违规、违法、色情等敏感信息等)、AI 伦理问题等进行了一系列的讨论。
如何为大模型保驾护航?
国内一些安全厂商,如360、蚂蚁、深信服、奇安信、山石科技等都在积极研发大模型安全技术。
01 大模型需要“医生”和“保镖”
大模型作为新物种的诞生,在训练过程中要有安全监控,在大模型最后推向市场的时候,也需要一次“质检”,质检后流入市场,需要可控的使用方式,这都是解决安全问题的宏观思路。
无论是通用大模型还是面向垂直领域的行业大模型,目前来看,模型安全的保护主要分为三个部分:

一是训练阶段的数据问题:如果数据采集不当、存在偏见或标签错误、数据被投毒,都有可能导致大模型产生错误输出、存在歧视或其他负面影响,同时数据在应用的过程中,也要面临数据泄露、隐私曝光等风险;
二是模型本身的可控问题:模型的可靠性、稳定性、鲁棒性等都需要进行检验,例如此前有用户构造针对性语句对模型进行诱导,大模型可能生产带有欺诈、歧视、政治倾向等风险内容;
三是大模型在实际场景中应用的安全问题:在实际的使用过程中,不同用户群体的交互和应用都需要谨慎评估,尤其是金融、医疗等领域对模型输出的正确性要求极高,如果应用不当,一石就容易激起千层浪。
多位业内人士向光锥智能表示:“模型安全需要一体化的技术防护体系,单独某一环节的把控解决不了根本问题。”
参考互联网安全的发展路径,诞生了诸多“病毒查杀”软件公司,一般检测、定位问题往往是第一步。
光锥智能了解到,蚂蚁的“蚁天鉴”,包含了大模型安全检测平台“蚁鉴2.0”、大模型风险防御平台“天鉴”,覆盖了从检测到治理到防御的全链条。蚁鉴2.0可对大模型进行多维度的安全扫描,检查存在的数据安全隐患、内容风险点等问题。相当于站在“黑产”角度,通过智能攻击对抗技术,自动生成数百万的诱导性问题,对生成式大模型进行诱导式问答,找出大模型的弱点和漏洞。
从技术的角度来看,蚁鉴采用了最新的“对抗智能”技术路线,使用智能对抗技术不断向大模型“投射问题”,观察模型生成的回答,判断是否存在风险。通过持续“拷问”,就像医生多次询问病人症状,平台可以盘查解析大模型的健康状况。
通过生成对抗样本,开发检测对抗样本的算法系统,来提升大模型安全性,已经成为一种主流技术趋势。在行业中,已有OpenAI、谷歌、微软、英伟达等一众巨头公司将对抗智能技术运用到其产品和服务中。
比如,在这种技术思路下,多伦多大学研发的 CleverHans 系统,就像一个专门设计来考验防盗系统的“小偷”,它会故意添加一些小干扰,来试图欺骗 AI 安防系统。在正常情况下,AI 系统可以准确识别“小猫”的图片,但 CleverHan 系统偏要在“小猫”图片上轻微修改几个像素点,给 AI 营造一种这是一张小狗图片的假象。假如,AI 系统被愚弄过去,那就代表其存在安全漏洞。
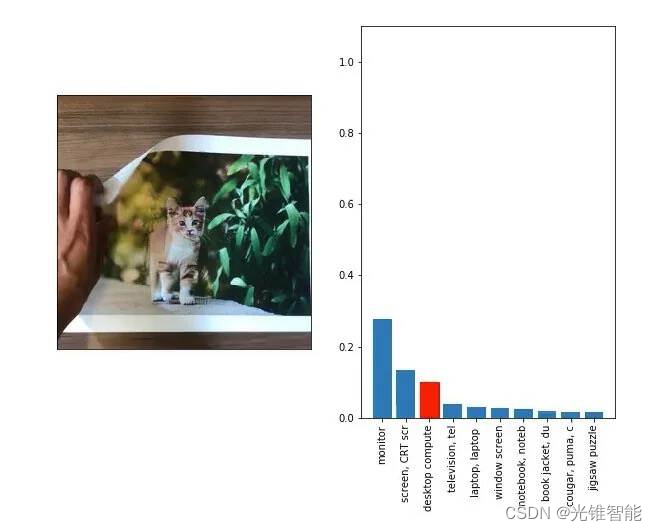
相比检测“诊断”,“防治”也非常重要。蚂蚁天鉴就像一个智能盾牌,可以防患于未然。通过智能分析用户提问意图来进行防御,天鉴可以拦截某些试图诱导模型生成敏感内容的恶意问题,确保外部恶意诱导无法传入大模型。同时,对模型输出内容实施二次过滤,自动识别风险信息并进行干预,确保大模型输出的内容符合规范。
更重要的是,数据问题是模型安全的源头,中国信通院云计算与大数据研究所主任石霖曾在一场学术交流会上分享道:“现在有非常多安全厂商采取了安全举措,包括对训练数据做一些清洗,对输入输出内容做过滤,另外还有监测和鉴别等安全防控措施。”
这需要防御平台作用在数据源头,针对数据源头有毒、模型深度黑盒不可控等问题。蚂蚁集团大安全机器智能部内容算法总监祝慧佳介绍,目前,天鉴正在尝试通过数据去毒、对齐训练、可解释性研究等手段保障模型安全。
02 用魔法打败魔法,以AI对抗AI
数字世界里和人眼世界里的内容特征是不一样的。
随着大模型时代的到来,其强大能力也为安全防护技术的变革提供了新的思路。“用 AI 的力量来对抗 AI ”已经成为一个热点方向。
事实上,对抗攻防思路并不是模型安全的专属。早在上个十年,面对种种安全威胁,人工智能领域就逐步形成了“以攻测防——以攻促防——攻防一体化”的安全理念,通过模拟各类攻击场景,不断探索模型和系统的弱点,以此推动算法和工程端的防御能力加强。
只不过,以往安全防护主要依赖机器学习算法模型,这需要大量专业数据知识积累,且面临知识盲区和小样本冷启动不及时的问题。利用大模型技术,可以实现更智能化的安全防控。
这体现在几个方面。一是大模型能够提供智能安全“参谋”。基于海量文本进行预训练的大模型,可以成为优秀的“参谋”,对症提出适当的分析和防御策略。比如,通过简单的自然语言描述,可以快速分析安全局势,提出应对措施建议,辅助安全团队规划解决方案。这类似于一个智能安全“小助手”。
从产业界的现状来看,AI 安全与否如何评测,目前尚缺乏一套易用和标准化的评测工具和规则。
这也是大模型防御中能够补充的另一方面,通过大模型技术学习风险知识和标准规则来提升 AI 对于风险的认知理解能力,以实现用大模型对抗大模型来进行极速防御和快速冷启动的目的。
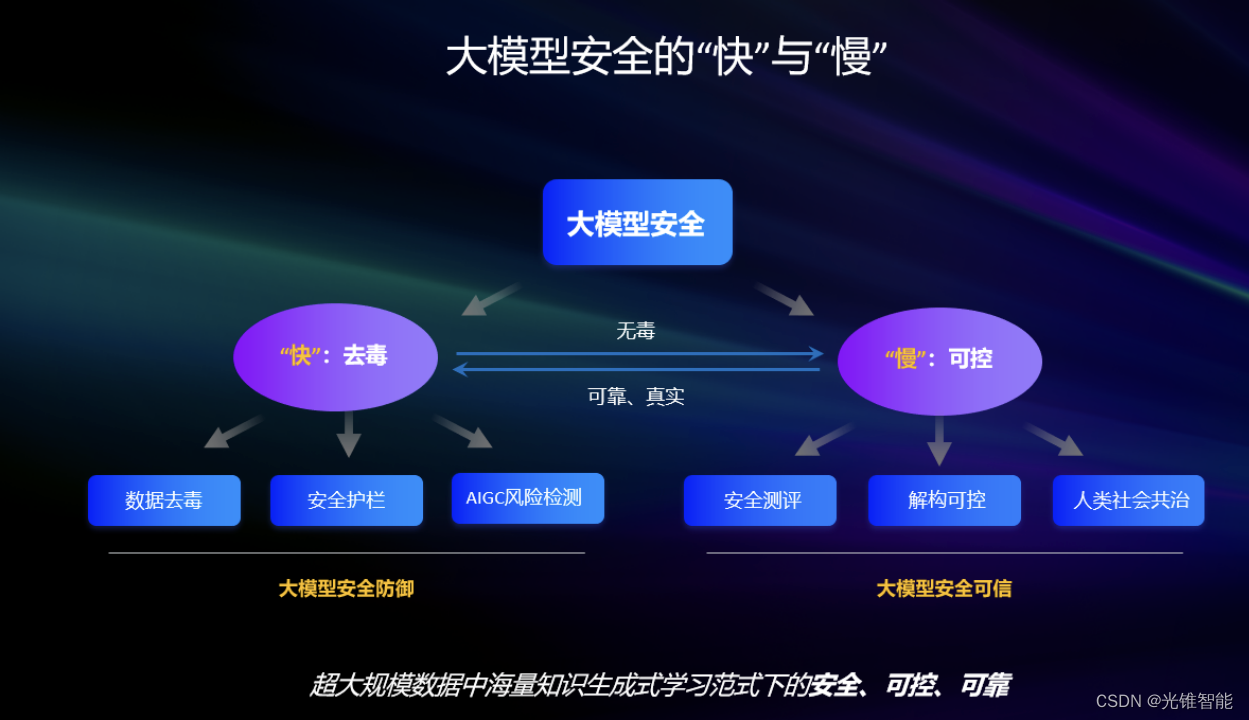
大模型安全既要“快“也要“慢”,这两个逻辑并不矛盾。在大模型安全防御方面要“快”,要能快速检测、查杀病毒,确保服务无毒害,这其中就包括了“数据去毒”、“安全护栏”、“AIGC风险检测”几个关键防御部分;而在大模型安全可信方面要“慢”,要能长远的、体系的保证整个系统环境的可控、可信,这其中就包括了“安全测评”、“解构可控”、“人类社会共治”等方面。
以文本安全为例,大模型可以基于安全标准规则、风险领域知识和历史风险样本,进行训练,提升模型对于风险标准和内容的理解力,从而实现对风险检测能力的提升。也采用大模型生成能力结合安全知识图谱,来构造攻击样本持续迭代优化检测模型。
一位安全专家表示:“相比人工收集的有限样本,大模型生成的海量多样化样本,将使安全检测模型'见多识广',更快适应新的威胁方式。”
这项技术,也被蚂蚁应用在了AIGC内容检测中。祝慧佳提及道:“AIGC深度伪造检测,也是采用以攻测防,以攻促防的思路,通过不同方式、不同风格、不同生成模型来进行生成,建立近千万的深度伪造数据,训练模型快速分辨内容是机器生成还是人工生成,从而实现泛化性和鲁棒性更好的检测模型。”
针对AIGC在运用过程中引发的问题,国际上也已经有头部公司开始着手布局。
OpenAI此前表示,考虑在ChatGPT中添加数字水印技术,以降低模型被滥用带来的负面影响;谷歌在今年的开发者大会中表示,将确保公司的每一张 AI 生成图片都内嵌水印;今年1月初,英伟达也发布了一款名为FakeCatcher的软件,以查出视频中的人脸是否为深度伪造。
回顾互联网发展史,混乱和高速发展往往是一对“孪生兄弟”,而正是在网络安全产业化趋于成熟后,互联网才真正迎来了百花齐放的应用落地。
同样,模型安全并不只是某一家安全厂商的任务,而是当安全科技形成了可信围栏后,大模型技术才真的能“飞入寻常百姓家”。
“大模型是非常复杂的问题,伦理、数据、训练等领域的复杂度都是前所未有的,是一个新领域,也是摆在所有人面前的一个命题。蚂蚁'蚁天鉴'在大模型安全视角上做了一些探索,但目前还有很多问题待研究解决,比如回答的内容真实性和准确性等难题,它还需要不断迭代,不断完善,需要全社会共同协作努力。”祝慧佳最后说道。
文章来源:https://uudwc.com/A/Y6B0J
欢迎关注光锥智能,获取更多科技前沿知识!文章来源地址https://uudwc.com/A/Y6B0J