【论文阅读】Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
文章目录
- 【论文阅读】Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
- 一、介绍及作用
- 二、具体模型
- 2.1 Swin-Unet的总体架构
- 2.2 Swin Transformer block
- 2.3 Decoder
- 三、实验结果
- 3.1 数据集
- 3.2 复现结果
Swin-Unet:最早用于医学图像分割的类Unet-Transformer ,使用相应的Swin-Unet在遥感数据集进行相应的测试
卷积神经网络(cnn)在医学图像分析方面取得了里程碑,提出了Swin-Unet,它是一个类unet的纯Transformer
相应特点:
- 标记化的图像patch被输入到基于transformer的Ushaped编码器-解码器架构中
- 具有跳跃连接
- 局部全局语义特征学习
Swin Transformer作为编码器来提取上下文特征,设计了一种基于对称Swin Transformer 的补丁扩展层解码器
对特征图进行上采样操作,恢复特征图的空间分辨率
纯基于Transformer 的u型编码器-解码器网络优于全卷积或Transformer 与卷积结合的方法
一、介绍及作用
Swin-Unet是第一个纯基于transformer的u型架构,由编码器、bottleneck、解码器和跳过连接组成,使用bottleneck 的网络结构很方便改变维度。灵活设计网络,并且减小计算量。
编码器、bottleneck和解码器都是基于Swin Transformer区块构建的
相应操作:
- 解码器利用斑patch扩展层对提取的上下文特征进行上采样
- 多尺度特征进行跳跃连接融合
- 恢复特征映射的空间分辨率
作用:
- 跳过连接的对称编码器-解码器架构,实现了从局部到全局的自关注;在解码器中,全局特征被上采样到输入分辨率
- 设计了一种patch扩展层,在不使用卷积和插值运算的情况下实现上采样和特征维的增加
- 对于Transformer,跳过连接也是有效的,构造了一个纯基于Transformer的带有跳过连接的u型编码器-解码器架构
二、具体模型
2.1 Swin-Unet的总体架构
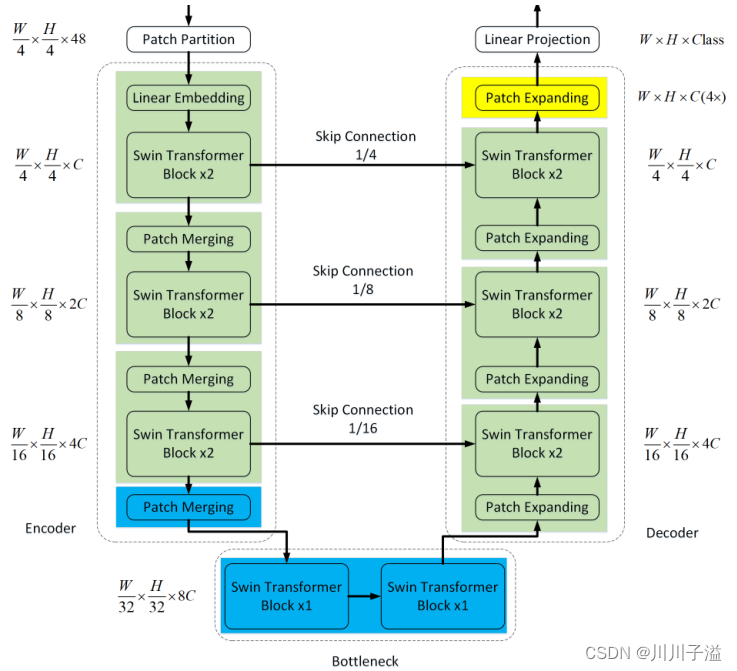
相应组成部分:
- 编码器
- bottleneck
- 解码器
- 特征连接skip connections
具体操作:
-
图像分割成不重叠的patch, patch大小为4 × 4,将输入信息转换为序列嵌入
-
patch token通过多个Swin Transformer块和patch合并层生成分层的特征表示
-
patch merge层负责降采样和增维
-
Swin Transformer块负责特征表示学习
-
patch Expanding执行上采样
-
最后使用最后一层patch展开层进行4×上采样,将特征图的分辨率恢复到输入分辨率
跳跃式连接的目的是弥补了下采样造成的空间信息丢失
2.2 Swin Transformer block
Swin Transformer block是基于移位窗口构造的
具体组成:
- LayerNorm (LN)层
- W-MSA or SW-MSA
- 残差连接
- 2层MLP
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M9rETWw5-1679811703279)(C:\Users\isipa\AppData\Roaming\Typora\typora-user-images\image-20230325194721120.png)]](https://img-blog.csdnimg.cn/d083053b66ff48b9878244cb608c23d9.png#pic_center)
Encoder
- 分辨率为H/4 × W/4的c维标记化输入输入到两个连续的Swin Transformer块中进行表示学习
- patch merge层将减少token数量(2× downsampling),
- 并将特征维数增加到原始维数的2×
- 重复三次
Transformer块构造瓶颈来学习深度特征表示。在Bottleneck,特征维数和分辨率保持不变
2.3 Decoder
解码器中使用patch Expanding对提取的深层特征进行上采样。patch Expanding将相邻维度的特征图重塑为更高分辨率的特征图(2×上采样),并相应地将特征维数降低到原维数的一半
重排操作将输入特征的分辨率扩大到输入分辨率的2倍S
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s04Uanfj-1679811703279)(C:\Users\isipa\AppData\Roaming\Typora\typora-user-images\image-20230325195746543.png)]](https://img-blog.csdnimg.cn/ec96e2346e554cda8efbb52f643d19a7.png#pic_center)
但是换个问法哈,有必要加这个Swin Transformer块吗,本质上都是对其进行上采样,是为了保持结构对称吗
Skip connection的作用:
- Skip connection用于融合编码器的多尺度特征与上采样特征
- 浅层特征和深层特征拼接在一起
- 减少了下采样造成的空间信息损失
- 线性层,连接特征的维数保持与上采样特征的维数相同
在原始的论文中,使用了ImageNet上预训练的权重用于初始化模型参数,在自己的使用中并没有进行预训练操作
基于transformer的模型的性能受到模型预训练的严重影响。论文中,我们直接使用ImageNet上Swin Transformer]的训练权值来初始化网络编码器和解码器,这可能是一种次优方案
三、实验结果
3.1 数据集
Vaihingen Dataset
包含33张由先进机载传感器采集的真正射影像(TOP)图像,每个TOP图像都有红外(IR)、红色®和绿色(G)通道。
相应参数:
- 图像被标记为sic类别
- 11张图像用于训练(图像id: 1、3、5、7、13、17、21、23、26、32和37)
- 5张图像用于测试(图像id: 11、15、28、30和34),
- 裁剪为256 × 256
Potsdam Dataset
有38个相同大小的patch (6000 × 6000),都是从高分辨率TOP提取
相应参数:
- 数据集进行了六个类别的标注,用于语义分割研究
- 每张图像都有三种通道组合,即IR-R-G、R-G-B和R-G-B- ir
- 使用14张带有R-G-B的图像进行测试
- (图像id: 2_13, 2_14, 3_13, 3_14, 4_13, 4_14, 4_15, 5_13, 5_14, 5_15, 6_14, 6_15, 7_13)
- 其余24张带有R-G-B的图像进行训练
- 我们将这些原始图像切割为256 × 256
3.2 复现结果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2BzcMGIn-1679811703279)(C:\Users\isipa\AppData\Roaming\Typora\typora-user-images\image-20230326141325826.png)]](https://img-blog.csdnimg.cn/bb601da58c274e16b44675ac8a338b3f.png#pic_center)
实验具体参数:文章来源:https://uudwc.com/A/ZGDaJ
- 动量项为0.9,权重衰减为1e−4
- SGD优化器
- 初始学习率设置为0.01
- 批处理大小设置为8
- 最大epoch为100
参考论文中的精度为为best_miou为0.58,复现效果为0.56,属于在误差范围里面,这里只采用了Vaihingen Dataset,来进行相应的复现文章来源地址https://uudwc.com/A/ZGDaJ