作者:京东科技 杨博
ChatGPT 才出现两个月,就已经引起了学术界的关注。微软成为ChatGPT母公司OpenAI的合作伙伴,并确认投资百亿美元。同时,微软正计划将 OpenAI 的技术整合到其产品中,包括Bing搜索引擎和其他软件,以增强它们的能力。然而,据Insider报道,微软却警告其员工不要与人工智能 (AI) 聊天机器人(ChatGPT)共享敏感数据:“请不要将敏感数据发送到 OpenAI 端点,因为他们可能会用它来训练未来的模型”。类似的,亚马逊最近也发出警告其员工提防 ChatGPT,一位亚马逊律师已敦促员工不要通过内部沟通形式与 ChatGPT 共享代码:“这很重要,因为您的输入可能会用作 ChatGPT 进一步迭代的训练数据,我们不希望它的输出包含或类似于我们的机密信息(目前我已经看到它的输出与现有机密材料非常匹配的实例)”
随着大公司对数据隐私的担忧日益增加,OpenAI 已将有关公司数据和隐私政策的问题转至ChatGPT 的常见问题解答页面。OpenAI 的服务条款授予了该公司使用 ChatGPT 用户生成的所有输入和输出的权利,并规定从使用的数据中删除个人身份信息 (PII)。
然而,在华盛顿大学教授计算语言学的 Emily Bender 表示,OpenAI 几乎不可能从提供给 ChatGPT 的数据中识别并删除所有个人信息。
其实,ChatGPT背后的LLM(大型语言模型)技术中的数据隐私保护问题早已受到关注。其中一个风险是如果公开使用含有隐私敏感数据训练的模型,则有可能通过模型提取出训练数据中的隐私敏感信息。这是因为这些训练数据集可能很大(数百 GB)并且来源广泛,即使是基于公共数据集上的训练,它们有时也可能包含敏感数据,包括个人身份信息 (PII)如:姓名、电话号码、地址等,这增加了使用此类数据训练的模型可能会在其输出中反映其中一些私人敏感信息的可能性。因此,重要的是要识别并最大程度地降低此类泄漏的风险,并制定解决未来模型问题的策略。
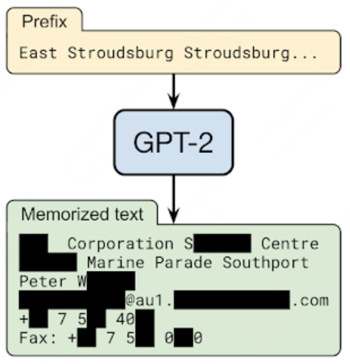
如果使用前缀“East Stroudsburg Stroudsburg…”提示GPT-2语言模型,它将自动完成一长串文本,其中包含特定人员的全名、电话号码、电子邮件地址和物理地址,其信息被包含在 GPT-2 的训练数据中。
在一个由谷歌、OpenAI、Apple、斯坦福、伯克利和东北大学的联合研究项目 “ Extracting Training Data from Large Language Models ”中,研究人员已经证明,只要能够查询预训练的语言模型,就可以提取特定的片段模型记忆的训练数据。该研究展示了他们对 GPT-2 的攻击,GPT-2 是一种在公共互联网的碎片上训练的语言模型,并且能够从模型的训练数据中提取数百个逐字的文本序列。这些提取的示例包括(公共)个人身份信息(姓名、电话号码和电子邮件地址)、IRC 对话、代码和 128 位 UUID。即使上述每个序列仅包含在训练数据的一个文档中,这种攻击也是有效的。令人担忧的是,该研究发现较大的模型比较小的模型更容易受到攻击。语言模型越大,就越容易记住训练数据。例如,在一项实验中研究人员发现,15 亿参数的 GPT-2 XL 模型比 1.24 亿参数的 GPT-2 Small 模型多记忆了10倍的信息。因此,训练数据提取攻击是对最先进的大型语言模型的现实威胁。
GPT-3 使用了 1750 亿个参数,这是迄今为止用于训练模型的最大参数数量(据现有资料显示ChatGPT使用了15 亿参数)。由于模型庞大,OpenAI社区决定不发布包含 1750 亿个参数的整个模型,而以 API 的方式公开其高级语言模型,允许用户以训练提示的形式向 GPT-3提供训练数据,模型使用该提示得出适当的结果。对于个人用户,语言模型通常将训练数据作为其在线学习功能的一部分进行存储,以使模型在运行中变得更好,这在涉及高度机密数据的用例中使用 GPT-3 时遇到了障碍。数据隐私一直是世界各地企业希望使用 GPT-3 创建特定领域应用最关心的问题。企业的担心围绕着公开的 GPT-3 API 端点不应保留或保存作为模型微调/训练过程的任何训练数据;以及通过向公开的 API 端点提供任何类型的输入,任何第三方都不应能够提取或访问作为训练提示的任何数据。
面对这些担忧,OpenAI 针对企业用户,允许企业与 OpenAI 签署特殊的谅解备忘录 (MoU) 和数据隐私协议 (DPA)以克服围绕数据泄露和数据隐私的担忧。幸运的是,除了制度保障,有一些技术方法可以安全地处理此类敏感数据。这正是隐私保护计算技术(简称隐私计算)的使命——用“你看不到的数据”回答问题,该技术栈包括联邦学习、安全多方计算、差分隐私、同态加密、可信执行环境等。
在2022年隐私联盟工作的年终总结上,中国信通院对其主导的《隐私计算白皮书(2022年)》、《隐私计算应用研究报告(2022年)》、《可信隐私计算研究报告(2022)》、《隐私计算通信应用研究报告(2022年)》、《多方数据联合风控应用能力评估要求》标准、《隐私计算应用 面向互联网场景的应用要求》标准、《隐私计算 面向金融场景的应用规范》标准等多项隐私保护计算成果进行发布、解读与进展介绍。作为国内隐私计算行业领军者,京东科技全程深度参与了「4大报告+3大标准」的编写研制工作,取得丰硕成果。
成果一:《隐私计算白皮书(2022年)》
《隐私计算白皮书(2022年)》由隐私计算联盟联合行业多家单位共同编制,京东科技作为主要牵头编写单位深度参与。《白皮书》涉及隐私计算概况、技术分析、应用分析、行业分析、热点问题分析以及总结展望等多方面,全面展现了行业成就及发展新态势,旨在为产业界应用隐私计算技术提供参考指导,推动隐私计算行业健康发展,在数据要素市场建设中发挥更大的价值。

《隐私计算白皮书(2022年)》封面及编写单位
《白皮书》认为,根据隐私计算技术、应用的不同发展特点,隐私计算当前正处于产业快速增长期,即将迈入前景广阔的稳定期。未来,随着我国数据要素市场的加速建设,作为数据流通的重要创新前沿技术,以隐私计算为代表的数据安全流通技术正在成为筑牢数字安全屏障的基础设施,以促进数据要素的可信安全流通。
成果二:《隐私计算应用研究报告(2022年)》
近两年来,在政策驱动和市场需求同时作用下,隐私计算技术、产业、应用迅速发展,成为商业和资本竞争的热门赛道。随着隐私计算技术可用性的快速提升,市场由观望正在转向落地,金融、政务、通信、医疗、互联网等行业率先开展隐私计算应用,能源、车联网等行业也开始探索性应用。
在此背景下,隐私计算联盟组织京东科技等成员单位共同编写了《隐私计算应用研究报告(2022年)》。主要涉及隐私计算应用背景、应用现状、项目应用部署难点及解决方案、应用展望等多个方面。

《隐私计算应用研究报告(2022年)》封面及编写单位
成果三:《可信隐私计算研究报告(2022年)》
近年来,数据成为国家基础性战略资源,在政策和市场的同时作用下,隐私计算技术、产业、应用迅速发展。但是,在技术应用过程中,隐私计算因为涉及需求方、供给方、监管方等多方的参与,仍然面临着安全性、合规性、可用性等方面的挑战,由此隐私计算技术如何“可信”应用引发业界思考。
经过广泛调研征集和深入讨论,由京东科技等多家隐私计算联盟成员单位共同编写了《可信隐私计算研究报告(2022年)》,主要包括可信隐私计算的发展背景、框架、核心要素、实践路径及未来展望等内容。

《可信隐私计算研究报告(2022年)》封面及编写单位
成果四:《隐私计算通信应用研究报告(2022年)》
随着隐私计算技术应用逐渐落地,其对通信行业在保证数据安全的前提下充分发挥自身数据应用价值的意义巨大。京东科技参与编写的《隐私计算通信应用研究报告(2022年)》便对隐私计算在通信行业的应用特性及典型场景进行了全面梳理,深入挖掘了潜在创新应用场景,为行业发展提供参考指引。

《隐私计算通信应用研究报告》封面及编写单位
《报告》指出,在通信行业,通信数据具有覆盖全面、特征丰富、真实性高、数据连续性高等独特优势和应用价值。以隐私计算技术为依托,可以推动通信行业数据与金融、政务、汽车、医疗等行业共享赋能,并在风险管控、营销分析、态势洞察等多个应用场景中提供数据安全共享计算的服务,能够在保证数据安全的前提下充分发挥通信数据应用价值,助力各行业数字化发展实践,对充分释放数据要素价值和推动社会经济发展具有重大意义。
成果五:《多方数据联合风控应用能力评估要求》标准
随着国家法律政策的重视、监管逐渐完善以及企业自身的经营需求,风控对于企业的重要性进一步提高。目前,风控已经从传统业务单线风控的1.0阶段、企业级单方风控体系的2.0阶段,正迈入多方数据联合风控体系的3.0阶段,其完整性、全面性、及时性都进一步提高。

风控业务发展的三个阶段
为解决行业需求,中国信通院依托中国通信标准化协会大数据技术标准推进委员会、隐私计算联盟,京东科技在内的多家银行、运营商、互联网企业及技术服务商共同编制《多方数据联合风控应用能力评估要求》标准。
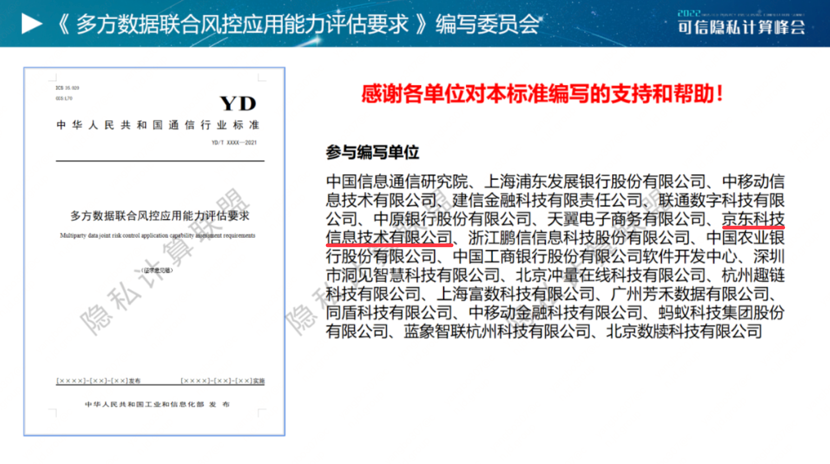
《多方数据联合风控应用能力评估要求》标准参编单位
成果六:《隐私计算应用 面向互联网场景的应用要求》标准
随着政策和市场需求双重驱动,隐私计算在互联网应用场景的需求强烈,其中主要集中在联合营销场景中,具体包括洞察分析、策略制定、营销投放、效果分析等细分场景。为了更好适配,隐私计算产品应在易用性、场景支持能力、算法能力与安全性上满足相应要求。

隐私计算技术在互联网行业中的应用场景
为此,中国信通院、隐私计算联盟与京东科技等单位共同起草《隐私计算应用 面向互联网场景的应用要求》标准。该标准梳理了互联网应用场景,并对适配互联网应用的隐私计算产品能力进行了规范。本标准自2022年8月启动以来,经历了框架总体设计和材料征集、场景研讨和梳理,以及标准主体讨论,目前已完成主体内容编制。

《隐私计算应用 面向互联网场景的应用要求》标准起草单位
成果七:《隐私计算 面向金融场景的应用规范》标准
近年来隐私计算应用加速落地,其中金融场景应用最为广泛。为解决供需双方诉求,发挥桥梁作用,隐私联盟联合京东科技等几十家企业召开了多次标准讨论会,共同编制了《隐私计算 面向金融场景的应用规范》。该标准旨在提升隐私计算产品在金融场景应用中的易用性、场景支持能力。
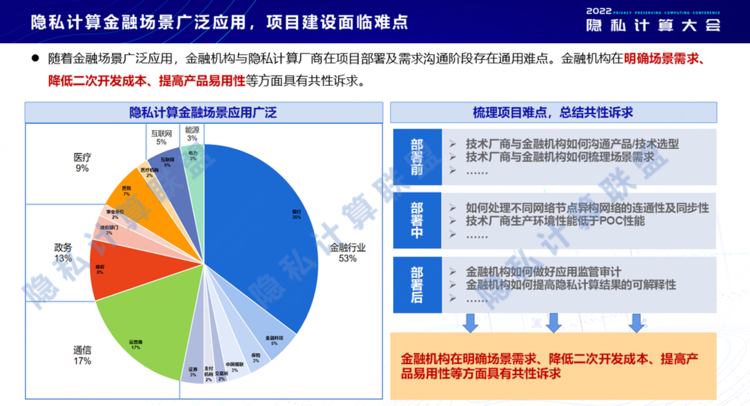
隐私计算技术在互联网行业中的应用场景
该标准主要包含四个能力域:第一个是算法实现与安全性,该能力域为场景应用奠定安全技术底座;第二个是金融场景支持能力,该能力域为完善产品已具备的基础能力项对金融场景应用的支持能力;第三个是易用性,该能力域为在已有的基础能力评测项之外进行扩展,增强隐私计算产品在实际金融应用中的易用性;第四个能力域是金融场景应用能力,该能力域为通过算法组合安全有效地完成常用金融场景的解决方案。

《隐私计算 面向金融场景的应用规范》标准起草单位
结语
大型语言模型已持续展示出其巨大的实用性和灵活性——然而,像所有创新一样,它们也可能带来风险。负责任地开发和使用它们意味着主动识别这些风险并提供降低风险的方法。作为国内隐私计算领军者,京东科技基于自身领先的技术研发实力、优质的数据生态资源、丰富的平台建设与场景运营落地经验,始终高度重视数据流通中隐私数据的保护。文章来源:https://uudwc.com/A/bkDy
此次京东科技深度参编的隐私计算技术系列成果的集中发布,秉持客户利益为先的商业准则,致力于通过技术持续改进数据要素流通效率与价值,为实现数据要素在数据安全和隐私保护基础上的有序流通提供了重要参考、指引和规范。未来,京东科技将积极凝聚行业共识,共同探索隐私计算的高质量发展方向和应用路径,充分发挥隐私计算作为数字经济持续健康发展的基础设施作用。文章来源地址https://uudwc.com/A/bkDy