目录
一、环境描述
二、pod失败状态
三、整体解决方案
四、补充一下Pod状态解释
文章来源地址https://uudwc.com/A/bvpP
一、环境描述
- 系统环境:CentOS Linux release 7.9.2009 (Core)
- 系统内核:Linux k8s-master01 5.4.153-1.el7.elrepo.x86_64 #1 SMP Tue Oct 12 08:16:11 EDT 2021 x86_64 x86_64 x86_64 GNU/Linux
- k8s版本:Kubernetes v1.20.14
- docker:Docker version 20.10.12
- 集群有外网, docker已经对接好网络镜像仓库。
二、pod失败状态
1.拉取k8s网上的镜像失败后的状态
[root@k8s-master01 ~]# kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
kube-state-metrics-5d497ddb45-lvtxv 2/3 ImagePullBackOff 2 16h2.拉取本地的镜像失败后的状态
[root@k8s-master01 ~]# kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
prometheus-adapter-5c976b9ddb-chn6v 0/1 ErrImageNeverPull 0 171m
prometheus-adapter-5c976b9ddb-gbn8l 0/1 ErrImageNeverPull 0 171m
prometheus-adapter-7858d4ddfd-55lnq 0/1 ErrImageNeverPull 0 176m
3.整体状态
[root@k8s-master01 ~]# kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 2 20h
alertmanager-main-1 2/2 Running 16 20h
alertmanager-main-2 2/2 Running 3 20h
blackbox-exporter-69894767d5-vbwz8 3/3 Running 3 20h
grafana-564b8d866c-gmgvr 1/1 Running 1 20h
kube-state-metrics-5d497ddb45-lvtxv 2/3 ImagePullBackOff 2 16h
node-exporter-4qsvn 2/2 Running 2 20h
node-exporter-9d8bw 2/2 Running 16 20h
node-exporter-ffs7q 2/2 Running 2 20h
node-exporter-qjdv9 2/2 Running 4 20h
node-exporter-zkkrr 2/2 Running 2 20h
prometheus-adapter-5c976b9ddb-chn6v 0/1 ErrImageNeverPull 0 171m
prometheus-adapter-5c976b9ddb-gbn8l 0/1 ErrImageNeverPull 0 171m
prometheus-adapter-7858d4ddfd-55lnq 0/1 ErrImageNeverPull 0 176m
prometheus-k8s-0 2/2 Running 2 20h
prometheus-k8s-1 2/2 Running 4 20h
prometheus-operator-545bcb5949-r6h6z 2/2 Running 3 20h
三、整体解决方案
第一步:使用如下命令查询pod详细报错内容,以下面报错为例拉取网络镜像失败,提示拉取失败 “ Failed to pull image "k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1": rpc error: code = Unknown desc = Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)”。
[root@k8s-master01 manifests]# kubectl get po -n monitoring
....
prometheus-adapter-6cf5d8bfcf-4jbhq 0/1 ImagePullBackOff 0 3m34s
prometheus-adapter-6cf5d8bfcf-bf4wt 0/1 ImagePullBackOff 0 3m34s
....
[root@k8s-master01 manifests]# kubectl describe po prometheus-adapter-6cf5d8bfcf-4jbhq -n monitoring
..........上面内容省略.................
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 70s default-scheduler Successfully assigned monitoring/prometheus-adapter-6cf5d8bfcf-4jbhq to k8s-master02
Normal SandboxChanged 48s kubelet Pod sandbox changed, it will be killed and re-created.
Normal Pulling 30s (x2 over 64s) kubelet Pulling image "k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1"
Warning Failed 14s (x2 over 49s) kubelet Failed to pull image "k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1": rpc error: code = Unknown desc = Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
Warning Failed 14s (x2 over 49s) kubelet Error: ErrImagePull
Normal BackOff 2s (x4 over 45s) kubelet Back-off pulling image "k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1"
Warning Failed 2s (x4 over 45s) kubelet Error: ImagePullBackOff
第二步:由上述报错信息知道了pod需要获取 prometheus-adapter:v0.9.1 的镜像文件。那么我们就需要通过docker 获取 prometheus-adapter 有那些镜像。
[root@k8s-master01 manifests]# docker search prometheus-adapter
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
willdockerhub/prometheus-adapter sync from k8s.gcr.io/prometheus-adapter/prom… 0
selina5288/prometheus-adapter sync k8s.gcr.io/prometheus-adapter/prometheu… 0
v5cn/prometheus-adapter sync k8s.gcr.io/prometheus-adapter/prometheu… 0
lbbi/prometheus-adapter k8s.gcr.io 0
boy530/prometheus-adapter 0
forging2012/prometheus-adapter 0
antidebug/prometheus-adapter 0
###下面的省略###第三步:拉取合适的镜像到本地,在此我拉取的是 “ lbbi/prometheus-adapter ”。
[root@k8s-master01 manifests]# docker pull lbbi/prometheus-adapter:v0.9.1
v0.9.1: Pulling from lbbi/prometheus-adapter
Digest: sha256:d025d1a109234c28b4a97f5d35d759943124be8885a5bce22a91363025304e9d
Status: Image is up to date for lbbi/prometheus-adapter:v0.9.1
docker.io/lbbi/prometheus-adapter:v0.9.1
注意!
我这里需要在后面加上版本,不然会出现找不到 lbbi/prometheus-adapter 。
根据实际情况来,有的镜像需要在后面加版本有的不需要加版本。
[root@k8s-master01 manifests]# docker pull lbbi/prometheus-adapter Using default tag: latest Error response from daemon: manifest for lbbi/prometheus-adapter:latest not found: manifest unknown: manifest unknown
第四步:给下载下来的镜像打标签。(可以选择不打标签,但是第五步的yaml配置文件修改时要写对镜像标签,否则就会出现找不到本地镜像的报错,pod 状态为 “ ErrImageNeverPull ”)
[root@k8s-master01 manifests]# docker images ## 此处为已经打好标签的镜像。
REPOSITORY TAG IMAGE ID CREATED SIZE
bitnami/kube-state-metrics latest 3b5c65a36550 13 hours ago 122MB
grafana/grafana 8.4.3 8d0b77430ee9 11 days ago 278MB
quay.io/prometheus-operator/prometheus-config-reloader v0.54.1 18cec637a88f 2 weeks ago 12.2MB
lbbi/kube-state-metrics v2.4.1 74a618d7bae7 2 weeks ago 38.7MB
k8s.gcr.io/kube-state-metrics v2.4.1 74a618d7bae7 2 weeks ago 38.7MB
quay.io/prometheus/node-exporter v1.3.1 1dbe0e931976 3 months ago 20.9MB
lbbi/prometheus-adapter v0.9.1 179df2737843 4 months ago 68.2MB
k8s.gcr.io/prometheus-adapter v0.9.1 179df2737843 4 months ago 68.2MB
quay.io/prometheus/alertmanager v0.23.0 ba2b418f427c 6 months ago 57.5MB
quay.io/brancz/kube-rbac-proxy v0.11.0 29589495df8d 7 months ago 46.6MB
## 打标签命令
[root@k8s-master01 manifests]# docker tag docker.io/lbbi/kube-state-metrics:v2.4.1 k8s.gcr.io/kube-state-metrics:v2.4.1
[root@k8s-master01 manifests]# docker tag docker.io/lbbi/prometheus-adapter:v0.9.1 k8s.gcr.io/prometheus-adapter:v0.9.1
注意!
k8s集群内的所以设备都需要拉取一样的镜像,并且打上一样的标签,因为k8s在没有做亲和力的情况下,部署pod是在集群内随机部署的。若没有全部拉取镜像,也会出现找不到本地镜像的问题,pod状态是 “ErrImageNeverPull”。
第五步:为了方便k8s找到本地的镜像文件,需要修改pod对应的yaml配置文件。
*** 找到需要镜像的yaml文件 ***
[root@k8s-master01 manifests]# vim prometheusAdapter-deployment.yaml
*** 找到拉取镜像失败的部分 “修改前” ***
image: k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
name: prometheus-adapter
*** 修改后 ***
# image: k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
image: k8s.gcr.io/prometheus-adapter:v0.9.1 # 容器镜像标签,写错拉取本地镜像失败。
imagePullPolicy: Never # imagePullPolicy: Always 总是网络拉取镜像, 是k8s默认的拉取方式。
# imagePullPolicy: Never 从不远程拉取镜像,只读取本地镜像。
# imagePullPolicy: IfNotPresent 优先拉取本地镜像。
name: prometheus-adapter
ports:
- containerPort: 6443
这是拉取本地镜像失败的状态,显示找不到本地镜像。
[root@k8s-master01 ~]# kubectl describe po prometheus-adapter-7858d4ddfd-55lnq -n monitoring
.......
............
..................
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning Failed 106m (x325 over 176m) kubelet Error: ErrImageNeverPull
Warning ErrImageNeverPull 101m (x348 over 176m) kubelet Container image "lbbi/prometheus-adapter" is not present with pull policy of Never
Warning FailedCreatePodSandBox 95m kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = [failed to set up sandbox container "743108347acf9031625da151edef7c323c894657048f1f6c14655baa64a0b9ce" network for pod "prometheus-adapter-7858d4ddfd-55lnq": networkPlugin cni failed to set up pod "prometheus-adapter-7858d4ddfd-55lnq_monitoring" network: failed to find plugin "calico-ipam" in path [/opt/cni/bin], failed to clean up sandbox container "743108347acf9031625da151edef7c323c894657048f1f6c14655baa64a0b9ce" network for pod "prometheus-adapter-7858d4ddfd-55lnq": networkPlugin cni failed to teardown pod "prometheus-adapter-7858d4ddfd-55lnq_monitoring" network: failed to find plugin "calico" in path [/opt/cni/bin]]
Normal SandboxChanged 95m (x2 over 95m) kubelet Pod sandbox changed, it will be killed and re-created.
Warning ErrImageNeverPull 75m (x94 over 95m) kubelet Container image "lbbi/prometheus-adapter" is not present with pull policy of Never
Warning Failed 65m (x139 over 95m) kubelet Error: ErrImageNeverPull
Normal SandboxChanged 26m (x4 over 28m) kubelet Pod sandbox changed, it will be killed and re-created.
Warning ErrImageNeverPull 25m (x10 over 27m) kubelet Container image "lbbi/prometheus-adapter" is not present with pull policy of Never
Warning Failed 3m2s (x114 over 27m) kubelet Error: ErrImageNeverPull
第五步:重新加载pod 的yaml 文件,并查询pod状态。
[root@k8s-master01 manifests]# kubectl replace -f prometheusAdapter-deployment.yaml
deployment.apps/prometheus-adapter replaced
[root@k8s-master01 manifests]# kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 2 22h
alertmanager-main-1 2/2 Running 16 22h
alertmanager-main-2 2/2 Running 3 22h
blackbox-exporter-69894767d5-vbwz8 3/3 Running 3 22h
grafana-564b8d866c-gmgvr 1/1 Running 1 22h
kube-state-metrics-6db4889fd4-hcmfn 3/3 Running 0 97m
node-exporter-4qsvn 2/2 Running 2 22h
node-exporter-9d8bw 2/2 Running 16 22h
node-exporter-ffs7q 2/2 Running 2 22h
node-exporter-qjdv9 2/2 Running 4 22h
node-exporter-zkkrr 2/2 Running 2 22h
prometheus-adapter-b8d4f7465-t7cxq 1/1 Running 0 108s
prometheus-adapter-b8d4f7465-tlf42 1/1 Running 0 101m
prometheus-k8s-0 2/2 Running 2 22h
prometheus-k8s-1 2/2 Running 4 22h
prometheus-operator-545bcb5949-r6h6z 2/2 Running 3 22h
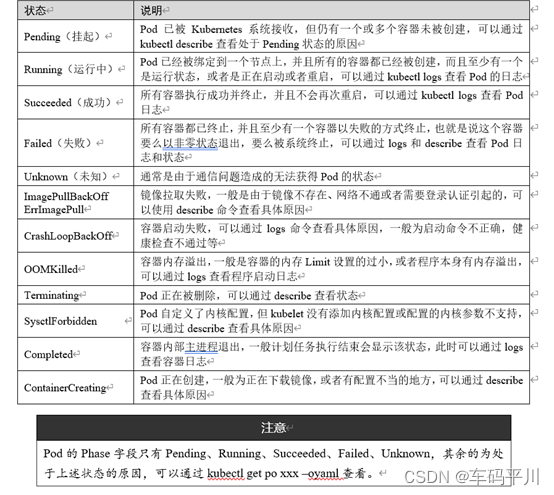
四、补充一下Pod状态解释
CrashLoopBackOff 容器退出,kubelet正在将它重启
InvalidImageName 无法解析镜像名称
ImageInspectError 无法校验镜像
ErrImageNeverPul 策略禁止拉取镜像
ImagePullBackOff 正在重试拉取
RegistryUnavailable 连接不到镜像中心
ErrImagePull 通用的拉取镜像出错
CreateContainerConfigError 不能创建kubelet使用的容器配置
CreateContainerError 创建容器失败
m.internalLifecycle.PreStartContainer 执行hook报错
RunContainerError 启动容器失败
PostStartHookError 执行hook报错
ContainersNotInitialized 容器没有初始化完毕
ContainersNotReady 容器没有准备完毕
ContainerCreating 容器创建中
PodInitializing pod 初始化中
DockerDaemonNotReady docker还没有完全启动
NetworkPluginNotReady 网络插件还没有完全启动
Evicted 即驱赶的意思,意思是当节点出现异常时,kubernetes将有相应的机制驱赶该节点上的Pod。 多见于资源不足时导致的驱赶。
文章来源:https://uudwc.com/A/bvpP