文章来源:https://uudwc.com/A/dbxm9
1.背景
要了解spark参数调优,首先需要清楚一部分背景资料Spark SQL的执行原理,方便理解各种参数对任务的具体影响。
一条SQL语句生成执行引擎可识别的程序,解析(Parser)、优化(Optimizer)、执行(Execution) 三大过程。其中Spark SQL 解析和优化如下图

-
Parser模块:未解析的逻辑计划,将SparkSql字符串解析为一个抽象语法树/AST。语法检查,不涉及表名字段。
-
Analyzer模块:解析后的逻辑计划,该模块会遍历整个AST,并对AST上的每个节点进行数据类型的绑定以及函数绑定,然后根据元数据信息Catalog对数据表中的字段和基本函数进行解析。
-
Optimizer模块:该模块是Catalyst的核心,主要分为RBO和CBO两种优化策略,其中RBO是基于规则优化(谓词下推(Predicate Pushdown) 、常量累加(Constant Folding) 、列值裁剪(Column Pruning)),CBO是基于代价优化。
-
SparkPlanner模块:优化后的逻辑执行计划OptimizedLogicalPlan依然是逻辑的,并不能被Spark系统理解,此时需要将OptimizedLogicalPlan转换成physical plan(物理计划),如join算子BroadcastHashJoin、ShuffleHashJoin以及SortMergejoin 。
-
CostModel模块:主要根据过去的性能统计数据,选择最佳的物理执行计划。这个过程的优化就是CBO(基于代价优化)。
在实际Spark执行完成一个数据生产任务(执行一条SQL)的基本过程:
(1)对SQL进行语法分析,生成逻辑执行计划
(2)从Hive metastore server获取表信息,结合逻辑执行计划生成并优化物理执行计划
(3)根据物理执行计划向Yarn申请资源(executor),调度task到executor执行。
(4)从HDFS读取数据,任务执行,任务执行结束后将数据写回HDFS。
上述运行过程
过程 (2)主要是driver的处理能力
过程 (3)主要是executor 、driver的处理能力、作业运行行为
本文从作业的运行过程(2)(3)各选择一个参数介绍从而了解运行过程。
目前的spark参数以及相关生态的参数列表几百个:
Hadoop参数:https://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
hive参数:Configuration Properties - Apache Hive - Apache Software Foundation
spark参数:spark 配置参数 Configuration - Spark 3.5.0 Documentation
spark 优化参数 Performance Tuning - Spark 3.5.0 Documentation
spark 执行参数 Spark SQL and DataFrames - Spark 2.0.0 Documentation
各个公司自定义参数:set spark.sql.insertRebalancePartitionsBeforeWrite.enabled = true
其他网上参考的参数:Hive常用参数总结-CSDN博客
参数列表
| 参数类型 |
参数 |
设置值 |
描述 |
| 资源利用 |
spark.driver.memory |
5g |
--driver-memory 5G 每个exector的内存大小,后缀"k", "m", "g" or "t" |
| input split |
spark.hadoop.hive.exec.orc.split.strategy spark.hadoop.mapreduce.input.fileinputformat.split.maxsize; spark.hadoop.mapreduce.input.fileinputformat.split.minsize; |
BI 、ETL 、HYBRID |
|
| shuffle |
spark.sql.shuffle.partitions |
200 |
|
| spark.default.parallelism |
80, 100, 200, 300 |
||
| join |
1.spark.hadoop.hive.exec.orc.split.strategy 参数
1. 参数作用:参数控制在读取ORC表时生成split的策略,影响任务执行时driver压力和mapper 数量。
2. 参数介绍 : 参数来源于hive :hive.exec.orc.split.strategy官方定义如下图,当任务执行开始时,ORC有三种分割文件的策略 BI 、ETL 、HYBRID(默认)
HYBRID模式:文件数过多和文件小的场景下,当文件数大于mapper count (总文件大小/hadoop默认分割大小128M) 且文件大小小于HDFS默认(128M)的大小。
ETL:生成分割文件之前首先读取ORC文件的footer(存储文件信息的文件),
BI: 直接分割文件,没有访问HDFS上的数据。
ORC文件的footer是什么?
ORC 文件原理:全称 Optimized Row Columnar 1.ORC是一个文件格式比较高效的读取、写入、处理hive数据。(我之前理解是一个高效压缩文件)。2.序列化和压缩: intger和String 序列化。按照文件块增量的压缩。
文件结构:三级结构:stripes 存在具体的数据行组(索引、数据行、stripe footer 的信息),file footer 文件的辅助信息(stripe的列表、每个stripe行数、列的数据类型、列上聚合信息 最大值最小值),psotscipt 文件的压缩参数和压缩后的大小。
3.使用方法和场景: 因此ETL模式下读取的file footer是每个orc文件块的辅助信息。对于一些较大的ORC表,footer可能非常大,ETL模式下读取大量hdfs的数据信息切分文件,导致driver的开销压力过大,这种情况适用BI模式比较合适。
一些配合使用参数 如:spark.hadoop.mapreduce.input.fileinputformat.split.maxsize; spark.hadoop.mapreduce.input.fileinputformat.split.minsize; map输入最小最大分割块,maxsize 和minsize在输入端控制ORC文件的分割合并。当spark 从hive表中读取数据是会创建一个HadoopRDD的实例,HadoopRDD根据computeSplitSize方法分割文件(org.apache.hadoop.mapreduce.lib.input.FileInputFormat ) Math.max(minSize, Math.min(maxSize, blockSize) 源代码Source code,因此文件表的小文件过多3M大小,根据公式一个小文件就是一个split分割生成大量的patitions,导致tasks数量就巨大,整个任务性能瓶颈可能在读取资源数据缓解。
文件分割源码

 spark.sql.files.maxPartitionBytes 单partition的最大字节数, 为了防止把已经设置好的分割块再次合并,可以将 set spark.hadoopRDD.targetBytesInPartition=-1。
spark.sql.files.maxPartitionBytes 单partition的最大字节数, 为了防止把已经设置好的分割块再次合并,可以将 set spark.hadoopRDD.targetBytesInPartition=-1。

2.spark.sql.shuffle.partitions
参数作用: 在任务有shuffle时候(join或者聚合场景下)控制partitions的数量。
参数介绍:
| Property Name |
Default |
meaning |
链接 |
翻译 |
不同点 |
共同点 |
| spark.sql.shuffle.partitions |
200 |
Configures the number of partitions to use when shuffling data for joins or aggregations. |
Spark SQL and DataFrames - Spark 2.0.0 Documentation |
Spark SQL中shuffle过程中Partition的数量 |
仅适用于DataFrame ,group By, join 触发数据shuffle,因此这些数据转换后的结果会导致分区大小需要通过Spark.sql.shuffle.partitions 中设置的值。 |
配置shuffle partitions 的数量 |
| spark.default.parallelism |
For distributed shuffle operations like reduceByKeyand join, the largest number of partitions in a parent RDD. For operations like parallelizewith no parent RDDs, it depends on the cluster manager:
|
Default number of partitions in RDDs returned by transformations like join, reduceByKey, and parallelize when not set by user. |
Configuration - Spark 3.5.0 Documentation |
1.reduceByKey 1.若当前RDD执行shuffle操算子如reducebykey 和join ,则为在父RDD中最大的partition数。 |
spark.default.parallelism 是随 RDD 引入的,当用户未设置时候,返回reduceByKey(), groupByKey(), join() 转换的默认分区数,仅适用于RDD。 |
参数用法:在提交作业的通过 --conf 来修改这两个设置的值,方法如下:或者
spark-submit --conf spark.sql.shuffle.partitions=300 --conf spark.default.parallelism=300
sqlContext.setConf("spark.sql.shuffle.partitions", "300")
sqlContext.setConf("spark.default.parallelism", "300”)
参数介绍2.0:chatGPT3.5 的答案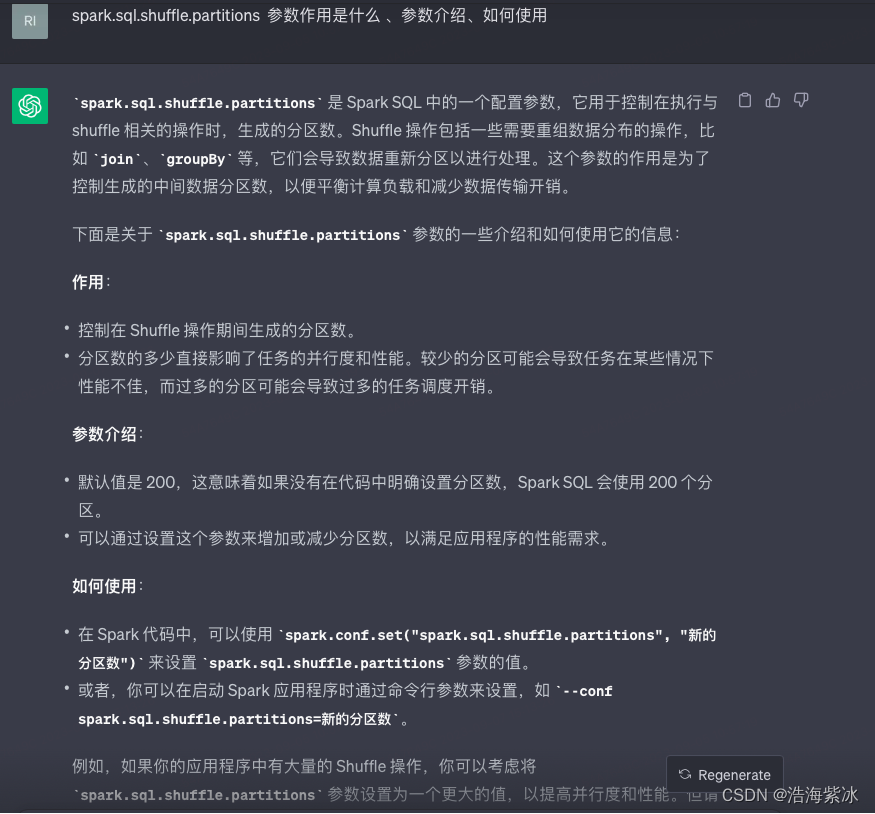
理解spark的并行度:
-
资源的并行 exector数和cpu core数
-
数据的并行 spark作业在各个stage的task 的数量是并行执行,task数量设置成Spark Application总CPU core数量的2~3倍,同时尽量提升Spark运行效率和速度;
扩展: flink 的并行度
参考文档:
1.Spark SQL底层执行流程详解(好文收藏)-腾讯云开发者社区-腾讯云 spark 执行原理
2.ORC 参数:Configuration Properties - Apache Hive - Apache Software Foundation
3.ORC文件定义: LanguageManual ORC - Apache Hive - Apache Software Foundation
4.oRC解读: 深入理解ORC文件结构-CSDN博客
5.hadoop input: How does Spark SQL decide the number of partitions it will use when loading data from a Hive table? - Stack Overflow
6.文件分割:从源码看Spark读取Hive表数据小文件和分块的问题 - 掘金, How does Spark SQL decide the number of partitions it will use when loading data from a Hive table? - Stack Overflow
7.spark手册:How to Set Apache Spark Executor Memory - Spark By {Examples}
8.并行: performance - What is the difference between spark.sql.shuffle.partitions and spark.default.parallelism? - Stack Overflow
9.flink的并行 : 并行执行 | Apache Flink
10.reducebykey :scala - reduceByKey: How does it work internally? - Stack Overflow
11.key values : 4. Working with Key/Value Pairs - Learning Spark [Book]
12.spark并行: Spark调优之 -- Spark的并行度深入理解(别再让资源浪费了)_spark并行度-CSDN博客
13.场景: spark SQL 任务参数调优1文章来源地址https://uudwc.com/A/dbxm9