ES选主过程?
其实ES的选主过程其实没有很高深的算法加持,启动过程中对接点的ID进行排序,取ID最大节点作为Master节点,那么如果选出来的主节点中存储的元信息不是最新的怎么办?
其实他是分了2个步骤做这件事,先选出ID最大的主节点,然后再从元信息最新的节点将元信息数据复制到选举出来的主节点
当然虽然是选出ID取值最大的节点作为主节点,但是内部还是有一定限制逻辑的:
参选人数需要过半,达到 quorum(多数)后就选出了临时的主。为什么是临时的?每个节点运行排序取最大值的算法,结果不一定相同。举个例子,集群有5台主机,节点ID分别是1、2、3、4、5。当产生网络分区或节点启动速度差异较大时,节点1看到的节点列表是1、2、3、4,选出4;节点2看到的节点列表是2、3、4、5,选出5。结果就不一致了,由此产生下面的第二条限制。
得票数需过半。某节点被选为主节点,必须判断加入它的节点数过半,才确认Master身份。解决第一个问题。
当探测到节点离开事件时,必须判断当前节点数是否过半。如果达不到quorum,则放弃Master身份,重新加入集群。如果不这么做,则设想以下情况:假设5台机器组成的集群产生网络分区,2台一组,3台一组,产生分区前,Master位于2台中的一个,此时3台一组的节点会重新并成功选取Master,产生双主,俗称脑裂。
选举主分片过程?
Master节点并不知道主分片节点位于哪里,它只能向所有节点上的所有Shard去询问你的website下标是不是0,那么这个询问的请求量就等于 节点数 * Shard数,如果你的规模非常庞大,那么这个将会很耗时,这个时候可能会获取到多份下标为0的请求响应,5.X版本之后主分片的选举是根据一个List<最新主分片>,在这个集合中的分片都是元信息最新的分片数据
高并发写数会不会影响读?
首先写是加锁的,无论是Bulk方式还是普通方式
Bulk方式的写锁
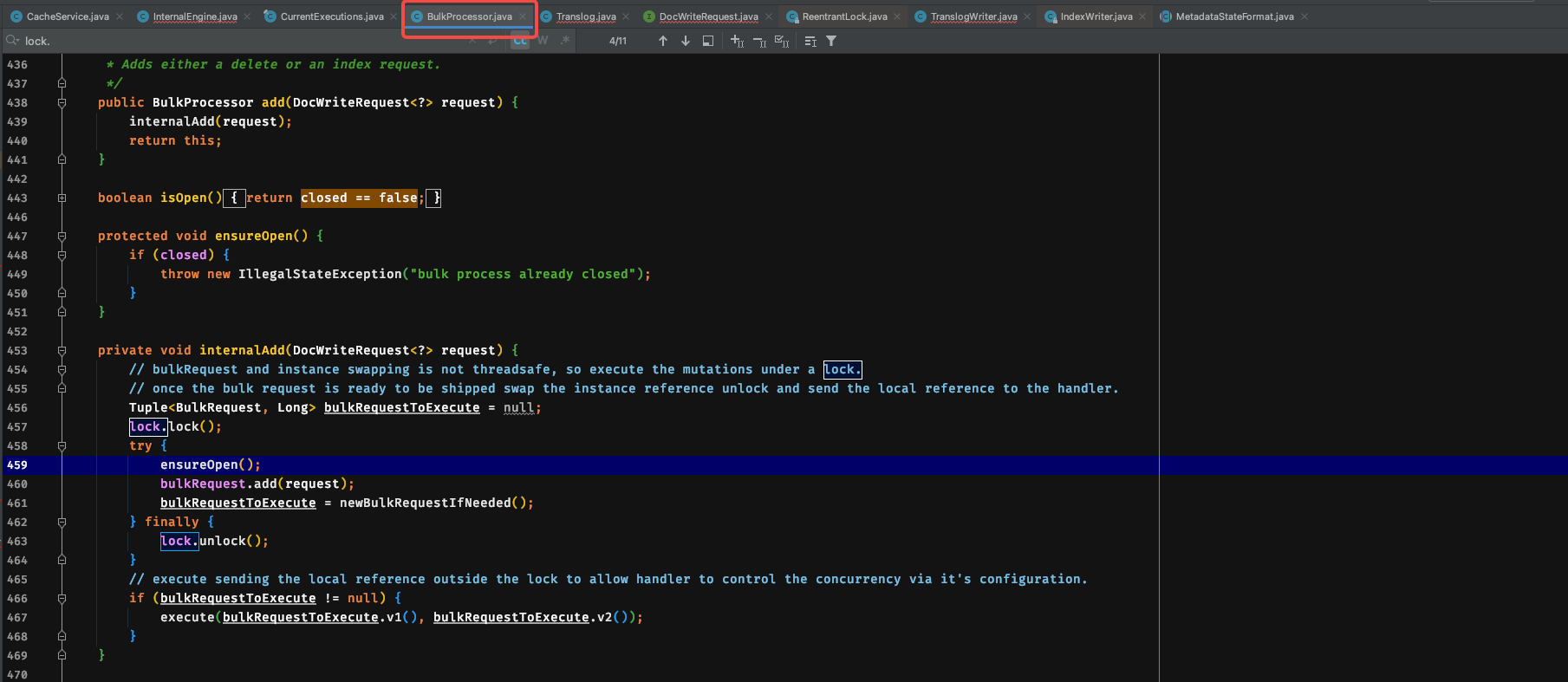
但是这个时候的写锁并不影响读,只是为了确保这一次请求被一个线程处理,这个时候用的是java的可重入锁
Put方式的写锁
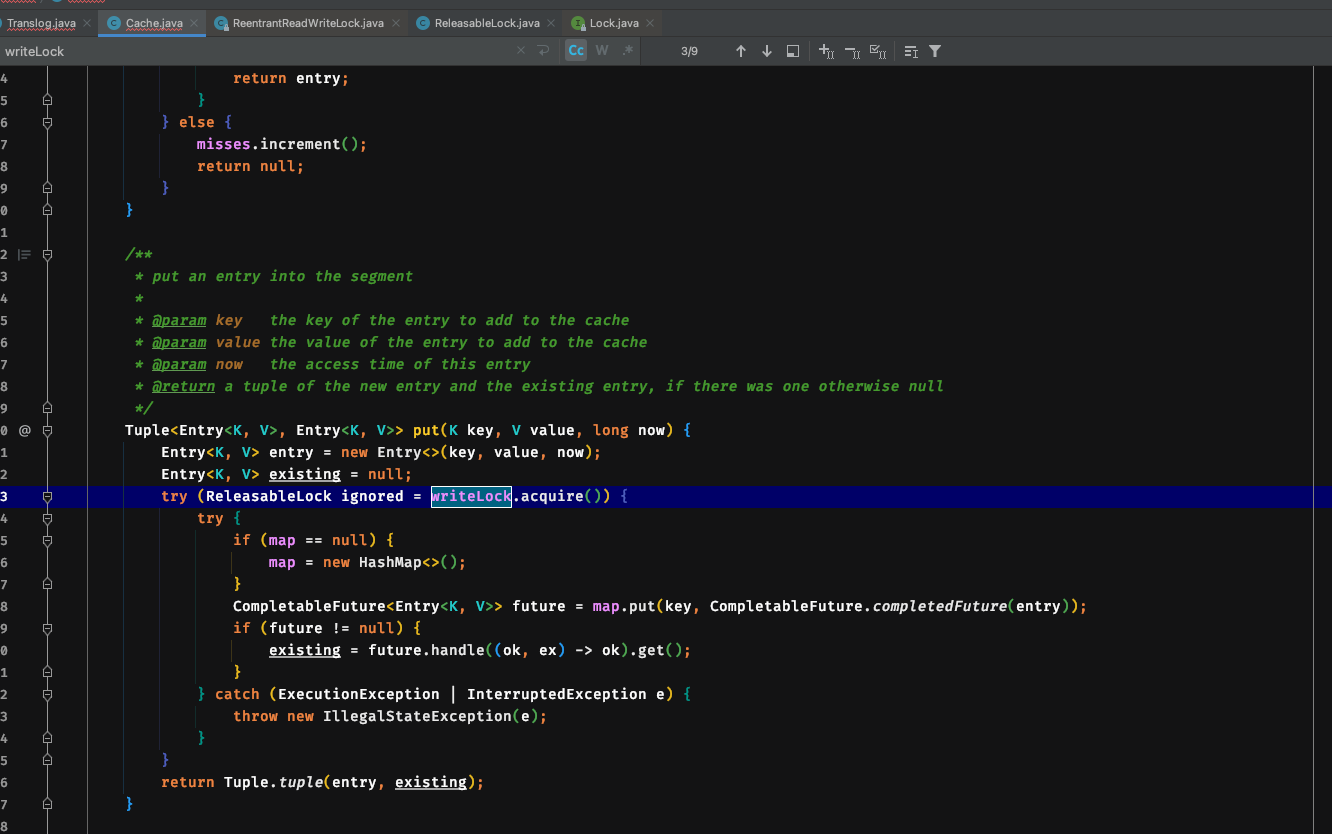
这里使用的是可重入读写锁,然后再初始化到Es自己的ReleasableLock中执行
Get方式读取数据读锁
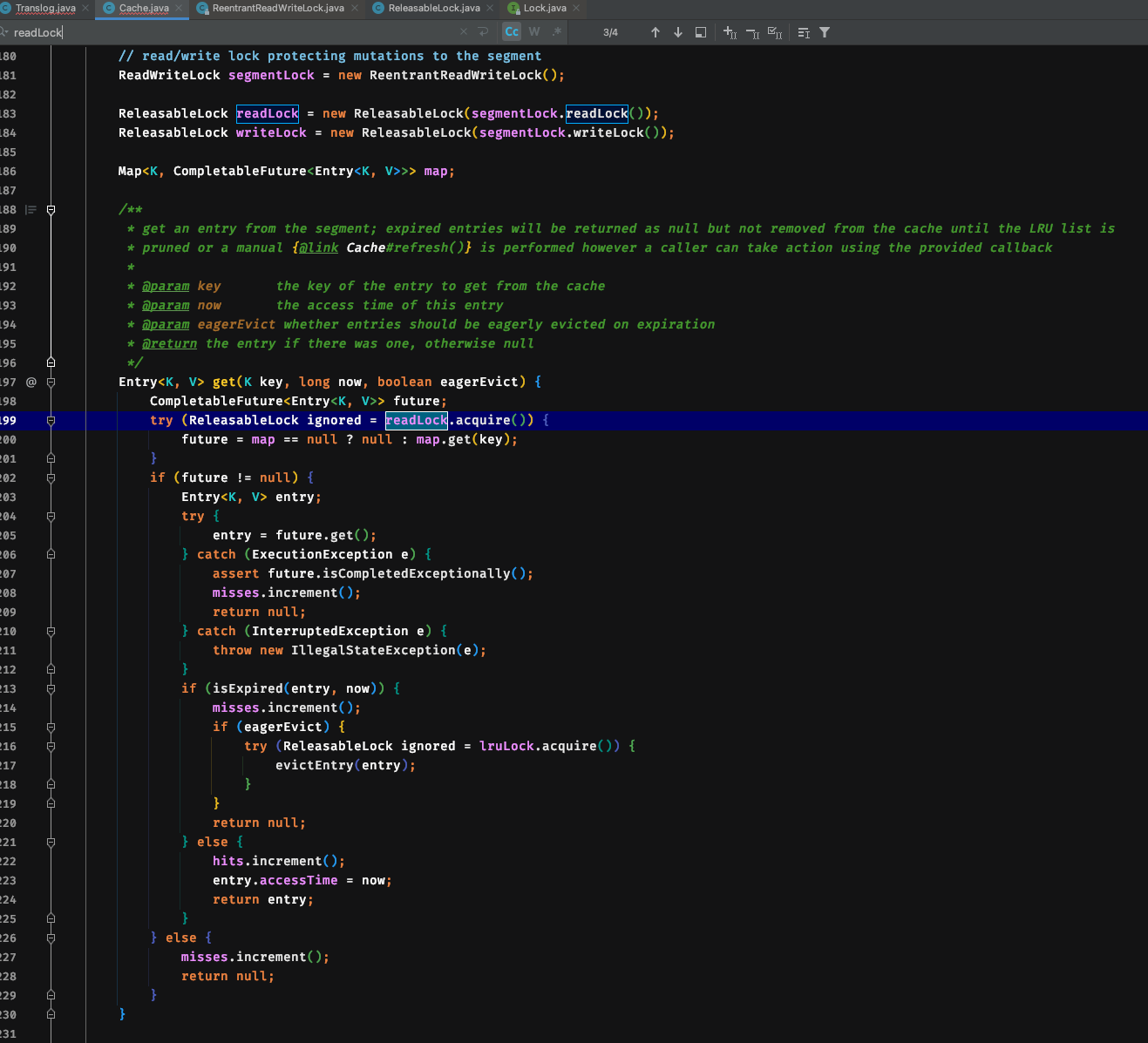
由于读和写使用的是ReentrantReadWriteLock进行加锁,那么读和写之间就是互斥的,所以主分片在写数据到Cache的时候高并发的写是会影响读的性能的,但是此时副分片节点的读不受影响,之后副分片节点也开始处理主分片同步过来的数据时那么副分片的读也会收到影响
数据写入顺序性怎么保证?
每一个写入的文档都有一个_version,每次修改会递增用来判断本次修改命令是执行还是丢弃
10亿数据导入到ES需要7个小时?
我们先看下写入过程:
副本节点越多写入时间越久,因为写入是串行的,主节点写入完成后会并发请求所有副本节点,会等到每一个副本节点响应后才会返回给协调者,无论副本节点是否成功都会等待每一个节点响应
如果没有任何优化的话差不多需要这个时间,如果你的场景是每天都会初始化一次那么多数据到ES的话,我们一定需要优化的,写入优化主要是几个方面:
异步刷盘
可以利用异步刷盘加速写入速度,只要丢失数据的风险是可接受范围就行了
index.translog.durability:async调整副本数
ES副本数过多的时候就会导致写入缓慢,看上面的流程应该比较清楚了,每次大数据量导入之前将副本节点数调整成0是加速写入最直接的办法
BULK批量写入
通过API一条条写入的话太慢了,ES是原生支持BULK批量方式操作
调整FLUSH
适当调整max_index_buffer_size大小,不要太频繁的flush,如果你的使用场景不需要数据太实时能被读到,那么适当放大这个值
调整FLUSH时间
调整REFUSH
ES在修改数据的时候并不是修改原数据,而是新增了一条数据然后将原数据打上了delete标记,这样做的好处就是不需要对同一条数据进行加锁,但是坏处就是数据碎片过多需要不定时merge,而merge过程中需要对被merge的数据块获取合并锁但是不影响读
那么如果要提高写入的性能,我们通常还可以调整segment块的大小避免太多碎片出现以及调整merge的时间
public void forceMerge(final boolean flush, int maxNumSegments, boolean onlyExpungeDeletes, final String forceMergeUUID)
throws EngineException, IOException {
if (onlyExpungeDeletes && maxNumSegments >= 0) {
throw new IllegalArgumentException("only_expunge_deletes and max_num_segments are mutually exclusive");}
//获取合并锁,但是没有抢占读锁
optimizeLock.lock();try {
ensureOpen();store.incRef(); // increment the ref just to ensure nobody closes the store while we optimize
try {
if (onlyExpungeDeletes) {
indexWriter.forceMergeDeletes(true /* blocks and waits for merges*/);} else if (maxNumSegments <= 0) {
indexWriter.maybeMerge();} else {
indexWriter.forceMerge(maxNumSegments, true /* blocks and waits for merges*/);this.forceMergeUUID = forceMergeUUID;}
if (flush) {
flush(false, true);// 这里会删除已经被打上delete标记的数据
refresh("force-merge");}
} finally {
store.decRef();}
} catch (AlreadyClosedException ex) {
//释放任何因为异常而未合并的segment
ensureOpen(ex);failOnTragicEvent(ex);throw ex;} catch (Exception e) {
try {
maybeFailEngine("force merge", e);} catch (Exception inner) {
e.addSuppressed(inner);}
throw e;} finally {
optimizeLock.unlock();}
}为什么我查询ES的RT已经偏高?
可能几种原因:
查询过于复杂,需要扫描的文档数过多
缓存命中率太低
分片节点数据不均匀,大量数据在一个节点
数据涉及分片过多
查询过于复杂,需要扫描的文档数过多
这个需要在设计数据结构的时候就避免出现,过于嵌套的结构会使后期查询缓慢,如果现在已经是这种结构了,那么可能最好的办法就是将查询语句拆分,分批去ES查询应用本地内存进行最终结果聚合
缓存命中率太低
ES内部其实是会对查询结果集进行缓存的,但是如果你的查询条件参数值都是now()等类型的数据,那么ES是无法缓存的,也就导致你的缓存命中率很低,完全没有用到Cache
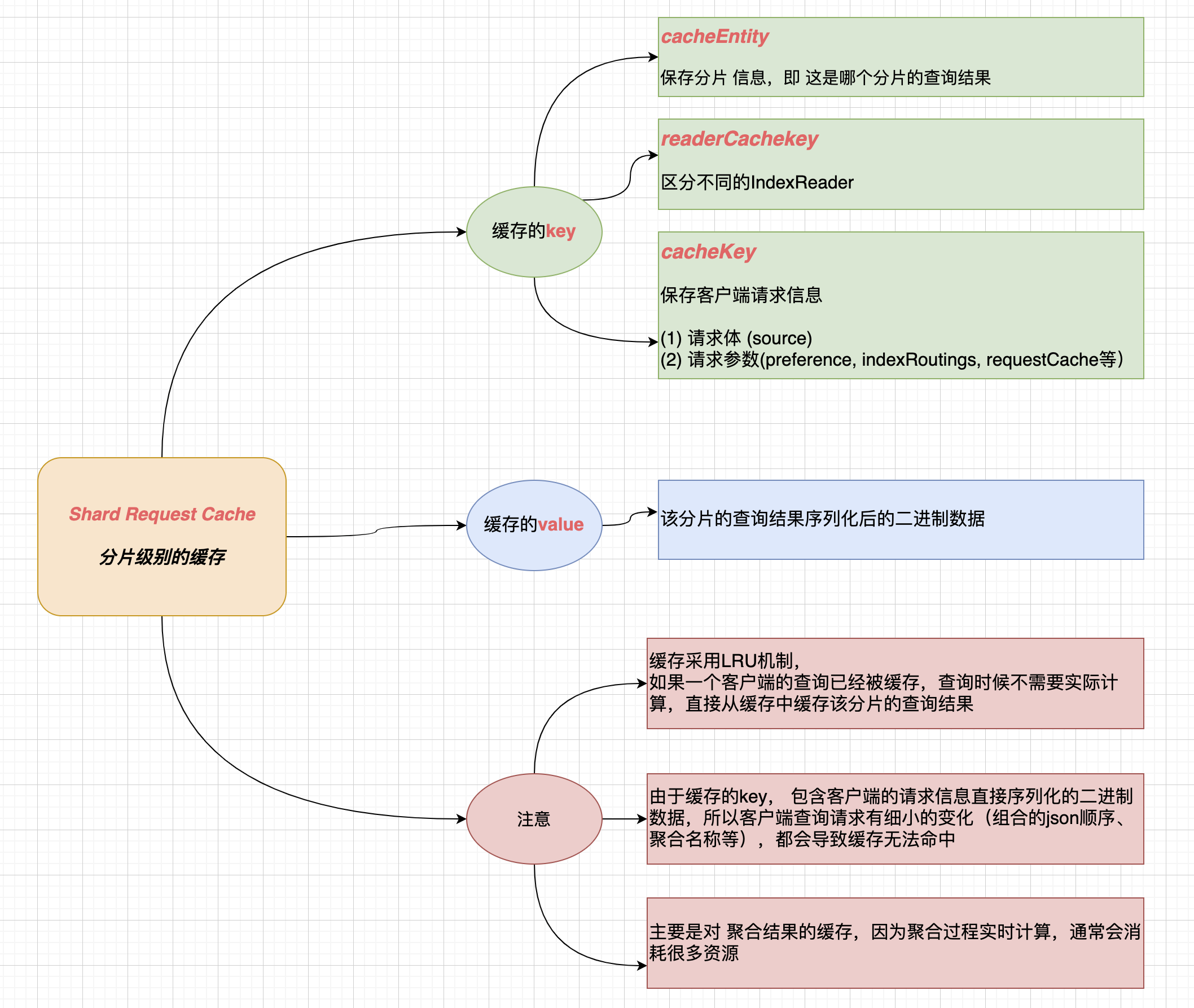
分片级别缓存的逻辑
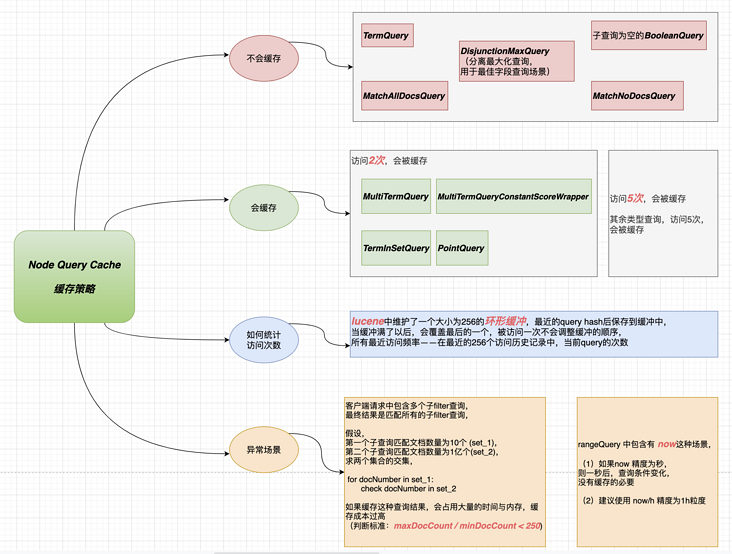
Node级别缓存的逻辑
ShardRequestCache是ES层级的实现,缓存机制为 LRU, 访问一次,就会考虑缓存,主要用途是对聚合结果进行缓存
NodeQueryCache是Lucene层级的实现,缓存机制为 LRU, 访问达到一定频率,才会考虑缓存,主要用途是对filter子查询的缓存
分片节点数据不均匀,大量数据在一个节点
这个如果采用ES原生的hash进行分片的话一般不会出现这个情况,主要是采用了自己的分片策略,这个时候大量请求都在一个节点那么查询性能肯定降低,最好的解决方案是重新Shard
数据涉及分片过多
节点接收到查询请求后,需要并发请求所有分片等待分片的查询结果返回,如果分片节点过多,那么这个场景势必会导致请求很慢,最好的处理方案是指定分片查询,这个就涉及数据写入的时候就设计好
预索引优化
还可以针对某些查询的模式来优化数据的索引方式。例如,如果所有文档都有一个price字段,并且大多数查询在一个固定的范围上运行range聚合,那么可以通过将范围“pre-indexing”到索引中并使用terms聚合来加快聚合速度,新增一个price_range字段,然后创建索引,查询的时候使用这个字段进行查询
我自己能查看哪些是慢查询嘛?
使用Profile API定位慢查询,这个API返回的统计纬度是按分片纬度统计的文章来源:https://uudwc.com/A/k3wB
ES集群状态为啥会显示Yellow或Red?
一个ES索引由多个分片组成,由于某些原因,某些分片可能会处于未分配状态(Unassigned),导致集群健康处于Yellow或Red状态,这是一种比较常见的错误信息,导致分片处于未分配的原因可能是节点离线、分片数量设置错误等原因,使用Explain API可以很容易分析当前的分片分配情况文章来源地址https://uudwc.com/A/k3wB
GET /_cluster/allocation/explain