模型迁移
手册地址:https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/600alpha002/ptmoddevg/ptmigr/ptmigr_000009.html
主要修改:
导入相关库
import torch
import torch_npu #1.8.1及以上需要
指定NPU设备
通过device()指定
原始代码:
device = torch.device('cuda:0')
torch.cuda.set_device(device)
修改为
device = torch.device('npu:0')
torch.npu.set_device(device)
torch.cuda
原始代码:
torch.cuda.xx()
tensor.to('cuda:0')
修改为
torch.npu.xx()
tensor.to('npu:0')
model.cuda
原始代码文章来源:https://uudwc.com/A/mJX4j
model = model.cuda()
修改为
model = model.npu()
损失函数
原始代码
cirterion = nn.CrossEntropyLoss().cuda()
修改后
cirterion = nn.CrossEntropyLoss().npu()
训练集
原始代码
device = torch.device('cuda:0')
images = images.to(device)
target = target.to(device)
修改后
device = torch.device('npu:0')
images = images.to(device)
target = target.to(device)
开启混合精度
APEX
基于NPU芯片的架构特性,会涉及到混合精度训练,即混合使用float16和float32数据类型的应用场景。使用float16代替float32有如下优点:
- 对于中间变量的内存占用更少,节省内存的使用。
- 因内存使用会减少,所以数据传出的时间也会相应减少。
- float16的计算单元可以提供更高的计算性能。
但是,混合精度训练受限于float16表达的精度范围,单纯将float32转换成float16会影响训练收敛情况。为了保证部分计算使用float16来进行加速的同时能保证训练收敛,这里采用混合精度模块APEX来达到以上效果。混合精度模块APEX是一个集优化性能、精度收敛于一身的综合优化库。
引入库
from apex import amp
初始化AMP
model, optimizer = amp.initialize(model, optimizer, combine_grad=True)
记反向传播.backward()发生的位置,这样AMP就可以进行Loss Scaling并清除每次迭代的状态
原始代码:
loss = criterion(…)
loss.backward()
optimizer.step()
修改后
loss = criterion(…)
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()
切换混合精度模式
model, optimizer = amp.initialize(model, optimizer, opt_level="O2") #配置功能模块参数opt_level
开关分布式训练性能
model, optimizer = amp.initialize(model, optimizer, combine_ddp=True) #配置运算加速参数combine_ddp
AMP
AMP功能在昇腾PyTorch1.8.1版本及以上可用,类似于APEX AMP的O1模式(动态 Loss Scale),也是通过将部分算子的输入转换为FP16类型来实现混合精度的训练。
使用场景
- 典型场景
- 梯度累加场景
- 多Models,Losses,and Optimizers场景
- DDP场景(one NPU per process)
NPU上使用方法
- 模型从GPU适配到NPU时,需要将代码torch.cuda.amp修改为torch_npu.npu.amp。
- 当前PyTorch1.8.1 AMP工具中GradScaler增加了dynamic选项(默认为True),设置为False时,AMP能支持静态Loss Scale。
profiling性能调优
文档地址:https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/600alpha002/developmenttools/devtool/atlasprofiling_16_0089.html
PyTorch Profiling
代码段:
# 使用ascend-pytorch适配的Profiling接口,即可获得,推荐只运行一个step
with torch.autograd.profiler.profile(use_npu=True) as prof:
out = model(input_tensor)loss=loss_func(out)
loss.backward()
optimizer.zero_grad()
optimizer.step()
# 打印Profiling结果信息
print(prof)
# 导出chrome_trace文件到指定路径
output_path = '/home/HwHiAiUser/profile_data.json'
prof.export_chrome_trace(output_path)
数据解析
查看profiling数据
在Chrome浏览器中输入“chrome://tracing”地址,将profile_data.json文件拖到空白处打开,通过键盘上的快捷键(w:放大,s:缩小,a:左移,d:右移)进行查看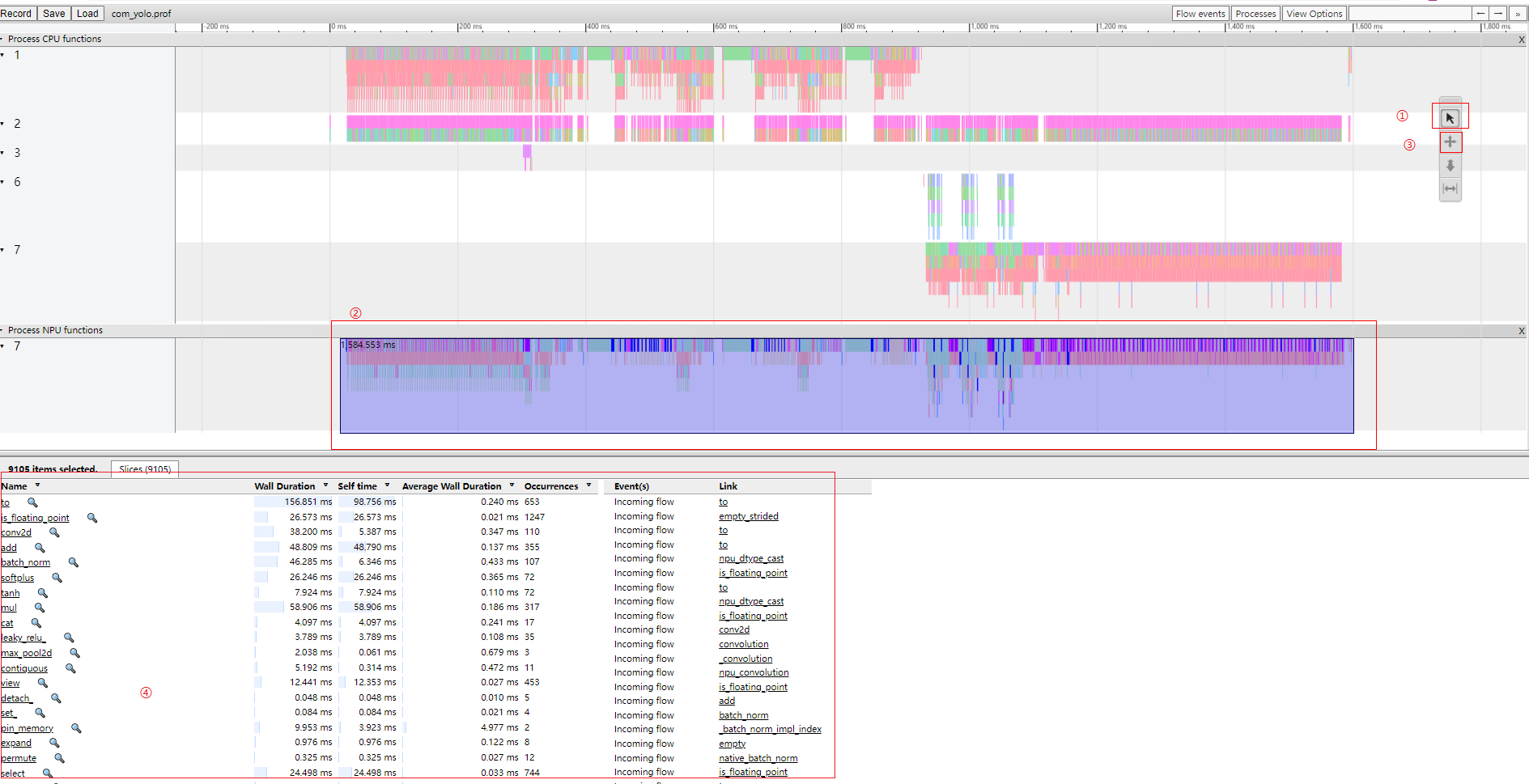
具体性能数据分析步骤如下:
- 单击图片中①所示按钮。
- 框选图片中②(用户所需数据)所示timeline数据。
- 单击图片中③所示按钮,详细数据信息如④所示。
- 根据④中selftime数据从大到小排序,可找出TopN耗时算子信息,分析模型中存在的性能问题。
其他功能
获取算子输入tensor的shape信息。
# 添加record_shapes参数,获取算子输入tensor的shape信息
with torch.autograd.profiler.profile(use_npu=True, record_shapes=True) as prof:
# 添加模型计算过程
print(prof)
获取使用NPU的内存信息。
# 添加Profiling参数,获取算子内存占用信息
with torch.autograd.profiler.profile(use_npu=True, profile_memory=True) as prof:
# 添加模型计算过程
print(prof)
获取简洁的算子性能信息
# 添加use_npu_simple参数,获取简洁的算子信息
with torch.autograd.profiler.profile(use_npu=True, use_npu_simple=True) as prof:
# 添加模型计算过程
output_path = '/home/HwHiAiUser/profile_data.json'
# 导出chrome_trace文件到指定路径
prof.export_chrome_trace(output_path)
CANN Profiling
代码段
cann_profiling_path = './cann_profiling'
if not os.path.exists(cann_profiling_path):
os.makedirs(cann_profiling_path)
with torch.npu.profile(cann_profiling_path):
out = model(input_tensor)
loss = loss_func(out,target)
loss.backward()
optimizer.zero_grad()
optimizer.step()
exit()
数据解析与导出参考手册:https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/600alpha002/developmenttools/devtool/atlasprofiling_16_0095.html
代码示例
原始代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
lr = 0.01 #学习率
momentum = 0.5
log_interval = 10 #跑多少次batch进行一次日志记录
epochs = 10
batch_size = 64
test_batch_size = 1000
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Sequential( # input_size=(1*28*28)
nn.Conv2d(1, 6, 5, 1, 2), # padding=2保证输入输出尺寸相同
nn.ReLU(), # input_size=(6*28*28)
nn.MaxPool2d(kernel_size=2, stride=2), # output_size=(6*14*14)
)
self.conv2 = nn.Sequential(
nn.Conv2d(6, 16, 5),
nn.ReLU(), # input_size=(16*10*10)
nn.MaxPool2d(2, 2) # output_size=(16*5*5)
)
self.fc1 = nn.Sequential(
nn.Linear(16 * 5 * 5, 120),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(120, 84),
nn.ReLU()
)
self.fc3 = nn.Linear(84, 10)
# 定义前向传播过程,输入为x
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
# nn.Linear()的输入输出都是维度为一的值,所以要把多维度的tensor展平成一维
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x #F.softmax(x, dim=1)
def train(epoch): # 定义每个epoch的训练细节
model.train() # 设置为trainning模式
for batch_idx, (data, target) in enumerate(train_loader):
data = data.to(device)
target = target.to(device)
data, target = Variable(data), Variable(target) # 把数据转换成Variable
optimizer.zero_grad() # 优化器梯度初始化为零
output = model(data) # 把数据输入网络并得到输出,即进行前向传播
loss = F.cross_entropy(output,target) #交叉熵损失函数
loss.backward() # 反向传播梯度
optimizer.step() # 结束一次前传+反传之后,更新参数
if batch_idx % log_interval == 0: # 准备打印相关信息
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test():
model.eval() # 设置为test模式
test_loss = 0 # 初始化测试损失值为0
correct = 0 # 初始化预测正确的数据个数为0
for data, target in test_loader:
data = data.to(device)
target = target.to(device)
data, target = Variable(data), Variable(target) #计算前要把变量变成Variable形式,因为这样子才有梯度
output = model(data)
test_loss += F.cross_entropy(output, target, size_average=False).item() # sum up batch loss 把所有loss值进行累加
pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum() # 对预测正确的数据个数进行累加
test_loss /= len(test_loader.dataset) # 因为把所有loss值进行过累加,所以最后要除以总得数据长度才得平均loss
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') #启用GPU
train_loader = torch.utils.data.DataLoader( # 加载训练数据
datasets.MNIST('./mnist_data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) #数据集给出的均值和标准差系数,每个数据集都不同的,都数据集提供方给出的
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader( # 加载训练数据,详细用法参考我的Pytorch打怪路(一)系列-(1)
datasets.MNIST('./mnist_data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) #数据集给出的均值和标准差系数,每个数据集都不同的,都数据集提供方给出的
])),
batch_size=test_batch_size, shuffle=True)
model = LeNet() # 实例化一个网络对象
model = model.to(device)
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum) # 初始化优化器
for epoch in range(1, epochs + 1): # 以epoch为单位进行循环
train(epoch)
test()
torch.save(model, 'model.pth') #保存模型
修改后代码文章来源地址https://uudwc.com/A/mJX4j
import torch
import torch_npu
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
import os
from apex import amp
lr = 0.01 #学习率
momentum = 0.5
log_interval = 10 #跑多少次batch进行一次日志记录
epochs = 1
batch_size = 64
test_batch_size = 1000
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Sequential( # input_size=(1*28*28)
nn.Conv2d(1, 6, 5, 1, 2), # padding=2保证输入输出尺寸相同
nn.ReLU(), # input_size=(6*28*28)
nn.MaxPool2d(kernel_size=2, stride=2), # output_size=(6*14*14)
)
self.conv2 = nn.Sequential(
nn.Conv2d(6, 16, 5),
nn.ReLU(), # input_size=(16*10*10)
nn.MaxPool2d(2, 2) # output_size=(16*5*5)
)
self.fc1 = nn.Sequential(
nn.Linear(16 * 5 * 5, 120),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(120, 84),
nn.ReLU()
)
self.fc3 = nn.Linear(84, 10)
# 定义前向传播过程,输入为x
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
# nn.Linear()的输入输出都是维度为一的值,所以要把多维度的tensor展平成一维
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x #F.softmax(x, dim=1)
def train(epoch): # 定义每个epoch的训练细节
model.train() # 设置为trainning模式
for batch_idx, (data, target) in enumerate(train_loader):
data = data.to(device)
target = target.to(device)
data, target = Variable(data), Variable(target) # 把数据转换成Variable
#optimizer.zero_grad() # 优化器梯度初始化为零
#output = model(data) # 把数据输入网络并得到输出,即进行前向传播
#loss = F.cross_entropy(output,target) #交叉熵损失函数
#loss.backward() # 反向传播梯度
#with amp.scale_loss(loss, optimizer) as scaled_loss:
# scaled_loss.backward()
#optimizer.step() # 结束一次前传+反传之后,更新参数
# pytorch_profiling代码段
with torch.autograd.profiler.profile(use_npu=True) as prof:
out = model(data)
loss = F.cross_entropy(out,target)
retain_graph=True
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.zero_grad()
optimizer.step()
# CANN profiling代码片段
cann_profiling_path = './cann_profiling'
if not os.path.exists(cann_profiling_path):
os.makedirs(cann_profiling_path)
with torch.npu.profile(cann_profiling_path):
out = model(data)
loss = F.cross_entropy(out,target)
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.zero_grad()
optimizer.step()
exit()
if batch_idx % log_interval == 0: # 准备打印相关信息
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 打印Profiling结果信息
#print(prof)
## 导出chrome_trace文件到指定路径
#output_path = './profile_data.json'
#prof.export_chrome_trace(output_path)
def test():
model.eval() # 设置为test模式
test_loss = 0 # 初始化测试损失值为0
correct = 0 # 初始化预测正确的数据个数为0
for data, target in test_loader:
data = data.to(device)
target = target.to(device)
data, target = Variable(data), Variable(target) #计算前要把变量变成Variable形式,因为这样子才有梯度
output = model(data)
test_loss += F.cross_entropy(output, target, size_average=False).item() # sum up batch loss 把所有loss值进行累加
pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum() # 对预测正确的数据个数进行累加
test_loss /= len(test_loader.dataset) # 因为把所有loss值进行过累加,所以最后要除以总得数据长度才得平均loss
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
if __name__ == '__main__':
#启用NPU
device = torch.device('npu:0')
torch.npu.set_device(device)
train_loader = torch.utils.data.DataLoader( # 加载训练数据
datasets.MNIST('./mnist_data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) #数据集给出的均值和标准差系数,每个数据集都不同的,都数据集提供方给出的
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader( # 加载训练数据,详细用法参考我的Pytorch打怪路(一)系列-(1)
datasets.MNIST('./mnist_data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) #数据集给出的均值和标准差系数,每个数据集都不同的,都数据集提供方给出的
])),
batch_size=test_batch_size, shuffle=True)
model = LeNet() # 实例化一个网络对象
model = model.to(device)
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum) # 初始化优化器
model, optimizer = amp.initialize(model, optimizer, combine_grad=True) #初始化amp
for epoch in range(1, epochs + 1): # 以epoch为单位进行循环
train(epoch)
test()
torch.save(model, 'model.pth') #保存模型
