前言:Hello大家好,我是Dream。 在当今数字时代,大型和实时的数据集具有更全面的信息、更准确的预测、和更好的竞争优势。作为一位刚被数据折磨过的人,我必须要把自己的经验跟大家分享一下,让大家和公司在收集数据方面少走一点弯路。
一、数据难收集成了当下的大问题
前段时间,Dream的一位朋友突然联系了我,自从那年毕业后,也就不再联系了,只知道她目前是一家头部出境电商公司的海外市场部经理,负责各大外网社交媒体上的KOL运营,这些媒体包括Ins,以及红遍全球的TikTok等,事业也正处在上升期,可最近却遇到了令她十分头痛的问题。 因为知道我是一名博主,认识的人和平台会多一点,想让我帮她出出主意。
通过和她简单的沟通,我了解她想要去找到TikTok以及Ins上面的红人。然而,每天数以亿计的视频在平台上上传和观看,用户数量也不断增长。要去找这些外网平台的KOL数据,除了需要代理IP网络,还需要技术团队去挖掘,数据庞大,挖掘和更新需要大量人力物力,她需要一种更高效的解决方案。
说到这,给大家科普一下数据的重要性。 在类似于TikTok的平台上,数据分析和抓住热门话题是提升签约博主视频利益的关键。通过数据分析和抓住热门话题,吸引更多的流量和市场份额,帮助公司实现更好的业绩和影响力。
二、靠谱的数据平台–亮数据
面对这个问题,她开始寻找解决方案。他咨询了同事、研究了市场上的不同工具和平台,但仍然没有找到满意的答案。她也是十分着急和担心,因为这对她来说是一次很好的升职机会,自己不想错过。看在当年的好朋友这么着急,Dream想起来那年的同窗时光,甚是感慨,于是下决心要帮助她把这件事情做好。
在寻找数据的过程中,我发现网上的大多数可以找的数据都存在着或多或小的问题,有的因为年代久远不具有实时性,而有的又不那么全面,并且满足不了我们自身的个性化需求。
于是,我联系了我认识的所有互联网公司,向他们请教经验和帮助,从他们口中我知道了亮数据平台。
听到这个消息,我心中顿时涌起了一丝希望。赶紧去网站注册和使用起来。
经过简单的操作,我发现此平台使用起来十分方便快捷!
登陆之后,我们直接选择查看数据产品,找到数据集商场,我惊喜的发现其中的数据集真的是又大又全面!在这里可以获取使用方便、结构化的、准确的公开网络Web 数据,于是我找到了我所需要的TikTok数据集。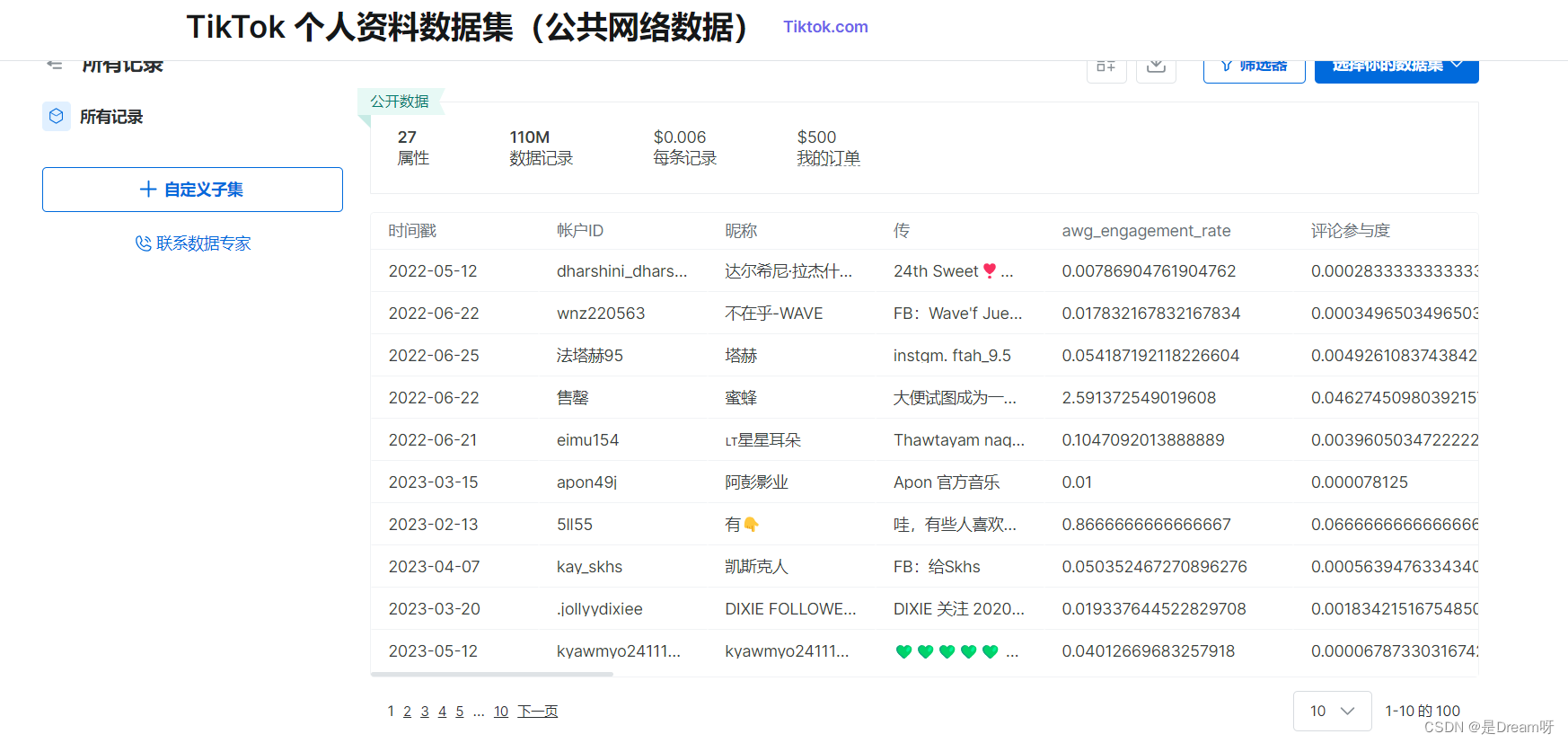
此数据集全面又实时,其中包含经过验证的个人资料、关注者、喜欢、创建日期等数据点。并且我可以给根据自己的需要,设置个性化的自定义子集!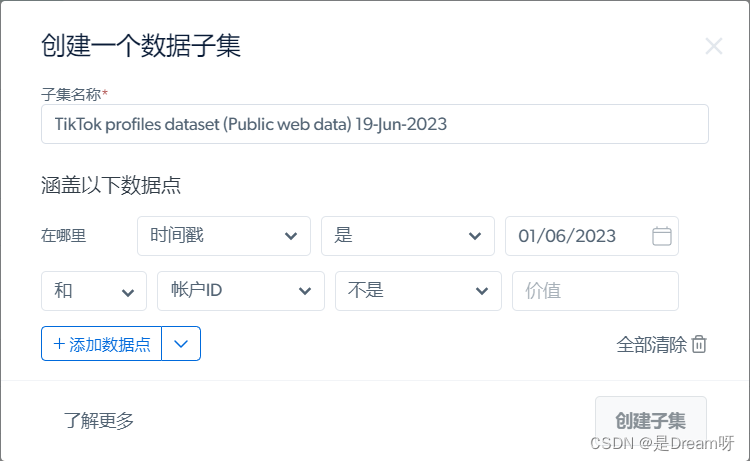
在这里我自定义了自己的数据集,我只选取了用户的id、视频种类type以及评论数comment,将数据集data保存在本地。
然后首先将保存在本地的data文件,进行一个简单的数据处理,剔除掉一些空白的数据(一些用户可能从来不评论视频):
import pandas as pd
# 读取Excel文件
df = pd.read_excel('data.xlsx')
# 数据清洗
df.dropna(subset=['id', 'type', 'comment'], inplace=True)
# 保存清洗后的结果
df.to_excel('cleaned_data.xlsx', index=False)
经过清洗完毕的数据,我们进行一个简单的可视化:
import pandas as pd
import matplotlib.pyplot as plt
# 读取Excel文件
df = pd.read_excel('cleaned_data.xlsx')
# 绘制关系图表
plt.scatter(df['type'], df['comment'])
plt.xlabel('Type')
plt.ylabel('Comment')
plt.title('Relationship between Type and Comment')
plt.show()
我们使用pd.read_excel()函数读取名为data.xlsx的Excel文件,并将其存储在一个名为df的DataFrame对象中。然后,我们使用plt.scatter()函数绘制散点图,其中df['type']表示x轴上的数据,df['comment']表示y轴上的数据。通过设置适当的x轴标签、y轴标签和标题,我们可以自定义图表的外观。最后,使用plt.show()函数显示图表。
使用散点图可以帮助观察type和comment之间的关系: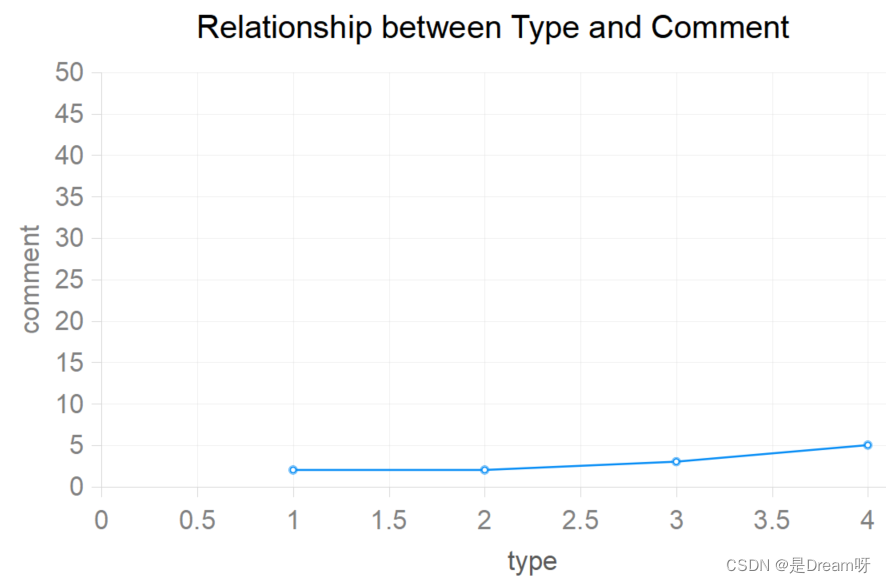
然后使用scikit-learn库进行文本预处理和线性回归建模:
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 读取Excel文件
df = pd.read_excel('data.xlsx')
# 特征工程
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(df['comment'])
y = df['type']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 模型训练
model = LinearRegression()
model.fit(X_train, y_train)
# 模型评估
score = model.score(X_test, y_test)
print("模型准确率:", score)
我们使用pd.read_excel()函数读取名为data.xlsx的Excel文件,并将其存储在一个名为df的DataFrame对象中。然后,我们使用CountVectorizer()进行文本预处理,将comment列转换为词频矩阵表示。接下来,我们将comment矩阵(X)作为输入变量,将type列(y)作为输出变量,使用train_test_split()函数划分训练集和测试集。最后,我们使用LinearRegression()模型进行训练,并使用score()函数计算模型的准确率。
最终,根据分布、相关性我们可以的得到一个非常有趣的结论,随着用户喜欢视频的种类的增加,我们发现用户评论的几率会更大(以100%为单位),并且看视频喜欢评论的人总是战比很少的一部分。这也充分说明了当用户看到一个喜欢的视频,只是会去点上一个喜欢,并不会去评论视频。
三、全面丰富且实时的数据集
在使用了亮数据平台之后,我快速准确地收集到了需要的数据,分析得到了我所需要的结果。每条数据仅需要0.006dollar,我采用了两万条数据,整个数据集大约花费了我120dollar,对比之下还是相当便宜的。
并且除了TikTok数据集外,几乎当下所有公开的数据集你都可以在其中找的,最重要的是这个数据集是最新的! 比如当下较为流行的来识别亚马逊美国的畅销产品和产品库存变化得Amazon数据集,每条数据记录仅需要0.0028dollar;以及获取新产品、类别、定价和消费者评论的完整快照的沃尔玛产品数据集和映射您的生态系统以进行战略业务决策和竞争分析的 Crunchbase 数据集,在这里都可以用低价获取到!可以说这是我们在任何地方都无法获取到的第一手信息,但是在这里我们便可以轻松实现。
帮完朋友,这个亮数据成功撩起了我的兴趣,各方面搜搜看看,发现这家公司原来是代理IP网络起家,境外IP十分强大,号称全球 195个国家,7200万IP覆盖! 然后还研发不少很牛的数据采集工具和软件,尝试了最新款的亮数据爬虫浏览器,十分新颖,可以说是市场上首款…这就解答了为什么他们的外网数据集这么好用的原因,人家自己有代理IP网络,自己有技术,这数据集不是水到渠成吗?
在这个数字时代,数据的力量是无可忽视的,掌握最新最全面的数据可以帮助我们在竞争激烈的市场中脱颖而出。因为我自己在收集数据方面走过弯路,所以我把自己的经验写下来传递给大家,希望大家可以更轻松的解决这个问题!
如果你和你的公司还在为数据烦恼的话,试试看!:亮数据----全球网络数据一站式平台
??? 好啦,这就是今天要分享给大家的全部内容了,我们下期再见!文章来源:https://uudwc.com/A/moRWW
本期推荐:
Windows PowerShell自动化运维大全文章来源地址https://uudwc.com/A/moRWW