我们收集和整理了常用的中文语音识别数据集,合计超过12000+小时的数据集。已经按照不同来源整理收录到
webhub123整理 中文语音识别数据集![]() https://www.webhub123.com/#/home/detail?projectHashid=64335220&ownerUserid=22053727
https://www.webhub123.com/#/home/detail?projectHashid=64335220&ownerUserid=22053727
整理后的效果如下

文章来源:https://uudwc.com/A/pjwGg
文章来源地址https://uudwc.com/A/pjwGg
每个卡片为一个网页,点击图片即可访问。登录后可一键全部保存到我的收藏,可以完全自由免费的管理和分享各种网站集合。同时还能发现他人分享的各类好网站。
个人网站收藏管理页面如下

每个数据集的详细介绍如下
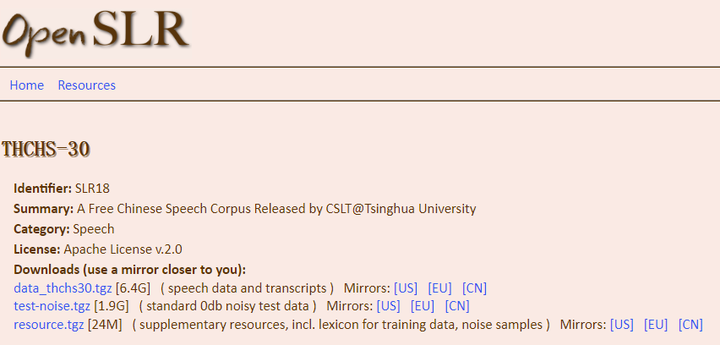
openslr.org 清华大学30小时中文语音库。THCHS-30是在安静的办公室环境下,通过单个碳粒麦克风录取的,总时长超过30个小时。大部分参与录音的人员是会说流利普通话的大学生。采样频率16kHz,采样大小16bits。THCHS-30的文本选取自大容量的新闻,目的是为了扩充863语音库。
希尔贝壳-专注于人工智能大数据和技术的创新 希尔贝壳中文普通话开源语音数据库AISHELL-ASR0009-OS1录音时长178小时,是希尔贝壳中文普通话语音数据库AISHELL-ASR0009的一部分。AISHELL-ASR0009录音文本涉及智能家居、无人驾驶、工业生产等11个领域。录制过程在安静室内环境中, 同时使用3种不同设备: 高保真麦克风(44.1kHz,16-bit);Android系统手机(16kHz,16-bit);iOS系统手机(16kHz,16-bit)。高保真麦克风录制的音频降采样为16kHz,用于制作AISHELL-ASR0009-OS1。400名来自中国不同口音区域的发言人参与录制。经过专业语音校对人员转写标注,并通过严格质量检验,此数据库文本正确率在95%以上。分为训练集、开发集、测试集。

openslr.org ST-CMDS是由一个AI数据公司发布的中文语音数据集,包含10万余条语音文件,大约100余小时的语音数据。数据内容以平时的网上语音聊天和智能语音控制语句为主,855个不同说话者,同时有男声和女声,适合多种场景下使用

openslr.org Primewords 免费的中文普通话语料库由上海普力信息技术有限公司发布。(上海元语信息科技)包含178个小时的数据。该语料由296名以中文为母语的人的智能手机录制。转录精度大于 98%,置信度为 95%。免费用于学术用途。转述和词句之间的映射以 JSON 格式提供。

数据堂开源1505小时中文语音数据 数据时长1505小时,是数据堂中文普通话语音数据库中的一部分。采集区域覆盖全国34个省级行政区域,参与录音人数达6408人,录音内容超30万条口语化句子。经过专业语音校对人员转写标注,并通过严格质量检验,句标注准确率达98%以上,是行业内句准确率的最高标准。(仅支持学术研究,未经允许禁止商用)

magicdata 开源语音数据集 1080个说话人755小时的手机录音语音数据

希尔贝壳-专注于人工智能大数据和技术的创新 希尔贝壳中文普通话语音数据库AISHELL-2的语音时长为1000小时,其中718小时来自AISHELL-ASR0009-[ZH-CN],282小时来自AISHELL-ASR0010-[ZH-CN]。录音文本涉及唤醒词、语音控制词、智能家居、无人驾驶、工业生产等12个领域。录制过程在安静室内环境中, 同时使用3种不同设备: 高保真麦克风(44.1kHz,16bit);Android系统手机(16kHz,16bit);iOS系统手机(16kHz,16bit)。AISHELL-2采用iOS系统手机录制的语音数据。1991名来自中国不同口音区域的发言人参与录制。经过专业语音校对人员转写标注,并通过严格质量检验,此数据库文本正确率在96%以上。(支持学术研究,未经允许禁止商用。)

Mozilla Common Voice Common Voice项目旨在创建开源语音识别数据集,当前链接为所有中文相关语音数据集。

ASRU2019中英混杂语音识别挑战赛-2019年IEEE自动语音识别与理解研讨会-数据堂 包括500小时中文训练集,和300小时中英文测试集。当前已经关闭注册,可能无法下载数据了

2021 IEEE SLT CSRC 2021SLT儿童语音识别挑战赛数据集,包含400小时儿童语音数据。但是可能无法下载到数据了,需要去openssl 找 或者给官方发邮件。

WenetSpeech 包含了10000+小时的普通话语音数据集,所有数据均来自 YouTube 和 Podcast。采用光学字符识别(OCR)和自动语音识别(ASR)技术分别标记每个YouTube和Podcast录音。为了提高语料库的质量,WenetSpeech使用了一种新颖的端到端标签错误检测方法来进一步验证和过滤数据。

WenetSpeech数据集的处理和使用_wenespeech数据_夜雨飘零1的博客-CSDN博客
GitHub - KeSpeech/KeSpeech: The repo provides information about KeSpeech dataset. KeSpeech包含了来自27237个说话人、34个中国城市、1542个小时的普通话+8种方言的数据,用来进行跨语言语音识别、预训练等任务。

ASR-RAMC-BigCCSC: A Chinese Conversational Speech Corpus Magic Data 于4月15日在 Magichub 开源社区正式开源用于本次比赛的180小时中文对话式语音数据集 MagicData-RAMC。作为高质量且标注丰富的训练数据,可以很好地支持开发者完成语音识别和说话人日志相关的研究。

MagicData-RAMC数据集测评 | 西北工业大学冠军队分享
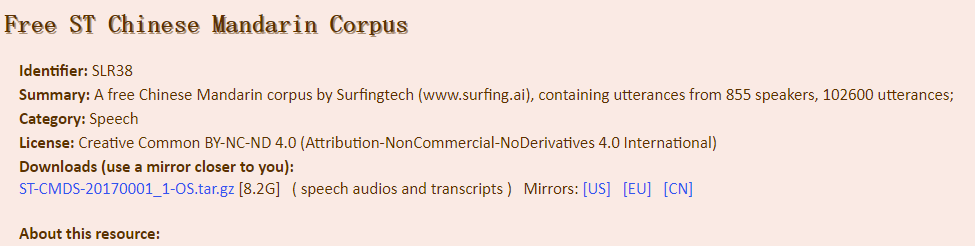
Free ST Chinese Mandarin Corpus 这个语料库是用手机在室内安静的环境中录制的。它有855个speakers。每个演讲者有120个话语。所有的话语都经过人仔细的转录和核对。保证转录精度。语料库包含: 1音频文件; 2转录; 3元数据;
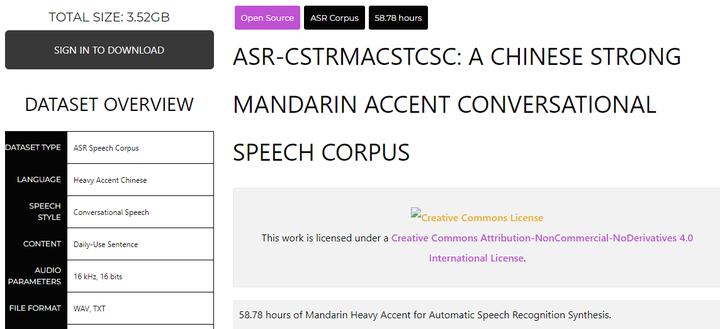
ASR-CStrMAcstCSC: A Chinese Strong Mandarin Accent Conversational Speech Corpus 58小时的中口音中文语音数据集