8.1 C++ 内联函数
内联函数是C++为了提高程序运行速度所做的一项改进。常规函数和内联函数之间的主要区别不在于编写方式,而在于C++的编译器如何把它们组织到程序中。想要知道C++是如何处理常规函数和内联函数,我们需要了解程序内部的工作过程。
编译过程的最重产品是可执行程序——由一组机器语言指令组成(把程序编译成让计算机看的懂的指令:机器码)。运行程序时,操作系统将这些指令载入到计算机内存中,因此每条指令都有特定的地址。计算机随后逐步执行这些指令。有时(遇到循环或者分支语句时),将跳过一些指令,向前或者向后跳到特定的地址。常规函数调用也使程序调到另一个函数的地址,并在函数结束时返回。(也就是说程序可能会打断当前执行的代码,而去执行其他的代码,等其他的代码执行完了,再回去执行之前打断的代码)
执行到函数调用指令时,程序将在函数调用后立刻存储改指令的内存地址,并将函数参数复制到堆栈(为此保存的内存块),跳到标记函数起点的内存单元,执行函数代码(也可能需要将返回值放到寄存器中),然后再跳回地址被保存的指令处。(现在执行A代码,在执行A代码时,调用了B代码,此时被调用的地址被保存到了一个内存空间,然后执行B代码,如果B代码有返回值,则返回值给A代码。执行完B代码再回到被调用的地址,继续执行A代码)
C++内联函数提供了另一种选择。内联函数的编译代码与其他程序代码“内联”起来了。也就是说,编译器将使用相应的函数代码替换了函数调用。对于内联代码,程序无需跳到另一个位置执行代码,再跳回来。因此,内联函数的运行速度比常规函数稍微快一点,当时代价就是要占用更多内存。如果程序在10个不同的地方调用一个内联函数,则该程序将包含该函数代码的10个副本。

C++内联函数只是提供了一种选择,应该选择性的使用内联函数,如果执行函数代码的时间比处理函数调用机制的时间长,则节省的时间将只占整个过程的很小一部分。如果代码执行之间很短,则内联调用就可以节省非内联调用使用的大部分时间。另一方面,由于这个过程相当快,因此尽管节省了该过程的大部分时间,但是节省的时间绝对值并不大,除非这个函数经常被调用。
要使用这项特性,必须采取下述措施之一:
---在函数声明前加上关键字inline;
---在函数定义前加上关键字inline。
通常的做法是省略原型,将整个定义(即函数头和所有函数代码)放在本应提供原型的地方。
程序员请求将函数作为内联函数时,编译器并不一定会满足这种要求。它可能让我函数过大或者注意到函数调用了自己(内联函数不能递归),因此不将此函数当做内联函数;而有些编译器没有启用或者实现这种特性。
#include <iostream>
using namespace std;
inline double square(double x){return x*x;}
int main()
{
double a,b;
double c = 13.0;
a = square(5.0);
b = square(4.5 + 7.5);
cout << "a = " << a << ", b = "<< b << endl;
cout << "c = " << c <<endl;
cout << "c square = " << square(c++) <<endl;
cout << "Now c = " << c <<endl;
return 0;
}
输出表明,内联函数和常规函数是一样的,也是按照值来传递参数的,如果参数为表达式,如4.5+7.5,则函数将传递表达式的值(此处为12)。这使C++的内联功能远远胜过C语音的宏定义。
尽管程序没有提供独立的原型,但是C++原型特性仍在起作用。这是因为在函数首次使用前出现的整个函数定义充当了原型。这意味着可以给square()传递int或者long值,将值传递给函数前,程序自动将这个值强制转换为double类型。
内联与宏
inline工具是C++新增的特性。C语言使用预处理器语句#define来提供宏——内联代码的原始实现。例如,下面方式一个计算平方的宏:
#define SQUARE(X) X*X;这并不是通过传递参数实现的,而是通过文本替换来实现的——X是“参数”的符号标记。
a = SQUARE(5.0);
//is replaced by a = 5.0*5.0;
b = SQUARE(4.5 + 7.5);
//is replaced by b = 4.5 + 7.5*4.5 + 7.5;
d = SQUARE(c++);
//is replaced by d = c++*c++;上述例子中只有第一个能正常工作。可以用括号来改进:
#define SQUARE(X) ((X)*(x))8.2 引用变量
C++新增了一种复合类型——引用变量。引用是已定义的变量的别名(就像给别人起了一个外号)。例如,如果将twain作为clement变量的引用,则可以交替使用twain和clement来表示该变量。
别名的主要用途是用作函数的形参。通过将引用变量作为参数,函数将使用原始数据,而不是其副本。这样除指针之外,引用也为函数处理大型结构提供了一种非常方便的途径,同时对于设计类来说,引用也是必不可少的。
8.2.1 创建引用变量
C和C++使用&符号来指示变量的地址。C++给&符号赋予了另一个含义,将其用来声明引用。例如,要将rodents作为rats变量的别名:
int rats;
int & rodents = rats;rats:老鼠
rodents:啮齿动物。
第二行代码使啮齿动物成为了老鼠的别名。
其中,&不是地址运算符,而是类型标识符的一部分。就像声明中的char*指向char的指针一样,int &指的是指向int的引用。上述引用声明允许将rats和rodents互换——它们指向相同的值和内存单元。
#include <iostream>
using namespace std;
int main()
{
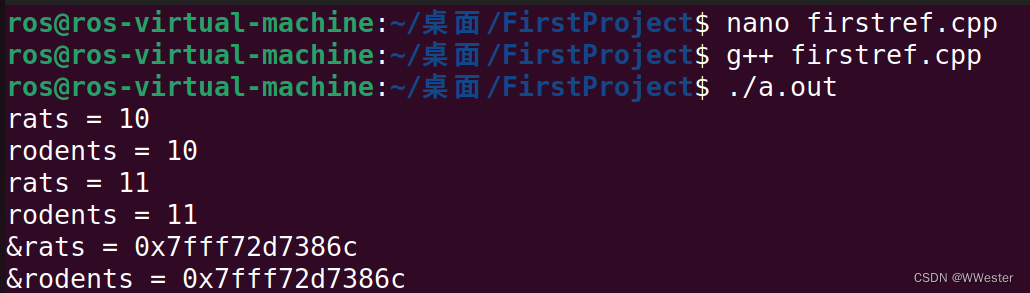
int rats = 10;
int & rodents = rats;
cout << "rats = " << rats << endl;
cout << "rodents = " << rodents << endl;
rodents++;
cout << "rats = " << rats << endl;
cout << "rodents = " << rodents << endl;
cout << "&rats = " << &rats << endl;
cout << "&rodents = " << &rodents << endl;
return 0;
}
第一次接触引用可能会有些困惑,因为有些人很自然地想到了指针,但是它们之间还是有区别的。例如,可以创建指向rats的引用和指针:
int rats = 101;
int & rodents = rats;
int * prats = &rats;表达式rodents和*prats都可以和rats互换,而表达式&rodents和prats都可以同&rats互换。从这点来看,引用很像指针的另一种用法(其中,*接触引用运算符被隐式理解)。但是实际上,引用还是不同于指针的。除了表示法不同外,还有其他的差别。例如,差别之一是,必须在声明引用时将其初始化,而不能像指针那样,先声明,再赋值:
int rat;
int & rodent;
rodent = rat;上述代码是错误的,必须在声明引用变量时进行初始化。
引用更接近const指针,必须在创建时进行初始化,一旦与某个变量关联起来,就将一直效忠于它。
int & rodents = rats;实际上是下述代码的伪装:
int * const pr = &rats;其中,引用rodents扮演的角色与表达式*pr相同。
#include <iostream>
using namespace std;
int main()
{
int rats = 101;
int & rodents = rats;
cout << "rats = " << rats << endl;
cout << "rodents = " << rodents << endl;
rodents++;
cout << "rats = " << rats << endl;
cout << "rodents = " << rodents << endl;
cout << "&rats = " << &rats << endl;
cout << "&rodents = " << &rodents << endl;
int bunnies = 50;
rodents = bunnies;
cout << "bunnies = " << bunnies << endl;
cout << "rodents = " << rodents << endl;
cout << "rats = " << rats << endl;
cout << "&bunnies = " << &bunnies << endl;
cout << "&rodents = " << &rodents << endl;
return 0;
}
最初,rodents引用的是rats,随后程序尝试把rodents作为bunnies的引用:
rodents = bunnies;但是可以发现rats和rodents的值变成了50,同时rats和rodents的地址是相同的,而其地址和bunnies的地址不同。也就是说,这个代码的意思是把bunnies变量的值赋值给了rat变量。所以我们知道,可以通过初始化声明来设置引用,但是不能通过赋值来设置。
8.2.2 将引用用作函数参数
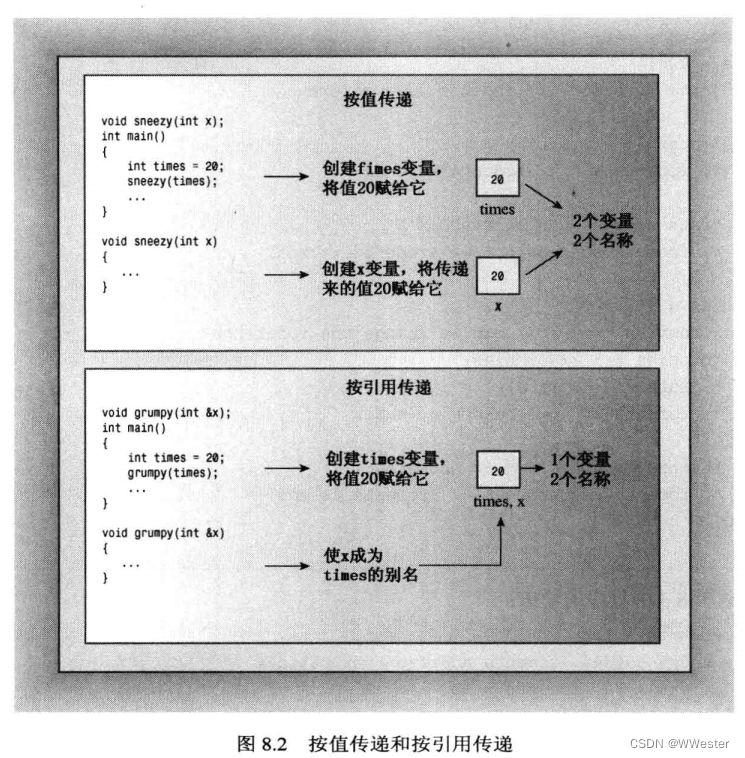
引用经常被用作函数参数,使得函数中的变量名成为调用程序中的变量别名(就是说,此时函数的形参和实参是同一个东西)。这种传递参数的方式称为 按引用传递 。按引用传递 允许被调用的函数访问调用函数中的变量(在函数的形参中去操作实参的别名(引用),就等于直接操作实参)。C++新增的这项特性是对C语言的超越,C语言除了指针传递的方式,只能按值传递。按值传递导致被调用函数使用调用程序的值的拷贝。
#include <iostream>
using namespace std;
void swapr(int &a,int &b);
void swapp(int *p,int *q);
void swapv(int a,int b);
int main()
{
int wallet1 = 300;
int wallet2 = 350;
cout << "wallet1 = " << wallet1 << endl;
cout << "wallet2 = " << wallet2 << endl;
cout << "Using references to swap contents:\n";
swapr(wallet1,wallet2);
cout << "wallet1 = " << wallet1 << endl;
cout << "wallet2 = " << wallet2 << endl;
cout << "Using pointers to swap contents again:\n";
swapp(&wallet1,&wallet2);
cout << "wallet1 = " << wallet1 << endl;
cout << "wallet2 = " << wallet2 << endl;
cout << "Tring to use passing by value:\n";
swapv(wallet1,wallet2);
cout << "wallet1 = " << wallet1 << endl;
cout << "wallet2 = " << wallet2 << endl;
return 0;
}
void swapr(int &a,int &b)
{
int temp;
temp = a;
a = b;
b= temp;
}
void swapp(int *p ,int *q)
{
int temp;
temp = *p;
*p = *q;
*q = temp;
}
void swapv(int a,int b)
{
int temp;
temp = a;
a = b;
b = temp;
} 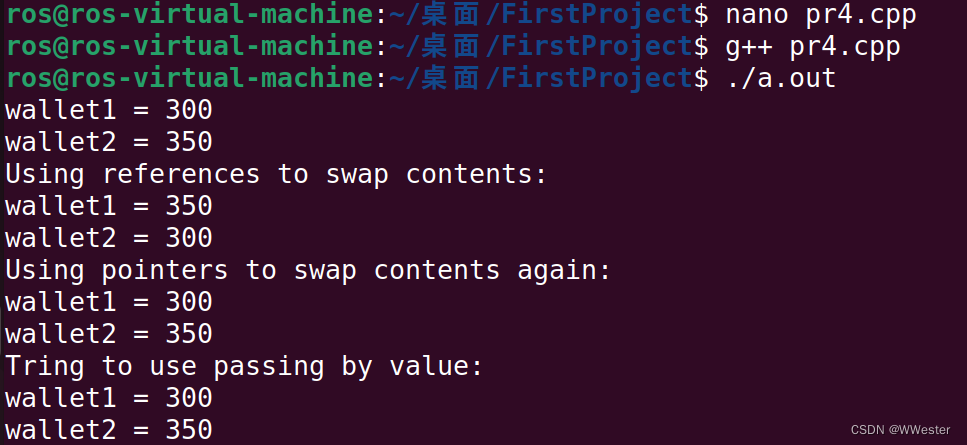
可以看到使用引用和指针的方式,wallet1和wallet2正确交换。
按引用传递(swapr()),按值传递(swapv()),按地址传递(sawpp())。
swapr(wallet1,wallet2);
swapv(wallet1,wallet2);其中swapr()和swapv()在使用的时候看起来相同。只能通过函数原型或者函数定义才能知道swapr()是按引用传递的。而地址运算符(&)使得按地址传递swapp(&wallet1,&wallet2)一目了然(类型声明int *p表明了,p是一个int指针,所以与p对应的参数应为地址)。
swapr()和swapv()的代码唯一的外在区别是声明函数参数的方式不同:
void swapr(int &a,int &b);
void swapv(int a,int b);swapr()和swapv()内在区别:
在swapr()中,变量a和b是wallet1和wallet2的别名,所以交换a和b等于交换 wallet1和wallet2;但是在swapv()中,变量a和b是复制了wallet1和wallet2的值的新变量,因此交换了a和b的值并不会影响wallet1和wallet2的值。
比较函数swapr()(传递引用)和swapp()(传递指针)。第一个区别是声明函数参数的方式不同:
void swapr(int & a,int & b);
void swapp(int * p,int & q);另一个区别是指针版本需要再函数使用p和q的整个过程中使用解引用运算符*。
应该在定义应用变量时对其进行初始化。函数调用使用实参初始化形参,因此函数的引用参数被初始化为函数调用传递的实参。也就是说,下面的函数调用将形参a和b分别初始化为wallet1和wallet2:
swapr(wallet1,wallet2);8.2.3 引用的属性和特别之处
使用引用参数时,需要了解一些特点。
#include <iostream>
double cube(double a);
double refcube(double &ra);
using namespace std;
int main()
{
using namespace std;
double x = 3.0;
cout << cube(x);
cout << " = cube of " << x << endl;
cout << refcube(x);
cout << " = cube of " << x << endl;
return 0;
}
double cube (double a)
{
a *= a*a;
return a;
}
double refcube (double &ra)
{
ra *= ra*ra;
return ra;
}
使用两个函数来计算参数的立方,其中一个函数接受double类型的参数,另一个接受double引用。
refcube()函数修改了main()中的x值,而cube()没有,这提醒我们为何通常按值传递。变量a位于cube()中,它被初始化为x的值,但是修改a并不会影响x。但由于refcube()使用了引用参数,因此修改ra实际上就是x。如果程序员的意图是让函数使用传递给它的信息,而不对这些信息进行修改,同时又想使用引用,则应该使用常量引用。例如,在这个例子中,在函数原型和函数头中使用const:
double refcube(const double &ra);如果这样写代码,那么但编译器发现代码修改了ra的值的时候,将生成错误消息。
如果要编写类似上述的函数(即使用基本数值类型),应该采用按值传递的方法,而不要采用按引用传递的方式。当数据比较大(如结构和类)时,引用参数将很有用。
按值传递的函数如上述的cube(),可以使用多种类型的实参。例如:
double z = cube(x + 2.0);
z = cube(8.0);
int k = 10;
z = cube(k);
double yo[3] = {2.2,3.3,4.4};
z = cube(yo[2]);如果将上面类似的参数传递给接受引用参数的函数,将会发现,传递引用的限制更严格,毕竟,如果ra是一个变量的别名,则实参应该是该变量。下面的代码会不合理,因为表达式x + 3.0不是变量:
double z = refcube(x + 3.0);例如,不能将值赋给表达式:
x + 3.0 = 5.0;如果试图使用像refcube(x + 3.0)这样的函数调用,在现代C++中,是错误的。大多数编译器都会指出这一点,然而有些老的编译器会发出这样的警告:
Warning:Temporary used for parameter 'ra' in call to refcube(double &)
之所以做出这种比较温和的反应是由于早期C++确实允许将表达式传递给引用变量。有些情况下,还是这么做的。
其结果如下:由于x+3.0不是double类型的变量,因此程序将创建一个临时的无名变量,并将其初始化为表达式x+3.0的值。然后,ra将成为该临时变量的引用。
临时变量,引用参数和const
如果实参与引用参数不匹配,C++将生成临时变量。当前,只有参数为const引用时,C++才允许这样做,但是以前不是这样的。
如果引用参数是const,则编译器将在下面两种情况下生成临时变量:
1.实参的类型正确,但不是左值。
2.实参的类型不正确,但是可以转换成正确的类型。
左值(左值参数):可以被引用的数据对象,例如,变量,数组元素,结构成员,引用和接触引用用的指针都是左值。
非左值:包括字面常量(用引号括起的字符串除外,它们由其地址表示)和包含多项的表达式。
在C语音中,左值最初指的是可以出现在赋值语句中左边的实体,但这是引入关键字const之前的情况。现在,常规变量和const变量都可以视为左值,因为可以通过地址访问它们。但常规变量属于可修改的左值,而const变量属于不可修改的左值。
Tips:如果函数调用的参数不是左值或与相应的const引用参数的类型不匹配,则C++将创建类型正确的匿名变量,将函数调用的参数的值传递给该匿名变量,并让参数来引用该变量。
尽可能使用const
将引用参数声明为常量数据的引用的理由有三个:
1.使用const可以避免无意中的修改数据的编程错误;
2.使用const使函数能够处理const和非const实参,否则将只能接受非const数据;
3.使用const引用使函数能够正确生成并使用临时变量。
因此,尽可能地将引用形参声明为const。文章来源:https://uudwc.com/A/pjwYP
------2023/9/21/23/11文章来源地址https://uudwc.com/A/pjwYP